10. API 参考¶
10.1. BPU API¶
10.1.1. 简介¶
为了方便利用 BPU 开发板提供的深度学习加速功能,我们开发了一套BPU API接口。在封装 BPU 提供的模块功能的同时,对开发者提供一套便于理解和使用的 API。
这套 API 分为两个部分,一个是针对执行深度学习模型的过程,封装了会使用到的接口;另一部分是相关的 IO 模块接口,比如 camera,pyramid 等。
BPU API 目前提供了四个头文件:
bpu_predict.h:提供模型运行所需要的接口声明
bpu_predict_entension.h:提供扩展的模型接口声明
bpu_io.h:提供 X2/J2 开发的 IO 模块接口声明
bpu_parse_utils.h:提供地平线特有的模型输出解析接口的声明
10.1.2. 深度学习模型相关接口¶
10.1.2.1. 相关数据结构¶
typedef void* BPUHandle
整个模型的 handle。所有跟 BPU 模型相关的操作通过这个 handle 来完成。
struct BPUModelInfo
模型信息数据结构,用来获取模型的输入、输出信息。
typedef void* BPU_Buffer_Handle
表示 BPU 相关操作需要的 buffer 对象。
typedef void* BPUPyramidBuffer
表示执行 BPU 金字塔操作后,返回的 buffer 对象。
struct BPUBBox
表示执行检测模型之后,解析输出得到的检测框信息。
typedef struct hb_BPU_MEMORY_S BPU_MEMORY_S
表示模型输入输出的memory结构体。
typedef enum hb_BPU_OP_TYPE_E BPU_OP_TYPE_E
表示模型输出op的类型枚举,目前仅列出卷积和其他op。
typedef enum hb_BPU_LAYOUT_E BPU_LAYOUT_E
表示模型输入输出的内存布局。
typedef enum hb_BPU_DATA_SHAPE_S BPU_DATA_SHAPE_S
表示模型输入输出的shape信息。
typedef enum hb_BPU_RUN_CTRL_S BPU_RUN_CTRL_S
表示模型运行时需要的控制结构体。
typedef enum hb_BPU_DATA_TYPE_E BPU_DATA_TYPE_E
描述各种数据类型的枚举,包括图像或者语音特征等。
typedef enum hb_BPU_MODEL_NODE_S BPU_MODEL_NODE_S
表示模型输入输出的节点信息。
typedef enum hb_BPU_MODEL_S BPU_MODEL_S
模型信息数据结构,用来获取模型的句柄以及输入输出节点信息。
typedef enum hb_BPU_TENSOR_S BPU_TENSOR_S
描述数据的类型,形状以及内存地址等信息。
typedef enum hb_BPU_GLOBAL_CONFIG_E BPU_GLOBAL_CONFIG_E
枚举了bpu api中可以设置的全局控制参数。
typedef enum hb_BPU_CONVERT_LAYOUT_METHOD_E BPU_CONVERT_LAYOUT_METHOD_E
表示转换内存布局的方法枚举。
typedef enum hb_BPU_RESIZE_CTRL_S BPU_RESIZE_CTRL_S
表示缩放图片需要的控制信息。
10.1.2.2. 全局设置接口¶
int HB_BPU_setGlobalConfig(BPU_GLOBAL_CONFIG_E config_key, const char *config_value)
通过key-value的方式配置全局控制信息,包含了最大任务数量,基于内存池的buffer数量以及debug模式等。
参数:
config_key:全局对象的枚举
config_value:设置全局对象的值
10.1.2.3. 模型加载的接口¶
模型加载接口主要是为了加载或释放编译器产出的模型文件。加载方式是显式调用 load 接口,这里先描述了两种显式调用 load 接口的方式。
int BPU_loadModel(const char* model_file_name, BPUHandle *handle, const char *bpu_config_file);
加载模型文件并返回一个 BPUHandle,这个 handle 是 void* 类型。
参数:
model_file_name:模型文件名称
handle:所加载模型的对象 handle
bpu_config_file:BPU API 使用的配置文件,JSON 格式
int BPU_release (BPUHandle handle);
释放 BPU Handle。这个函数通常在 APP 退出的时候调用,用于资源回收和释放。
int HB_BPU_loadModel(const void *model_data, int model_size, BPU_MODEL_S *model);
从一段内存中加载模型文件并返回一个 BPU_MODEL_S 结构体。BPU_MODEL_S结构体由外部传入,该函数直接往结构体中填入模型信息。
参数:
model_data:模型文件的起始地址
model_size:模型文件大小
model:返回的结构体里不仅包含了模型文件的handle,还有模型输入输出的节点信息
int HB_BPU_releaseModel(BPU_MODEL_S *model);
释放已经加载的模型。这个函数通常在模型不再被使用后调用,用于资源回收和释放。
10.1.2.4. 模型信息获取的接口¶
const char* BPU_getVersion(BPUHandle handle):
获取 BPU 模型的版本号。
int BPU_getModelNameList(BPUHandle handle, const char*** name_list, int *name_list_cnt):
获取模型文件中包含的所有模型 name。通常用户应该了解模型文件中的都是哪些模型,但是可能对具体 name 记不清楚,因此可以调用这个接口查看。后续调用其他 model 相关接口时,传入的 name,要求都是这个 name_list 中的某一个。
int BPU_getModelOutputInfo(BPUHandle handle, const char* model_name, BPUModelInfo *info):
获取 model 的 output 信息。包括 output 个数,output-shape, output-data-type。这个函数的主要作用在于,需要用户自己为 output-data 申请 buffer。因此,需要根据 output-shape,output-type 来确定 output-data buffer 需要的内存空间大小(详情参见 example 部分)。
const char *HB_BPU_getErrorName(int error_code)
用于返回 BPU 执行过程中的错误码信息,输入参数为所有BPU接口的返回值。
10.1.2.5. 模型执行接口¶
int BPU_runModelFromPyramid(BPUHandle handle, const char* model_name,
BPUPyramidBuffer input,
int pyr_level,
BPU_Buffer_Handle output[],
int nOutput,
BPUModelHandle *model_handle,
BPU_Buffer_Handle *extra_input = nullptr,
int extra_input_size = 0,
int core_id = -1);
针对从 pyramid 读取到的图片执行 model。
参数:
- handle
代表加载模型的 BPU handle。
- model_name
将要被执行的模型的名称。
- input
调用 BPU IO 接口中获取的 pyramid buffer。
- pyr_level
指的是用哪一层来执行模型。例如,0 表示使用原图,4 表示用1/2图。
- extra_input
多输入模型的额外输入。
- extra_input_size
多输入尺寸的额外输入。
- core_id
运行模型的 core ID。
关于 pyramid 详情,参见 Pyramid 接口。
- output
用于获取输出数据的 BPU_Buffer 数组指针,需要在调用函数之前首先创建出 BPU_Buffer。函数内部不会对 output 申请内存,output 内存由用户自己维护。
- nOutput
BPU_Buffer 数组中的元素数。必须等于模型输出数。
- model_handle
代表该运行环境的模型执行 handle。
返回值:
返回值为0,则表示执行成功。
返回值非0,则表示执行失败。可以调用 BPU_getLastError 获取错误信息。
这是个异步执行接口,会将执行任务添加至任务队列。该任务将由后台 engine 执行。所以当该接口返回,并不意味着模型执行已经完成。当返回时,设置 BPUModelHandle 变量,且当调用 BPU_getModelOutput 函数时,可以输入 BPUModelHandle 变量,等待模型执行完成,获取执行结果。
int BPU_getModelOutput(BPUHandle handle, BPUModelHandle model_handle);
获取模型执行结果。实际上结果会被写入到 BPU_runModelFromPyramid 提供的 output buffer 中。这个函数的意义在于等结果。也就是调用这个函数会 hang 住当前线程,直到模型执行完成,生成结果。在接口返回0后,output buffer 可以被访问。
int BPU_runModelCropPyramid(BPUHandle handle, const char *model_name,
BPUPyramidBuffer input,
int pyr_level,
int start_x,
int start_y,
BPU_Buffer_Handle output[],
int nOutput,
BPUModelHandle *model_handle,
BPU_Buffer_Handle *extra_input = nullptr,
int extra_input_size = 0,
int core_id = -1);
用于执行 ROI 检测。(start_x, start_y) 是 ROI 的左上顶点。
int BPU_releaseModelHandle(BPUHandle handle, BPUModelHandle model_handle);
释放模型 handle 信息。如果当前的 handle 正在等结果,则终止等待,释放所有相关资源。如果模型已经完成,则释放所有相关资源。
Note
release之后的 modelHandle 不能再被使用。
int BPU_runModelFromResizer(BPUHandle handle, const char* model_name,
BPUPyramidBuffer input,
BPUBBox *bbox,
int nBox,
int *resizable_cnt,
BPU_Buffer_Handle output[],
int nOutput,
BPUModelHandle *model_handle,
int core_id = -1);
该接口的使用方式跟 BPU_runModelFromPyramid 基本一样。这个函数的功能是对检测框的内容做进一步的识别。例如,在检测阶段识别了行人,可以在这个阶段再对行人的朝向进行识别。
参数:
- handle
和 BPU_runModelFromPyramid 相同。
- model_name
想要运行的模型名称。例如,行人朝向模型名称。
- input
和 BPU_runModelFromPyramid 相同。
- bbox
从检测阶段获取的检测框。
- nBox
检测框数量。
- resizable_cnt
可用于运行模型的框的数量。
由于硬件限制,并不是所有的检测框都能由 BPU 处理,所以,该参数用于告诉用户已经处理的框的数量。
当该接口返回,会设置 bbox 为 resizable。如果检测框可以处理,bbox->resizable 设置为 true,否则设置为 false。
- output
和 the BPU_runModelFromPyramid 相同。
- nOutput
和 BPU_runModelFromPyramid 相同。
- model_handle
和 BPU_runModelFromPyramid 相同。
int HB_BPU_runModel(const BPU_MODEL_S *model,
const BPU_TENSOR_S input_data[],
const int input_num,
const BPU_TENSOR_S output_data[],
const int output_num,
const BPU_RUN_CTRL_S *run_ctrl,
bool is_sync,
BPU_MODEL_HANDLE *task_handle);
上述的执行接口均为异步执行,而该接口可支持同步或异步两种运行模式。当处于同步方式时,调用该接口会阻塞当前线程,直到模型运行完成;当处于异步方式时,同BPU_runModelFromPyramid一样调用该接口在将任务加入队列后会立即返回,之后可以通过task_handle等待运行结束。
参数:
- model
包括模型的handle及输入输出信息。
- input_data
模型输入数据,包括了输入的类型,shape以及内存地址等信息。
- input_num
输入个数。
- output_data
模型输出数据,包括了输出的 shape 以及内存地址等信息。
- output_num
输出个数。
- run_ctrl
模型运行的控制信息,包括运行的 core id。
- is_sync
是否支持同步模式。
- task_handle
当前运行的任务handle,当处于同步方式时,可置为 nullptr,当处于异步方式时,可通过 task_handle 等待模型结束。
int HB_BPU_waitModelDone(BPU_MODEL_HANDLE *task_handle);
获取模型执行结果。和BPU_getModelOutput相同,实际上结果会被写入到 HB_BPU_runModel 的 output_data 中。这个函数的意义在于等结果。也就是调用这个函数会 hang 住当前线程,直到模型执行完成,生成结果。在接口返回0后,output_data 中的内存地址可以被访问。
int HB_BPU_releaseTask(BPU_MODEL_HANDLE *task_handle);
释放任务的 handle 信息。如果当前的任务正在等结果,则终止等待,释放所有相关资源。如果任务已经完成,则释放所有相关资源。
10.1.2.6. 模型结果解析接口¶
该函数用于解析模型输出op为RPP时的检测结果,会将检测结果保存在结构体 BPURppBBox 中。
int BPU_parseRPPResult(BPUHandle handle, const char *model_name, BPU_Buffer_Handle output[], int output_index, BPURppBBox *rpp_bbox);
BPU_convertLayout可用于对数据的内存布局进行多种方法的转换,枚举 BPULayoutType 列出了可支持的转换方法。
int BPU_convertLayout(BPUHandle handle, void *to_data, const void *from_data,
const char *model_name, BPULayoutType layout_type,
uint32_t layer_index, uint32_t n_index,
uint32_t h_index, uint32_t w_index, uint32_t c_index)
同BPU_convertLayout一样,HB_BPU_convertLayout也可用于对数据的内存布局进行多种方法的转换,枚举 BPU_CONVERT_LAYOUT_METHOD_E 列出了可支持的转换方法。
int HB_BPU_convertLayout(const BPU_MODEL_S *model, void *to_data,
const void *from_data,
BPU_CONVERT_LAYOUT_METHOD_E convert_method,
uint32_t output_index, uint32_t n_index,
uint32_t h_index, uint32_t w_index, uint32_t c_index)
10.1.2.7. BPU内存接口¶
Bernoulli架构中BPU和CPU共享同一块memory空间,这里单独提供针对BPU内存的接口是因为bpu需要使用物理空间连续的内存,因此需要用专门的函数申请和释放。
int HB_SYS_bpuMemAlloc(const char *name, size_t alloc_mem_size, bool cachable, BPU_MEMORY_S *mem)
该函数返回申请到的memory地址,并且内存可被设置是否cacheable,BPU_MEMORY_S 结构体中包括物理地址,虚拟地址以及内存大小。
int HB_SYS_flushMemCache(const BPU_MEMORY_S *mem, int flag)
对于申请为cacheable的内存,在对memory进行读写操作时需要调用此接口,避免memory中的数据未及时更新。
int HB_SYS_isMemCachable(const BPU_MEMORY_S *mem)
查询内存是否是cacheable的。
int HB_SYS_bpuMemFree(BPU_MEMORY_S *mem);
释放BPU内存。
10.1.2.8. BPU缩放接口¶
int HB_BPU_resize(const BPU_TENSOR_S *src, BPU_TENSOR_S *dest, const BPU_RESIZE_CTRL_S *ctrl_param);
对输入的数据做缩放,转成结构体dest中指定的大小,并存储到dest中,缩放结果是填充后的。
int HB_BPU_cropAndResize(const BPU_TENSOR_S *src, const BPU_ROI_S *input_roi, BPU_TENSOR_S *dest, const BPU_RESIZE_CTRL_S *ctrl_param);
对输入的数据指定roi做缩放,转成结构体dest中指定的大小,并存储到dest中,缩放结果是填充后的。
int HB_BPU_getResizeResultWithoutPadding(const BPU_MEMORY_S *src, BPU_MEMORY_S *dest, const BPU_DATA_SHAPE_S *shape);
得到去padding的缩放结果。
int HB_BPU_getImageAlignedShape(const BPU_DATA_SHAPE_S *shape, int *aligned_size)
由有效的输入shape得到填充后的对齐大小。
10.1.2.9. BPU_Buffer 结构¶
这个结构表示了BPU相关操作使用的内存 buffer。实际上是一个 handle。提供两个接口供用户获取实际可以访问的内存地址。
void* BPU_getRawBufferPtr(BPU_Buffer_Handle buff)
返回用户可以访问的内存地址。用户可以写入或者读取内存中的内容。
int BPU_getRawBufferSize(BPU_Buffer_Handle buff)
返回 buffer 的 size。告诉用户具体 buffer 大小,防止出现非法内存访问。
BPU_Buffer_Handle BPU_createBPUBuffer(void *buff, int size)
对用户传入的 buffer,创建一个同样大小的 BPU buffer。
int BPU_freeBPUBuffer(BPU_Buffer_Handle buff)
释放申请的 buffer。
10.1.2.10. Pyramid 接口¶
BPU 提供了硬件实现图像金字塔的功能。可以对输入的一张图像做出不同 scale 的多张图像。这个功能主要是在后验证模型上,通过使用不同 scale 的图像,能够提升不同大小的检测框的识别精度。
在 X2/J2 芯片架构中,camera 采集的图像都要先通过 pyramid 处理之后,用户才能够拿到。因此,这里没有提供camera接口,只提供了pyramid接口。
typedef void* BPUPyramidHandle
int BPU_createPyramid(const char* vio_config_file_name, const char *camera_config-file_name, int cam_cfg_index, int port, BPUPyramidHandle *handle):
在使用 pyramid 模块之前,需要先创建对应的 handle。
参数:
- vio_config_file_name
指 IO 相关的配置文件路径。
- camera_config_file_name
指 camera 的配置文件路径。
- cam_cfg_index
指 camera 配置文件中的config编号。
- port
指对应编号config中的pord id。
- handle
代表 pyramid 模块的 handle。
int BPU_getPyramidResult(BPUPyramidHandle handle, BPUPyramidBuffer *buffer):
获取金字塔的结果。如果还没有图像进来,则会 hang 住当前线程,等待金字塔做完。
int BPU_releasePyramidResult(BPUPyramidHandle handle, BPUPyramidBuffer buffer):
释放金字塔返回的结果。由于 pyramid 内部申请了 result 的内存空间,如果不释放,会造成内存泄漏。而且,pyramid 内部空间有限制,持续不释放会导致内存超限,无法再返回结果。
int BPU_releasePyramid(BPUPyramidHandle handle):
释放金字塔模块占用的资源。释放之后不能再使用该 handle。
获取 pyramid 信息接口
由于 BPUPyramidBuffer 只是一个表示 pyramid 对象的 handle,并没有包含 camera frame 信息,用户也不能直接得到 frame 的数据。因此,这里提供了一些接口用于获得 frame 信息以及金字塔每一层的 buffer。
uint64_t BPU_getPyramidTimestamp(BPUPyramidBuffer buffer);
获取产生金字塔的图像 frame 对应的 timestamp。
int BPU_getPyramidFrameID(BPUPyramidBuffer buffer);
获取产生金字塔的原始图像的 frame ID。
为了支持获取金字塔每一层的 buffer,提供以下回调方式:
void BPU_processPyramidResult(BPUPyramidBuffer pyr_buffer, int pyr_level, BPU_pyramidCallBack cb, void *cb_data_ptr);
pyr_level 表示想要获取的金字塔的层 ID,函数内部会调用回调函数,把对应的那一层 buffer 传递给回调函数。
金字塔生成层的方式:根据 vio 配置文件中 pymid_ctrl_config 和 pymid_ds_config,可以控制金字塔生成的层数。其中,0层表示原始图像,4、8、12等4的倍数层分别是原始图像的1/2、1/4和1/8层。配置文件中的1、2、3、5、6、7等层是根据ROI做对应factor的scale。一般都是使用4的倍数层。
10.1.2.11. FakeImage接口¶
在 X2/J2 开发板中,camera 的输入一版为1080p或720p。但是,通常训练的深度学习模型的输入图片的清晰度都不是这么大。例如,分类模型是224x224,检测模型是416x416。为支持输入任意大小的图像,我们提供了 FakeImage 接口,用户可以使用该接口输入任意大小的图像在 BPU 上运行模型。
typedef void* BPUFakeImageHandle
定义一个 FakeImage 的 handle。每个 handle 可以用于表示一种大小的图片。
int BPU_createFakeImageHandle(int height, int width, BPUFakeImageHandle *handle);
创建 FakeImage 的 handle,其中 height 和 width 表示图片的大小。
BPUFakeImage *BPU_getFakeImage(BPUFakeImageHandle handle, uint8_t *yuv_nv12_ptr, int img_len);
用户需要自己传入一个 yuv nv12 格式的图像。然后,该函数会返回对应图像的 BPUFakeImage 结构,fake image 可以用来执行模型。img_len 表示 yuv_nv12_ptr 指向的图像 buffer 大小,要求跟创建 handle 使用的 height 和 width 相匹配(img_len == height * width * 3 / 2)。
int BPU_runModelFromImage(BPUHandle handle, const char *model_name, BPUFakeImage *input, BPU_Buffer_Handle output[], int nOutput, BPUModelHandle *model_handle, BPU_Buffer_Handle *extra_input = nullptr, int extra_input_size = 0, int core_id = -1);
输出 input 改成了 BPUFakeImage 指针之外,使用方式跟其他 runModel 函数一致。
int BPU_releaseFakeImage(BPUFakeImageHandle handle, BPUFakeImage *image_ptr);
释放 fake image 对象。要求使用完之后执行释放函数,否则会造成内存泄漏。
int BPU_releaseFakeImageHandle(BPUFakeImageHandle handle);
释放 FakeImage 的 handle。FakeImage 的 handle 可以针对不同大小的图像,创建多个 handle。
10.1.2.12. Feedback 接口¶
上文所述 FakeImage 接口不支持对 image 图像做金字塔。因此,不能跑需要做金字塔的模型。Feedback 接口利用系统硬件的金字塔功能,实现把用户输入的图像做金字塔,然后就可以对金字塔的结果来执行模型。
typedef void *BPUFeedbackHandle;
int BPU_createFeedback(const char *fb_config_file, BPUFeedbackHandle *handle);
创建 feedback 的 handle。其中,fb_config_file 是 feedback 的配置文件,主要是为了配置输入图像的大小和对应的 pyramid 的大小。类似于 vio 的 config 文件。
int BPU_getFeedbackResult(BPUFeedbackHandle handle, void *data_ptr, int data_len, BPUPyramidBuffer *pyr_buffer);
用户传入需要测试的图像 buffer 指针和图像大小,得到对应的金字塔结果 buffer。其中,图像要求是 yuv nv12 格式,data_len 要求和 config 文件中的图像大小匹配。目前仅支持1080p和720p的图像。
int BPU_releaseFeedbackResult(BPUFeedbackHandle handle, BPUPyramidBuffer pyr_buffer);
释放 pyramid buffer。pyramid buffer 占用了内部的内存资源,因此用完之后一定要释放,否则会造成内存泄漏。
int BPU_releaseFeedbackHandle(BPUFeedbackHandle handle);
释放 feedback handle。
10.1.2.13. BPU Group 接口¶
BPU Group 让用户能将一些模型放入其中,并通过该组进行管理。
int BPU_createGroup(BPUHandle handle);
创建 BPU Group 对象并返回 Group ID(大于0)。Group ID 0是默认组,因此无法创建 group ID 为0的组。
int BPU_setModelGroup(BPUHandle handle, const char* model_name, int group_id);
将模型设置到 group 中,默认所有的模型属于 group 0(ID为0 的group)。若想要将模型换至另一个 group,用另一个 group ID 调用该接口。若想要从 group 中移除模型,用group ID 0调用该接口。
int BPU_setGroupProportion(BPUHandle handle, int group_id, int proportion);
用 group ID 设置该组的 BPU 计算时间片的比例。比例为整数,真正比例 RP 是整个 BPU 计算时间的比例,因此将按 RP = proportion / 100计算。
如果该组有超过一个模型,该组所有的模型共享 group 比例。即,假定设置比例为50,group 中包括 model1、model2 和model3,则计算时间为 group 中所有模型的计算时间之和。
当把一个模型设置到一个group中,并对group设置了计算比例,该模型会按照该group的比例运行。如果该组的计算时间耗完,那么这个模型将会排列等候,直到当前组获得更多的计算时间。
10.1.2.14. BPUCNNBuffer接口¶
这套接口允许用户在应用层对输入进行自定义配置,其整体流程与Pyramid接口相同,唯一的区别是输入由用户构造,数据模拟金字塔结构。
struct BPUCNNBuffer;
BPUCNNBuffer *BPU_createBPUCNNBuffer(int width, int height,
int channel, size_t lv_cnt);
通过此接口创建BPUCNNBuffer结构。
int BPU_getHBMhandleFromBPUhandle(BPUHandle handle, uint64_t * hbm_handle);
通过此接口获取某层金字塔的地址,后续可对此地址做赋值等操作。
int BPU_runModelFromCNNBuffer(BPUHandle handle, const char* model_name,
BPUCNNBuffer *input_y,
BPUCNNBuffer *input_uv,
int pyr_level,
BPU_Buffer_Handle output[],
int nOutput,
BPUModelHandle *model_handle,
BPU_Buffer_Handle *extra_input = nullptr,
int extra_input_size = 0,
int core_id = -1);
通过此方法run pyramid,其余输入参数获取可参考Pyramid接口流程。
int BPU_runModelFromResizerBuffer(BPUHandle handle, const char* model_name,
BPUCNNBuffer *input_y,
BPUCNNBuffer *input_uv,
BPUBBox *bbox,
int nBox,
int *resizable_cnt,
BPU_Buffer_Handle output[],
int nOutput,
BPUModelHandle *model_handle,
int core_id = -1);
通过此方法run resizer 其余输入参数获取可参考Resizer流程。
int BPU_freeBPUCNNBuffer(BPUCNNBuffer *buff);
对BPUCNNBuffer释放。
10.1.3. 示例¶
以下基于 BPU API,做了一个代码使用示例,实现的功能是从 camera 采集图像,对图像执行检测模型,对输出进行解析以获取检测框,并在客户端做结果的展示。
具体示例代码,参见附件包中的程序。
10.1.3.1. 加载模型¶
const char *bpu_model = args.model_file.c_str();
BPUHandle bpu_handle;
int ret = BPU_loadModel(bpu_model, &bpu_handle);
if (ret != 0) {
std::cout << "here load bpu model failed: " << BPU_getLastError(bpu_handle) << std::endl;
return 1;
}
std::cout << "here load bpu model OK" << std::endl;
// get bpu version
const char *version = BPU_getVersion(bpu_handle);
if (version == nullptr) {
std::cout << "here get bpu version failed: " << BPU_getLastError(bpu_handle) << std::endl;
return 1;
}
std::cout << "here get bpu version: " << version << std::endl;
调用 load 函数加载模型,指定模型文件 (.hbm) 的路径,然后调用 BPU_getVersion 接口获取版本信息。
10.1.3.2. 获取模型信息¶
调用 getModelNameList 函数,获取模型文件中包含的所有模型的 name。
// get model names
const char **name_list;
int name_cnt;
ret = BPU_getModelNameList(bpu_handle, &name_list, &name_cnt);
if (ret != 0) {
std::cout << "here get name list failed: " << BPU_getLastError(bpu_handle) << std::endl;
return 1;
}
// print all name list
std::cout << "here get all name list: " << name_cnt << " list below: " << std::endl;
for (int i = 0; i < name_cnt; ++i) {
std::cout << name_list[i] << std::endl;
}
然后可以调用 BPU_getModelInputInfo 和 BPU_getModelOutputInfo 接口获取模型输入和输出信息。如下所示,获取信息后,输出模型的输入和输出 shape。
int ret = BPU_getModelInputInfo(bpu_handle, model_name, &output_info);
std::cout << "model: " << model_name << " input info: " << std::endl;
for (int i = 0; i < output_info.num; ++i) {
std::cout << "(";
for (int j = output_info.ndim_array[i]; j < output_info.ndim_array[i+1]; ++j) {
std::cout << output_info.valid_shape_array[j] << ",";
}
std::cout << ")" << std::endl;
}
ret = BPU_getModelOutputInfo(bpu_handle, model_name, &output_info);
if (ret != 0) {
std::cout << "get model: " << model_name << " output info failed: " << BPU_getLastError(bpu_handle) << std::endl;
return 1;
}
std::cout << "model: " << model_name << " has output: " << output_info.num << std::endl;
for (int i = 0; i < output_info.num; ++i) {
std::cout << "name: " << output_info.name_list[i] << ", shape: ";
std::cout << "(";
for (int j = output_info.ndim_array[i]; j < output_info.ndim_array[i+1]; ++j) {
std::cout << output_info.aligned_shape_array[j] << ",";
}
std::cout << ")" << std::endl;
int out_type_size = sizeof(int8_t);
if (output_info.dtype_array[i] == BPU_DTYPE_FLOAT32) {
out_type_size = sizeof(float);
}
std::cout << "output size: " << out_type_size << std::endl;
}
return output_info.num;
10.1.3.3. 创建 Pyramid¶
为了从 camera 采集图像,需要首先创建 pyramid 的 handle,需要两个参数文件:hb_vio.json 和 hb_camera.json。
BPUPyramidHandle pyr_handle;
// use pyramid
const char *vio_config = "./config/hb_vio.json";
const char *camera_config = "./config/hb_camera.json";
ret = BPU_createPyramid(vio_config, camera_config, 0, 0, &pyr_handle);
if (ret != 0) {
std::cout << "create pyramid failed" << std::endl;
return 1;
}
10.1.3.4. 创建打包和发送模块¶
图像检测的结果需要通过网路发送给 client 做展示。因此,需要创建 output-sender 对象发送结果至客户端:
OutputSender msg_sender;
ret = msg_sender.init("tcp://*:5560"); // set pubish port is 5560
if (ret != 0) {
std::cout << "create msg sender failed" << std::endl;
return -1;
}
10.1.3.5. 采集图像并执行检测模块¶
BPUPyramidBuffer pyr_buffer;
ret = BPU_getPyramidResult(pyr_handle, &pyr_buffer);
if (ret != 0) {
std::cout << "get pyramid result failed" << std::endl;
return 1;
}
frame.timestamp = BPU_getPyramidTimestamp(pyr_buffer);
frame.frame_id = BPU_getPyramidFrameID(pyr_buffer);
alloc_output_buffer(out_buf, out_num);
BPUModelHandle model_handle;
// run model
ret = BPU_runModelFromPyramid(bpu_handle, model_name, pyr_buffer, 0,
out_buf.data(), out_buf.size(),
&model_handle);
if (ret != 0) {
std::cout << "run model from pyramid failed" << std::endl;
return 1;
}
由于模型会在后台运行一段时间,因此,可以同时从pym buffer里面获取要展示的图像。
执行模型的工作是由后端引擎做的,这里是异步接口。因此,调用 BPU_processPyramidResult 函数并不影响模型的正常执行。
BPU_processPyramidResult(pyr_buffer, 0, dump_pyramid_image, pyr_img_ptr);
// wait for model run done, and get output
ret = BPU_getModelOutput(bpu_handle, model_handle);
if (ret != 0) {
std::cout << "here get model output failed: "
<< BPU_getLastError(bpu_handle);
return 1;
}
10.1.3.6. 解析结果¶
解析模型输出结果,得到检测框:
if (args.is_ssd) {
uint32_t num_layer = out_num/2;
SSDAux(bpu_handle, output_info, out_buf.data(), num_layer,
anchors_table, result_vec, 0.3, args.is_tf_model, false);
} else if (args.is_yolo) {
YoloAux(bpu_handle, output_info, model_name, out_buf.data(), 3, result_vec, 20, 0.3, 0.45,
args.is_tf_model, false);
检测模型的输出格式需要经过专门解析,ssd_aux 和 yolo_aux 用于解 SSD 和 YOLO 模型输出的结果。
10.1.3.7. 打包发送¶
对图像 frame 和检测结果进行序列化打包,这样才能发送给 client:
// serialize to pb
char *pb_buffer = nullptr;
int pb_buf_len;
ret = serialize(&frame, perception_data.data(), perception_data.size(), &pb_buffer, &pb_buf_len);
if (ret != 0) {
std::cout << "serialize to pb failed" << std::endl;
}
uint8_t* yuv_ptr = reinterpret_cast<uint8_t *>(pyr_img_ptr);
// send msg and wait send done
output_mq_sent = false;
ret = msg_sender.send_msg(pb_buffer, pb_buf_len, yuv_ptr, img_len, output_send_mq_cb);
if (ret != 0) {
free(pb_buffer);
pb_buffer = nullptr;
std::cout << "send msg failed" << std::endl;
}
// wait for msg send done.
if (!output_mq_sent) {
wait_output_sent();
}
打包发送完成之后,需要释放 frame。
// release
BPU_releasePyramidResult(pyr_handle, pyr_buffer);
10.1.3.8. 收尾工作¶
在程序退出之前,必须释放创建的各种 handle。
if (pyr_img_ptr != nullptr) {
free(pyr_img_ptr);
}
BPU_releasePyramid(pyr_handle);
BPU_release(bpu_handle);
检测效果:

BPU API 参见《MU-2020-1-C-X2J2平台系统软件接口手册》。
10.2. HBDK 运行时 API¶
10.2.1. 运行时概述¶
HBDK 运行时的目标是为用户提供低层次访问存储在 HBM 文件信息的接口,这些 HBM 文件是由 HBDK 工具链产生的。 HBDK 运行时为用户提供了以下功能:
加载 HBM 文件,其中可以包含多个模型
从加载的 HBM 文件中加载模型
为指定的模型创建运行实例
为指定的运行实例创建 Funccall
启动开始执行 Funccall
一旦指定模型的所有 Funccall 全部执行完,可以将运行输出结果从 BPU DRAM 的输出区拷贝到 CPU 的 DRAM
销毁指定模型的运行实例
卸载 HBM
下图展示了 HBDK 运行时的使用示例。
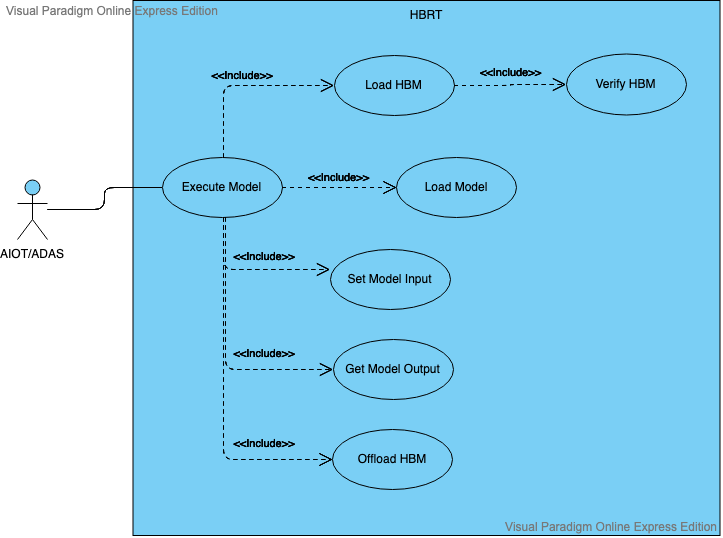
本小节的剩余部分会列出 HBDK 每个运行时函数接口的原型以及用法。
10.2.2. 加载/卸载/验证HBM¶
函数原型 |
hbrt_error_t hbrtLoadHBMFromAddr(hbrt_hbm_handle_t *hbm_handle, void *hbm_address, size_t hbm_byte_size) |
功能 |
从指定的 BPU 地址装载 HBM 文件 |
参数 |
[输出] hbm_handle: 要装载的 HBM 文件的句柄,可用于其它 API 获得模型信息的参数。 |
[输入] hbm_address: 指向 HBM 文件的地址。 |
|
[输入] hbm_byte_size: HBM 文件的大小(单位 Byte)。 |
|
说明 |
此函数在装载的时候,会检查 HBM 文件和 HBDK 运行时版本的兼容性。 |
函数原型 |
hbrt_error_t hbrtLoadHBMFromFile (hbrt_hbm_handle_t *hbm_handle, const char *hbm_path) |
功能 |
装载指定路径上的 HBM 文件 |
参数 |
[输出] hbm_handle: 要装载的 HBM 文件的句柄,可用于其它 API 获得模型信息的参数。 |
[输入] hbm_path: 要装载的 HBM 文件的路径。 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtOffloadHBM (const hbrt_hbm_handle_t *hbm_handle) |
功能 |
卸载 hbm_handle 指定的 HBM 文件 |
参数 |
[输入] hbm_handle: 要卸载的 HBM 文件的句柄. |
说明 |
用户必须显式销毁和此 HBM 文件中模型绑定的所有所有运行实例,否则将返回一个 hbrtErrorRiIsInUse 状态码。一旦 HBM 被卸载,其他 API 将不能访问此 HBM 文件中模型的任何信息。 |
函数原型 |
hbrt_error_t hbrtVerifyHBM(const void *hbm_address) |
功能 |
验证 HBM 文件的 CRC32 校验码 |
参数 |
[输入] hbm_address: 指向一个 HBM 二进制文件的地址. |
说明 |
在调用 hbrtLoadHBMFromAddr 之后会导致验证失败,因为 hbrtLoadHBMFromAddr 会将二进制文件中的一 些指针重定位。 |
10.2.3. 提取模型信息¶
函数原型 |
hbrt_error_t hbrtGetModelNumberInHBM(uint32_t *model_number, hbrt_hbm_handle_t hbm_handle) |
功能 |
提取HBM内部模型数量。 |
参数 |
[输出] model_number: 返回的模型数量。 |
[输入] hbm_handle: HBM句柄。 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetModelNamesInHBM(const char ***model_names, hbrt_hbm_handle_t hbm_handle) |
功能 |
通过HBM句柄读取内部所有模型的名称。 |
参数 |
[输出] model_names: 返回字符串型指针组包含所有的模型名称。 |
[输入] hbm_handle: HBM句柄。 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetModelHandle(hbrt_model_handle_t *model_handle, hbrt_hbm_handle_t hbm_handle, const char *model_name) |
功能 |
通过模型名称查询模型句柄。 |
参数 |
[输出] model_handle: 返回的模型句柄。 |
[输入] hbm_handle: HBM句柄。 |
|
[输入] model_name: 模型名称。 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetModelMarch(MARCH *march, hbrt_model_handle_t model_handle) |
功能 |
返回模型MARCH。 |
参数 |
[输出] march: 该模型的MARCH。 |
[输入] model_handle: 模型句柄。 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetModelCoreNumber(uint8_t *core_num, hbrt_model_handle_t model_handle) |
功能 |
返回模型执行需要的BPU核心数量。 |
参数 |
[输出] core_num: 模型执行需要的BPU核心数量。 |
[输入] model_handle: 模型句柄。 |
|
说明 |
模型执行需要的BPU核心数量在编译时被指定。双核模型必须占用两个BPU来完成计算。 |
函数原型 |
hbrt_error_t hbrtGetModelPeNumber(uint8_t *pe_num, hbrt_model_handle_t model_handle) |
功能 |
返回模型计算阵列数量。 |
参数 |
[输出] pe_num: 计算阵列数量。 |
[输入] model_handle: 模型句柄。 |
|
说明 |
模型执行需要的计算阵列数量在编译时被指定。双阵列模型必须占用两个计算阵列来完成计算。 |
函数原型 |
hbrt_error_t hbrtIsOneSegmentModel(bool *is_one_segment_model, hbrt_model_handle_t model_handle) |
功能 |
检查模型是否只包含单个网络片段。 |
参数 |
[输出] is_one_segment_model: 返回True,如果模型只包含单个网路片段。 |
[输入] model_handle: 模型句柄。 |
|
说明 |
无 |
10.2.4. 提取特征信息¶
函数原型 |
hbrt_error_t hbrtGetInputFeatureHandles(hbrt_feature_handle_t **feature_handle,hbrt_model_handle_t model_handle); |
功能 |
获得模型输入特征句柄 |
参数 |
[输出] feature_handle: 输入特征句柄 |
[输入] model_handle: 模型句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetInputFeatureNumber(uint32_t *input_number,hbrt_model_handle_t model_handle); |
功能 |
获得模型输入特征数目 |
参数 |
[输出] input_number: 输入特征数目指针 |
[输入] model_handle: 模型句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetOutputFeatureHandles(hbrt_feature_handle_t **feature_handle,hbrt_model_handle_t model_handle); |
功能 |
获得模型输出特征句柄 |
参数 |
[输出] feature_handle: 输出特征句柄 |
[输入] model_handle: 模型句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetOutputFeatureNumber(uint32_t *output_number,hbrt_model_handle_t model_handle); |
功能 |
获得模型输出特征数目 |
参数 |
[输出] output_number:模型输出数目指针 |
[输入] model_handle: 模型句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetOutputFeatureTotalSize(uint32_t *size,hbrt_model_handle_t model_handle); |
功能 |
获得指定输出特征大小 |
参数 |
[输出]size:输出特征大小 |
[输入] model_handle: 模型句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetFeatureName(const char **name,hbrt_feature_handle_t feature_handle); |
功能 |
获得指定特征句柄的特征名称 |
参数 |
[输出]name:特征名称 |
[输入]feature_handle:模型句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetFeatureAlignedDimension(hbrt_dimension_t *dim,hbrt_feature_handle_t feature_handle); |
功能 |
获得指定特征的对齐维度 |
参数 |
[输出]dim:特征各个维度对齐尺寸 |
[输入]feature_handle:模型句柄 |
|
说明 |
对齐BPU位宽,某些维度的特征可能加pad。此功能占用的字节大小应根据对齐尺寸计算获得。 |
函数原型 |
hbrt_error_t hbrtGetFeatureValidDimension(hbrt_dimension_t *dim,hbrt_feature_handle_t feature_handle); |
功能 |
获得指定特征的有效维度 |
参数 |
[输出]dim:特征各个维度真实尺寸 |
[输入]feature_handle:特征句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetFeatureAlignedTotalByteSize(uint32_t *size,hbrt_feature_handle_t feature_handle); |
功能 |
获得指定特征的对齐后总大小 |
参数 |
[输出]size:对齐后特征的所占内存的字节数 |
[输入]feature_handle:特征句柄 |
|
说明 |
此函数为指定特征返回(aligned dim *element type) |
函数原型 |
hbrt_error_t hbrtGetFeatureValidTotalByteSize(uint32_t *size,hbrt_feature_handle_t feature_handle); |
功能 |
获得指定特征的有效数据总大小 |
参数 |
[输出]size:特征有效数据所占内存的字节数 |
[输入]feature_handle:特征句柄 |
|
说明 |
此函数为指定特征返回(aligned dim *element type) |
函数原型 |
hbrt_error_t hbrtGetFeatureShiftValues(const uint8_t **shift, hbrt_feature_handle_t feature_handle); |
功能 |
获得指定特征的各个通道移位值 |
参数 |
[输出]shift:特征各个通道移位值 |
[输入]feature_handle:特征句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t GetFeatureShiftValueNumber(uint32_t *num,hbrt_feature_handle_t feature_handle); |
功能 |
获得指定特征的移位值的个数 |
参数 |
[输出]num:移位值的个数 |
[输入]feature_handle:特征句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetFeatureScaleValues(const float **scale, hbrt_feature_handle_t feature_handle) |
功能 |
获得指定特征的各个缩放值。 |
参数 |
[输出]shift:特征的图的缩放值。 |
[输入]feature_handle:特征句柄。 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetFeatureScaleValueNumber(uint32_t *num, hbrt_feature_handle_t feature_handle) |
功能 |
获得指定特征句柄的缩放值数量。 |
参数 |
[输出] num: 缩放值数量。 |
[输入] feature_handle: 特征句柄。 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetFeatureQuantiType(hbrt_feature_quanti_type_t *type, hbrt_feature_handle_t feature_handle) |
功能 |
获得特征量化类型。 |
参数 |
[输出] type:特征量化类型。 |
[输入] feature_handle:特征句柄。 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetFeatureElementType(hbrt_element_type_t *element_type,hbrt_feature_handle_t feature_handle); |
功能 |
获得指定特征的元素类型。 |
参数 |
[输出]element_type:特征的数据类型。 |
[输入]feature_handle:特征句柄 |
|
说明 |
1.检查可支持元素类型hbrt_element_type_t的定义 2.由于DetectionPostProcess和RCNNPostProcess有结构化输出,用户应使用对应结构解析输出,而非检查从这个API获取的元素类型。 更多细节请参见hbrt_type.h中对bernoulli_hw_detection_post_process_bbox_type_t,cpu_op_rcnn_post_process_bbox_float _type_t的定义。 |
函数原型 |
hbrt_error_t hbrtGetFeatureLayoutType(hbrt_layout_type_t *layout,hbrt_feature_handle_t feature_handle) |
功能 |
获得指定特征的数据排布 |
参数 |
[输出] layout: 特征的数据排布 |
[输入]feature_handle:特征句柄 |
|
说明 |
检查所支持数据排布hbrt_layout_type_t的定义。 |
函数原型 |
hbrt_error_t hbrtFeatureIsBigEndian(bool *isBigEndian,hbrt_feature_handle_t feature_handle); |
功能 |
判断指定特征是否是以大端存储 |
参数 |
[输出]isBigEndian:特征是否是以大端存储 |
[输入]feature_handle:特征句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetInputFeatureSource(hbrt_input_source_t *input_source,hbrt_feature_handle_t feature_handle) |
功能 |
获得指定特征的输入特征源 |
参数 |
[输出]input_source:特征的输入源 |
[输入]feature_handle:特征句柄 |
|
说明 |
无输入特征句柄的输入源将返回INPUT_FROM_DDR |
函数原型 |
hbrt_error_t hbrtGetInputSourceName(const char **name,hbrt_input_source_t source); |
功能 |
获得特征输入源字符串描述 |
参数 |
[输出]name:特征输入源字符串描述 |
[输入] source: 输入源的枚举值 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtGetInputPyramidStride(uint32_t *stride,hbrt_feature_handle_t feature_handle) |
功能 |
获得指定特征句柄的金字塔跨越值 |
参数 |
[输出]stride:特征的金字塔跨越值 |
[输入]feature_handle:特征句柄 |
|
说明 |
如用户通过非金字塔特征句柄则此函数返回hbrtInvalidFeatureHandle。 |
函数原型 |
hbrt_error_t hbrtGetFeatureOperatorType(hbrt_output_operator_type_t *type,hbrt_feature_handle_t feature_handle) |
功能 |
获得指定特征句柄的算子 |
参数 |
[输出]type:特征来源的算子类型 |
[输入]feature_handle:特征句柄 |
|
说明 |
1.对于如RCNNPostProcess和DetectionPostProcess类算子将以相应格式输出。更多细节详请参见hbrt_type.h中对 bernoulli_hw_detection_post_process_bbox_type_t, cpu_op_rcnn_post_process_bbox_float_type_t的定义。 2.对其它类型特征都会有包括OUTPUT_BY_UNKNOWN的输出算子。 |
10.2.5. 执行模型¶
函数原型 |
hbrt_error_t hbrtRiStart(void **p_funccall_buffer, uint32_t *generated_funccall_num, hbrt_model_handle_t model_handle, const hbrt_ri_input_info_t *input_infos, const hbrt_ri_config_t *ri_config, uint32_t ri_id, uint32_t interrupt_number |
功能 |
为执行模型推理生成 BPU Funccall |
参数 |
[输出] p_funccall_buffer: 生成的 Funccall 将会写到这个指针所指地址处 |
[输出] generated_funccall_number: 生成的 Funccall 数目 |
|
[输入] model_handle: 要运行模型的句柄 |
|
[输入] input_infos: 模型的输入信息 |
|
[输入] ri_config: 此运行实例的配置 |
|
[输入] ri_id: 此运行实例的 id |
|
[输入] interrupt_number: 指定最后一个 Funccall 运行完后产生的中断号 |
|
说明 |
1.有效的运行实例 id 范围为 0 到 MAX_RI_NUMBER。 MAX_RI_NUMBER 是一个在头文件 hbdk_hbrt.h 中定义的宏, 2.有效的终端号为 0 到 4095, 3.返回的 Funccall buffer 将会被 HBDK 运行时管理,用户代码不应尝试释放此 buffer。 |
函数原型 |
hbrt_error_t hbrtRiBatchStart(void **p_funccall_buffer, uint32_t *generated_funccall_num, hbrt_model_handle_t model_handle, const hbrt_ri_input_info_t **model_input_infos, const uint32_t *model_input_batch_size,const hbrt_ri_config_t *ri_config, uint32_t ri_id, uint32_t interrupt_number) |
功能 |
为一批输入数据执行模型推理生成 BPU Funccall |
参数 |
[输出] p_funccall_buffer: 生成的 Funccall 将会写到这个指针所指地址处 |
[输出] generated_funccall_number: 生成的 Funccall 数目 |
|
[输入] model_handle: 要运行模型的句柄 |
|
[输入] model_input_infos: 指向一个批处理数据输入信息的辅助指针。第一维遍历模型输入数目,第二维遍历此输入的批处理大小 |
|
[输入] model_input_batch_size: 指向批处理大小数组的指针。所有模型输入的批大小应为1或等于相同的数量 |
|
[输入] ri_config: 此运行实例的配置 |
|
[输入] ri_id: 此运行实例的 id |
|
[输入] interrupt_number: 指定最后一个 Funccall 运行完后产生的中断号 |
|
说明 |
对于多输入模型,可以通过将相应的输入批处理大小设置为1来广播某些输入。只有 cpu-operator-free 的模型可以用此 API 启动 |
函数原型 |
hbrt_error_t hbrtRiContinue(void **funccall_buffer, uint32_t *generated_funccall_num, uint32_t ri_id, uint32_t interrupt_number) |
功能 |
在需要时,在 CPU 上执行一部分模型。同时为剩余的层生成 Funccall |
参数 |
[输出] p_funccall_buffer: 生成的 Funccall 将会写到这个指针所指地址处 |
[输出] generated_funccall_number: 生成的 Funccall 数目 |
|
[输入] ri_id: 此运行实例的 id |
|
[输入] interrupt_number: 指定最后一个 Funccall 运行完后产生的中断号 |
|
说明 |
此函数的时间消耗可能是从几微秒到数十毫秒不等。 我们建议建立一个 pipeline,以使此函数与 BPU Funccall 的执行并行。 |
函数原型 |
hbrt_error_t hbrtRiDestroy(uint32_t ri_id) |
功能 |
释放正在运行的实例占用的资源 |
参数 |
[输入] ri_id: 此运行实例的 id |
说明 |
在调用hbrtRiDestroy释放它之前,不能选择 ri_id 重新启动另一个正在运行的实例 |
函数原型 |
hbrt_error_t hbrtRiIsDone(bool *is_done, uint32_t ri_id) |
功能 |
返回与运行实例绑定的模型推断是否已完成 |
参数 |
[输出] is_done: true 表示模型已完全执行 |
[输入] ri_id: 此运行实例的 id |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtRiNextSegmentInvolveCpu(bool *involve_cpu, uint32_t ri_id) |
功能 |
返回是否下一次调用 hbrtRiContinue 涉及 CPU 层计算 |
参数 |
[输出] involve_cpu: ture 代表指定的运行实例下一次调用 hbrtRiContinue 涉及 CPU 计算 |
[输入] ri_id: 此运行实例的 id |
|
说明 |
此功能用于用户代码的 pipeline 调度 |
函数原型 |
hbrt_error_t hbrtBilinearRoiResizeImage(void **funccall_buffer, uint32_t *generated_funccall_num, bpu_addr_t image_y_addr, bpu_addr_t image_uv_addr, uint32_t image_height, uint32_t image_width, uint32_t image_h_stride, bool uv_enable, hbrt_pad_mode_t pad_mode,const hbrt_roi_t *p_rois, uint32_t roi_num, uint32_t dest_w, uint32_t dest_h, hbrt_layout_type_t output_layout, bpu_addr_t output_bpu_addr, uint32_t ri_id, MARCH march, uint32_t interrupt_num) |
功能 |
生成 Funccall 以通过双线性插值来调整NV12图像的ROI大小 |
参数 |
[输出] funccall_buffer: 为剪裁和缩放生成的 Funccall |
[输出] generated_funccall_num: 生成的 Funccall 数目 |
|
[输入] image_y_addr: 图像 Y 通道的地址 |
|
[输入] image_uv_addr: 图像 UV 通道的地址 |
|
[输入] image_height: 图像高度 |
|
[输入] image_width: 图像宽度 |
|
[输入] image_h_stride: 图像一行的 byte 大小 |
|
[输入] uv_enable: 是否剪裁和缩放 uv 通道 |
|
[输入] pad_mode: 超出图像边界范围的 pad 模式 |
|
[输入] p_rois: 指向 ROI 的指针 |
|
[输入] roi_num: ROI 的数目 |
|
[输入] dest_w: 指定的 ROI 将会被缩放到此宽度 |
|
[输入] dest_h: 指定的 ROI 将会被缩放到此高度 |
|
[输入] output_layout: 输出的排布 |
|
[输入] output_bpu_addr: 输出地址 |
|
[输入] ri_id: 执行此生成 Funccall 的运行实例 id |
|
[输入] march: 参看说明 |
|
[输入] interrupt_num: 此生成的 Funccall 执行结束时产生的中断号 |
|
说明 |
1.输入图片的格式应为 YUV420NV12, 2.输出图片的格式为 YUV444。 |
函数原型 |
hbrt_error_t hbrtRiGetModelHandle(hbrt_model_handle_t *model_handle, uint32_t ri_id) |
功能 |
从正在运行的实例索引获取模型句柄 |
参数 |
[输出] model_handle: 与运行实例绑定的模型句柄 |
[输入] ri_id: 运行实例的索引 id |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtRiGetConfig(const hbrt_ri_config_t **ri_config, uint32_t ri_id) |
功能 |
从正在运行的实例索引中获取配置 |
参数 |
[输出] ri_config: 所指定运行实例的配置 |
[输入] ri_id: 运行实例的索引 id |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtRiGetInputInfo(const hbrt_ri_input_info_t **input_info, uint32_t ri_id) |
功能 |
从正在运行的实例索引获取输入信息 |
参数 |
[输出] input_info: 与所指定运行实例绑定的模型的输入信息 |
[输入] ri_id: 运行实例的索引 id |
|
说明 |
无 |
10.2.6. 获取模型输出¶
函数原型 |
hbrt_error_t hbrtRiGetOutputStatus(uint64_t *status, uint32_t ri_id); |
功能 |
获得输出的状态. |
参数 |
[输出] status: 输出状态位图 |
[输入] ri_id: 运行实例的ID |
|
说明 |
在整个RI完成之前,可能已经生成了输出功能。(例如,具有几个 输出的大型模型)调用此函数以检查那个输出可以使用了。 状态是位图(如果设置了第0比特,则输出0准备就绪, 如果设置了第1比特,则输出1准备就绪,等等) |
函数原型 |
hbrt_error_t hbrtRiGetFeatureBpuAddress(bpu_addr_t *addr, uint32_t ri_id, hbrt_feature_handle_t fh); |
功能 |
获取指定运行实例的特征数据的BPU地址 |
参数 |
[输出] addr: 特征数据的BPU地址 |
[输入] ri_id: 运行实例的ID |
|
[输入] fh: 特征数据的句柄 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbriGetFeatureData(void **data, uint32_t ri_id, hbrt_feature_handle_t fh, DATA_WORK work); |
功能 |
获取指定运行实例的特征数据 |
参数 |
[输出] data: 特征数据 |
[输入] ri_id: 运行实例的ID |
|
[输入] fh: 特征数据的句柄 |
|
[输入] work: 处理数据的方式,查看 ::DATA_WORK. |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtRiGetOutputData(void **data, uint32_t ri_id, uint32_t output_index, DATA_WORK work); |
功能 |
获取指定运行实例输出特征的数据 |
参数 |
[输出] data: 特征数据 |
[输入] ri_id: 运行实例的ID |
|
[输入] output_index: 输出的索引 |
|
[输入] work: 处理数据的方式,查看 ::DATA_WORK. |
|
说明 |
与HbrtRiGetFeatureData相似,但是给出了输出索引而不是特征句柄。 |
函数原型 |
hbrt_error_t hbrtUnquantize(float *to_float_data, hbrt_element_type_t from_int_element_type, hbrt_dimension_t dim, const uint8_t *shifts, const void *from_int_data); |
功能 |
反量化数据 |
参数 |
[输出] to_float_data: 反量化的浮点数据将被写入此地址 |
[输入] from_int_element_type: 原始整数类型 |
|
[输入] dim: 原始数据的维度,应该是有4个元素的uint32类型的数组 |
|
[输入] shifts: 数据的移位值 |
|
[输入] from_int_data: 源数据的地址 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtUnquantizeByScale(float *to_float_data, hbrt_element_type_t from_int_element_type, hbrt_dimension_t dim, const float *scales, const void *from_int_data); |
功能 |
按照缩放值反量化数据。 |
参数 |
[输出] to_float_data:反量化浮点数据将会写入该地址。 |
[输入] from_int_element_type:源数据的元素类型。 |
|
[输入] dim:源数据的维度。应为4个uint32元素的数组。 |
|
[输入] scales:数据的缩放值。 |
|
[输入] from_int_data:源数据的地址。 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtQuantize(void *to_int_data, hbrt_element_type_t to_int_element_type, hbrt_dimension_t dim, const uint8_t *shifts, const float *from_float_data); |
功能 |
量化数据 |
参数 |
[输出] to_int_data: 量化的整数数据将被写入此地址 |
[输入] to_int_element_type: 目标整数类型 |
|
[输入] dim: 源数据的维度,应该是有4个元素的uint32类型的数组 |
|
[输入] shifts: 数据的移位值 |
|
[输入] from_float_data: 源数据的地址 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtQuantizeByScale(void *to_int_data, hbrt_element_type_t to_int_element_type, hbrt_dimension_t dim, const float *scales, const float *from_float_data); |
功能 |
按照缩放值量化数据。 |
参数 |
[输出] to_int_data:量化整数数据将会写入该地址。 |
[输入] to_int_element_type:目标元素类型。 |
|
[输入] dim: 源数据维度。应为包含4个uint32元素的数组。 |
|
[输入] scales: 数据缩放值。 |
|
[输入] from_float_data:源数据地址。 |
|
说明 |
无 |
10.2.7. 工具函数¶
10.2.7.1. 描述¶
软件包提供辅助函数,这些函数可以让用户转换不同的数据排布格式,记录funccall日志等功能。
10.2.7.2. 转换数据排布格式¶
函数原型 |
hbrt_error_t hbrtGetLayoutName(const char **name, hbrt_layout_type_t layout) |
功能 |
提取给定数据排布类型的名字 |
参数 |
[输出] name: 排布类型的名字 |
[输入] layout: 排布的enum |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtConvertLayout(void *to_data, hbrt_layout_type_t to_layout_type, const void *from_data, hbrt_layout_type_t from_layout_type, hbrt_element_type_t element_type, hbrt_dimension_t aligned_dim, bool convert_endianness) |
功能 |
转换输入数据排布格式 |
参数 |
[输出] to_data: 转换后的数据存储地址 |
[输入] to_layout_type: 目标数据排布 |
|
[输入] from_data: 源数据的地址 |
|
[输入] from_layout_type: 源数据的排布 |
|
[输入] element_type: 数据的数据类型 |
|
[输入] aligned_dim: 源数据的维度 |
|
[输入] convert_endianness: 如果为真,源数据字节序也会被转换 |
|
说明 |
对齐后的维度包含padding. 用户必须自己负责对齐数据,并传入函数。 输出数据的维度不会变化,因为这个函数至转换数据排布格式,并不改编维度大小。 |
函数原型 |
hbrt_error_t hbrtConvertLayoutRoi(void *to_data, hbrt_layout_type_t to_layout_type, const void *from_data, hbrt_layout_type_t from_layout_type, hbrt_element_type_t element_type, hbrt_dimension_t aligned_dim, bool convert_endianness, hbrt_roi_t roi) |
功能 |
根据发给定的roi(coord, size)转换输入排布 |
参数 |
[输出] to_data: 转换后的数据存储地址 |
[输入] to_layout_type: 目标数据排布 |
|
[输入] from_data: 源数据的地址 |
|
[输入] from_layout_type: 源数据的排布 |
|
[输入] element_type: 数据的数据类型 |
|
[输入] aligned_dim: 源数据的维度 |
|
[输入] convert_endianness: 如果为真,源数据字节序也会被转换 |
|
[输入] roi: Roi(coord, size). |
|
说明 |
对齐后的维度包含padding. 用户必须自己负责对齐数据,并传入函数。 输出数据的维度不会变化,因为这个函数至转换数据排布格式,并不改编维度大小。 |
函数原型 |
hbrt_error_t hbrtConvertLayoutToNative1HW1(void *to_data, const void *from_data, hbrt_layout_type_t from_layout_type, hbrt_element_type_t element_type, hbrt_dimension_t aligned_dim, bool convert_endianness, uint32_t n_index, uint32_t c_index) |
功能 |
根据发给定的roi({n_index, 0, 0, c_index}, {1, H, W, 1})转换输入排布 |
参数 |
[输出] to_data: 转换后的数据存储地址 |
[输入] from_data: 源数据的地址 |
|
[输入] from_layout_type: 源数据的排布 |
|
[输入] element_type: 数据的数据类型 |
|
[输入] aligned_dim: 源数据的维度 |
|
[输入] convert_endianness: 如果为真,源数据字节序也会被转换 |
|
[输入] n_index: 要被转换数据的N维度的index |
|
[输入] c_index: 要被转换数据的C维度的index |
|
说明 |
对齐后的维度包含padding. 用户必须自己负责对齐数据,并传入函数。 对于给定的N和C,函数转换整个HxW平面 |
函数原型 |
hbrt_error t hbrtConvertLayoutToNative111C(void *to_data, const void *from_data, hbrt_layout_type_t from_layout_type, hbrt_element_type_t element_type, hbrt_dimension_t aligned_dim, bool convert_endianness, uint32_t n_index, uint32_t h_index, uint32_t w_index) |
功能 |
根据发给定的roi({n_nidex, h_index, w_index, 0}, {1, 1, 1, C})转换输入排布 |
参数 |
[输出] to_data: 转换后的数据存储地址 |
[输入] from_data: 源数据的地址 |
|
[输入] from_layout_type: 源数据的排布 |
|
[输入] element_type: 数据的数据类型 |
|
[输入] aligned_dim: 源数据的维度 |
|
[输入] convert_endianness: 如果为真,源数据字节序也会被转换 |
|
[输入] n_index: 要被转换数据的N维度的index |
|
[输入] h_index: 要被转换数据的H维度的index |
|
[输入] w_index: 要被转换数据的W维度的index |
|
说明 |
对齐后的维度包含padding. 用户必须自己负责对齐数据,并传入函数。 对于给定的N,H和W,函数转换整个C通道 |
函数原型 |
hbrt_error_t hbrtConvertLayoutToNative1111(void *to_data, const void *from_data, hbrt_layout_type_t from_layout_type, hbrt_element_type_t element_type, hbrt_dimension_t aligned_dim, bool convert_endianness, uint32_t n_index, uint32_t h_index, uint32_t w_index, uint32_t c_index) |
功能 |
根据发给定的roi({n_nidex, h_index, w_index, c_index}, {1, 1, 1, 1})转换输入排布 |
参数 |
[输出] to_data: 转换后的数据存储地址 |
[输入] from_data: 源数据的地址 |
|
[输入] from_layout_type: 源数据的排布 |
|
[输入] element_type: 数据的数据类型 |
|
[输入] aligned_dim: 源数据的维度 |
|
[输入] convert_endianness: 如果为真,源数据字节序也会被转换 |
|
[输入] n_index: 要被转换数据的N维度的index |
|
[输入] h_index: 要被转换数据的H维度的index |
|
[输入] w_index: 要被转换数据的W维度的index |
|
[输入] c_index: 要被转换数据的C维度的index |
|
说明 |
对齐后的维度包含padding. 用户必须自己负责对齐数据,并传入函数。 |
函数原型 |
hbrt_error_t hbrtAddPadding(void *data_with_padding, hbrt_dimension_t dim_with_padding, const void *data_wo_padding, hbrt_dimension_t dim_wo_padding, hbrt_element_type_t element_type) |
功能 |
给输入加上padding |
参数 |
[输出] data_with_padding: 加上padding后的数据的地址 |
[输入] dim_with_padding: 加上padding后的维度 |
|
[输入] data_wo_padding: 没有padding的源数据 |
|
[输入] dim_wo_padding: 没有padding的源数据的维度 |
|
[输入] element_type: 源数据的数据类型 |
|
说明 |
用户自己负责完整性检查 |
函数原型 |
hbrt_error_t hbrtRemovePadding(void *data_wo_padding, hbrt_dimension_t dim_wo_padding, const void *data_with_padding, hbrt_dimension_t dim_with_padding, hbrt_element_type_t element_type) |
功能 |
给输入去除padding |
参数 |
[输出] data_with_padding: 去除padding后的数据的地址 |
[输入] dim_with_padding: 去除padding后的维度 |
|
[输入] data_wo_padding: 有padding的源数据 |
|
[输入] dim_wo_padding: 有padding的源数据的维度 |
|
[输入] element_type: 源数据的数据类型 |
|
说明 |
无 |
函数原型 |
hbrt_error_t hbrtConvertEndianness (void *output, const void *input, size_t size) |
功能 |
转换输入的字节序 |
参数 |
[输出] output: 结果存储到这个地址 |
[输入] input: 源数据地址 |
|
[输入] size: 源数据字节数 |
|
说明 |
输入和输出不能重叠,除非它们有一样的地址 |
10.2.7.3. 日志记录¶
函数原型 |
hbrt_error_t hbrtSetLogLevel() |
功能 |
设置记录详细级别 |
参数 |
无 |
说明 |
运行时日志记录详细级别是通过读取环境变量HBRT_LOG_LEVEL来设定的 |
总共有5个级别,从0到4:
|
函数原型 |
hbrt_error_t hbrtPrintFunccall(const void *funccall) |
功能 |
打印给定的funccall |
参数 |
[输入] funccall: 包含funccall的缓存地址 |
说明 |
缓存可能包含多个funccall,多个funccall会按顺序打印 |
10.2.8. 特征量化类型¶
索引 |
特征量化类型 |
描述 |
0 |
QUANTIZED_BY_NONE |
特征包含浮点值,不需要量化和反量化。 |
1 |
QUANTIZED_BY_SHIFT |
特征包含定点数据,使用前需按照移位值反量化。 |
2 |
QUANTIZED_BY_SCALE |
特征包含定点数据,使用前需按照缩放值反量化。 |
10.2.9. 状态码¶
索引 |
状态码 |
描述 |
0 |
hbrtSuccess |
API调用返回没有错误 |
1 |
hbrtErrorCannotOpenFile |
传递给API的文件路径无效 |
2 |
hbrtErrorHBMIdIsBusy |
API尝试将一个hbm加载到已被另一个hbm占用的内存块中 |
3 |
hbrtErrorHBMSlotIsFull |
已加载的hbm数量已超过限制 |
4 |
hbrtErrorHBMAlreadyLoaded |
API正在尝试加载之前已加载的hbm |
5 |
hbrtErrorHBMCCForDifferentMARCH |
API正在尝试加载为其他微架构的编译的hbm |
6 |
hbrtErrorHBMCRC32VerifyFail |
crc32校验和与记录的内容不同 |
7 |
hbrtErrorMemoryAllocationFail |
在API内部调用的malloc api返回null_ptr |
8 |
hbrtErrorMemoryOverflow |
传递给API的内存太小,无法包含数据 |
9 |
hbrtErrorNumericOverflow |
API内部发生数字溢出 |
10 |
hbrtErrorIllegalCoreMask |
传递给API的core-mask是非法的 |
11 |
hbrtErrorIllegalMARCH |
传递给API的微架构或从hbm解码的微架构是非法的 |
12 |
hbrtErrorIllegalHBM |
API的输入hbm非法 |
13 |
hbrtErrorIllegalHBMHandle |
传递给API的hbm句柄是非法的 |
14 |
hbrtErrorIllegalElementType |
传递给API或从hbm解码的元素类型是非法的 |
15 |
hbrtErrorIllegalInputSourceType |
传递到API或从hbm解码的输入源是非法的 |
16 |
hbrtErrorIllegalRegionType |
传递给API或从hbm解码的区域类型是非法的 |
17 |
hbrtErrorIllegalRIID |
传递给API或从句柄获取的ri_id是非法的 |
18 |
hbrtErrorIllegalRegisterValue |
从hbm解码或由运行时确定的寄存器值是非法的 |
19 |
hbrtErrorIllegalOutputRegion |
传递给API或由运行时创建的输出区域是非法的 |
20 |
hbrtErrorIllegalIntermediateRegion |
运行时创建的中间区域是非法的 |
21 |
hbrtErrorIllegalHeapRegion |
运行时创建的堆区域是非法的 |
22 |
hbrtErrorIllegalRIConfig |
传递到API或从句柄获取的RI配置是非法的 |
23 |
hbrtErrorIllegalRegisterType |
从hbm解码的寄存器类型是非法的 |
24 |
hbrtErrorIllegalCPUOperator |
从hbm解码的CPU操作参数是非法的 |
25 |
hbrtErrorIllegalLayout |
传递给API或从句柄获取的数据排布是非法的 |
26 |
hbrtErrorIllegalMemoryRead |
API内部发生了非法的内存访问 |
27 |
hbrtErrorIllegalModel |
尝试执行无法被相应API访问的模型 |
28 |
hbrtErrorInvalidHBMHandle |
传递给API的hbm句柄无效 |
29 |
hbrtErrorInvalidModelHandle |
传递给API的输入模型句柄无效 |
30 |
hbrtErrorInvalidFeatureHandle |
传递给API的特征张量句柄无效 |
31 |
hbrtErrorInvalidModelName |
传递给API的模型名称无效,或者hbm不包含具有该名称的模型 |
32 |
hbrtErrorInvalidInputIndex |
传递给API的输入索引无效或超过模型输入数 |
33 |
hbrtErrorInvalidOutputIndex |
传递给API的输出索引无效或超过模型输出数 |
34 |
hbrtErrorInvalidBatchCount |
从hbm解码的批计数无效 |
35 |
hbrtErrorInvalidSegmentIndex |
从ri或其他结构获取的段索引无效 |
36 |
hbrtErrorInvalidInterruptNum |
传递给API的中断号无效 |
37 |
hbrtErrorInvalidResizerParam |
传递给API的缩放参数无效 |
38 |
hbrtErrorInvalidDataWork |
传递给API的数据工作方式无效 |
39 |
hbrtErrorInvalidAddress |
传递给API或从其他结构获取的地址无效 |
40 |
hbrtErrorInvalidRle |
RLE解码期间发生错误 |
41 |
hbrtErrorInvalidRoi |
传递给RoiAlign的ROI无效 |
42 |
hbrtErrorBPUCPUMemcpyFail |
bpu_memcpy在API内部返回了非零值 |
43 |
hbrtErrorBPUMemAllocFail |
bpu_mem_alloc在API内返回了null_ptr |
44 |
hbrtErrorBPUCPUMemAllocFail |
bpu_cpumem_alloc在API内返回了null_ptr |
45 |
hbrtErrorRiIsNotInUse |
传递给API的ri_id不与任何模型绑定 |
46 |
hbrtErrorRiIsInUse |
API尝试以一个没有销毁的ri_id启动另一个运行实例 |
47 |
hbrtErrorFunccallSlotNotEnough |
存储 Funccall 的内存太小,无法容纳生成的函数调用 |
48 |
hbrtErrorFunctionNotImplemented |
当前版本尚未实现该API |
49 |
hbrtErrorInvalidLicense |
您的本地许可证不允许访问此HBM |
50 |
hbrtErrorIncompatibleVersion |
头文件或HBM的版本与当前的运行时库不兼容 |
51 |
hbrtErrorInvalidMemoryPool |
HBDK运行时内存池中发生错误 |
52 |
hbrtErrorAccessToEmptyData |
尝试存储不存在的数据或空数据 |
10.3. VIO API¶
VIO API 参见《MU-2020-1-C-X2J2平台系统软件接口手册》。