8. 应用开发工具¶
8.1. 嵌入式 SDK 简介¶
8.1.1. 目录结构¶
应用包的目录结构如下:
embedded-release-sdk.tar.gz
.
├── embedded_model_zoo
│ ├── fasterrcnn
│ ├── fasterrcnn_mobilenetv2
│ ├── maskrcnn
│ ├── mobileNetV1
│ ├── mobileNetV2
│ ├── parsing
│ ├── resNet18
│ ├── resNet50
│ ├── s3fd
│ ├── shuffleNetV2
│ ├── ssd
│ ├── ssd_mobilenetv2
│ ├── vargNetV2
│ ├── yolo
│ ├── yolo_origin
│ └── yolo_parsing
├── example_code
│ ├── analysis
│ ├── app_code
│ ├── common
│ ├── demo_code
│ ├── functional_example
│ ├── runtime_example
│ ├── time_consuming_test
│ └── x86_code
└── example_prebuilt
├── analysis
├── app
├── demo
├── functional_example
├── time_consuming_test
└── x86
embedded-contrib-sdk.tar.gz
.
├── embedded_contrib_model_zoo
├── example_code
└── example_prebuilt
app 包含基于 hobotsdk 的预置应用,以并行方式运行。包括以下运行模式供参考:
摄像头模式:使用 720p/1080p 摄像头作为输入。经 X2/J2 处理后,通过以太网发出。
回灌模式:使用 720p/1080p 图像经以太网传入(算法包中我们提供了回灌工具 pc-sender)。经 X2/J2 处理然后通过以太网发出。有些输入会发送至 std-out。
静态模式:使用 720p/1080p jpeg image 作为输入,在X2/J2处理,结果输出到 std-out 或发回客户端。
demo 包含基于 c++ stl 的 demo 应用,为单线程。该 demo 应用帮助理解 bpu_predict 接口。
eval 使用网络发送图像,对精度进行验证的应用。
perf 包含一些应用。这些应用基于 hobotsdk,因此以并行方式运行。通过日志,可以查看性能分析指标。
xxx_code 包含示例对应的源码。
runtime_example 包含基于 hbrt api 和 platform api 开发的示例。详情参见 API 参考。
lidar3D:雷达3D点云示例。
pyramid:pyramid耗时测试示例。关于如何进行 Pyramid 模块耗时测试,参见9.6 如何进行金字塔模块耗时测试?
resizer:roi resizer耗时测试示例。关于如何进行 ROIresizer 模块耗时测试,参见9.7 如何进行 ROIresizer 模块耗时测试?
roi_detection_test:roi detection 测试示例。
x86:功能与 app 相同,区别是在 CPU 上运行。
camera_input_demo:同步接口示例程序,支持720p的camera作为输入。
resize_input_demo:同步接口示例程序,其输入通过硬件对图片进行 resize。
static_input_demo:同步接口示例程序,支持多种颜色空间的图片作为输入。
pure_c_demo:同步接口示例程序,展示了bpu_predict可支持 C 语言编译。
Note
在使用示例前请将交付物中的 embedded_model_zoo 软链链接到示例目录 model_zoo 下。例如,ln -s ../embedded_model_zoo/ model_zoo
当 hbm 大小超过 128M 时,可能因为ddr大小限制导致示例启动失败。请注意报错关键字:hbrtErrorCannotOpenFile。
编译嵌入式应用
配置环境
使用前,请使用交付物中的 cmake 和交叉编译工具,将交叉编译工具 CC 和 CXX 及 cmake 配置到 PATH 中。
示例:
export CC=/root/env/gcc-linaro-6.5.0-2018.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-gcc
export CXX=/root/env/gcc-linaro-6.5.0-2018.12-x86_64_aarch64-linux-gnu/bin/aarch64-linux-gnu-g++
export PATH=/root/env/cmake-3.7.2-Linux-x86_64/bin:$PATH
交叉编译可执行文件。
命令示例:
mkdir build; cd build; cmake ..; make
部署。
将编译之后生成的 app 替换示例包中的 app 文件,使修改的代码生效。
Note
请根据开发环境修改文件路径。
使用 xxx_code 中的示例。
8.1.2. 功能描述¶
在 app 中:
- start_fasterrcnn.sh
支持摄像头模式、回灌模式和静态图模式的 fasterrcnn 检测。
- start_fasterrcnn_mobileNetV2.sh
支持摄像头模式,回灌模式和静态图模式的 fasterrcnn 检测 +mobileNetV2 分类。
- start_maskrcnn.sh
支持摄像头模式,回灌模式和静态图模式的 maskrcnn 检测。
- start_parsing.sh
支持摄像头模式,回灌模式和静态图模式的 parsing 分割。
- start_ssd.sh
支持摄像头模式,回灌模式和静态图模式的 ssd 检测。
- start_yolo.sh
支持支持摄像头模式,回灌模式和静态图模式的 yolo 检测。
- start_ssd_mobileNetV2.sh
支持摄像头模式,回灌模式和静态图模式的 ssd 检测 +mobileNetV2 分类。
Note
要改变 app 的运行模式,请在 start_xxx.sh 中编辑命令。
#!/bin/bash
LIB_DIR='./lib'
export LD_LIBRARY_PATH=${LIB_DIR}:${LD_LIBRARY_PATH}
export BMEM_CACHEABLE=true
echo 105000 >/sys/devices/virtual/thermal/thermal_zone0/trip_point_1_temp
echo performance > /sys/devices/system/cpu/cpufreq/policy0/scaling_governor
# FasterRCNN detection
#./app --camera-id=0 --run-type=camera --task-type=main --main-type=detection --detection-model-name=fasterrcnn --model-file=./model_zoo/fasterrcnn.hbm_mobileNetV1_704x1280 --board-name=x2 --input-platform=tensorflow --score-thresh=0.7
#./app --camera-id=0 --run-type=camera --task-type=main --main-type=detection --detection-model-name=fasterrcnn --model-file=./model_zoo/fasterrcnn.hbm_mobileNetV1_540x960 --image-size=1080P --pyramid-level=4 --board-name=x2 --input-platform=tensorflow --score-threshh
=0.7
#./app --camera-id=0 --run-type=feedback --task-type=main --main-type=detection --detection-model-name=fasterrcnn --model-file=./model_zoo/fasterrcnn.hbm_mobileNetV1_704x1280 --image-size=720P --input-platform=tensorflow --score-thresh=0.7
#./app --camera-id=0 --run-type=feedback --task-type=main --main-type=detection --detection-model-name=fasterrcnn --model-file=./model_zoo/fasterrcnn.hbm_mobileNetV1_540x960 --image-size=1080P --pyramid-level=4 --input-platform=tensorflow --score-thresh=0.7
./app --camera-id=0 --run-type=static --task-type=main --main-type=detection --detection-model-name=fasterrcnn --model-file=./model_zoo/fasterrcnn.hbm_mobileNetV1_704x1280 --image-size=720P --test-image=test_720P.jpg --input-platform=tensorflow --score-thresh=0.7
#./app --camera-id=0 --run-type=static --task-type=main --main-type=detection --detection-model-name=fasterrcnn --model-file=./model_zoo/fasterrcnn.hbm_mobileNetV1_540x960 --image-size=1080P --test-image=test_1080P.jpg --pyramid-level=4 --input-platform=tensorflow ---
score-thresh=0.7
在 demo 中:
- start_mobileNetV1.sh
静态图的 mobileNetV1 分类。
- start_mobileNetV2.sh
静态图的 mobileNetV2 分类。
- start_resNet18.sh
静态图的 resNet18 分类。
- start_resNet50.sh
静态图的 resNet50 分类。
在 runtime_example 中:
为示例代码,便于开发者熟悉 hbdk 运行时 API。
8.1.3. 嵌入式应用参数说明¶
嵌入式应用开发包 embedded_system_sdk 包含三个应用文件夹,即 app、demo 和 perf。命令行输入参数描述如下:
8.1.3.1. app¶
命令行输入参数 |
描述 |
--camera-id |
设置图片来源的摄像头id,参数在--run-type=camera时有效,默认为“0”(暂时无效)。 |
--run-type |
设置图片输入模式类型,包括camera,feedback,static。默认为“camera”。 |
--task-type |
设置任务类型,包括main和main+class。默认为“”。
|
--main-type |
设置主要任务:detection或parsing。detection类型有 yolo,ssd,fasterrcnn,maskrcnn。默认为“”。 |
--detection-model-name |
设置detection或parsing模型的名称。默认为“”。 |
--resizer-model-name |
设置resizer模型的名称,此参数在--task-type=main+class时有效。 默认为“”。 |
--model-file |
设置模型存储的文件名。默认为“”。 |
--test-image |
设置输入的图片名,参数在--run-type=static时有效。默认为“test.jpg”。 |
--image-size |
设置图片尺寸,包括720p,1080p。默认为“720P”。 |
--image-width |
设置图片宽度。默认为:1280。 |
--image-height |
设置图片高度。默认为:720。 |
--pyramid-level |
设置图像金字塔层id,图片金字塔处理后的输出中抽取一层作为模型的输入:
|
--input-platform |
设置模型框架类型,包括mxnet和tensorflow,参数在--main-type=yolo或 --main-type=ssd时无效。默认为“mxnet”。 |
--send-level |
设置图像金字塔层id,参见--pyramid-level,金字塔中抽取的一层图片与模型输出一 起被传送出去。默认为0。 |
--is-performance |
设置是否速度为主。默认为false。
|
--board-name |
开发板名称[x2/j2]。默认为“x2”。 |
--score-thresh |
检测模型后处理的分数阈值,默认为0。 (当其取值为0时,不同模型将在后处理过程中取默认值)。 |
--nms-thresh |
检测模型后处理的iou阈值,默认为0.3。 |
--before-nms-topk |
检测模式下执行nms之前的topk数,默认为5000。 |
--nms-topk |
检测模式下执行nms之后的topk数,默认为750。 |
--group-proportion |
设置group proportion,默认为0。 |
--client-port |
设置客户端端口号,默认为5560。 |
--frame-count |
设置应用执行帧数,默认为0(当其取值为0时不生效)。 |
--single-stage |
单阶段运行模型,默认为false。 |
8.1.3.2. demo¶
命令行输入参数 |
描述 |
--frame-count |
设置需要检测或分类的图片数量,默认为0。 |
--is-ssd |
设置任务类型为ssd检测,默认为false。 |
--is-yolo |
设置任务类型为yolo检测,默认为false。 |
--is-fasterrcnn |
设置任务类型为fasterrcnn检测,默认为false。 |
--is-classification |
设置任务类型为分类,默认为false。 |
--image-size |
设置图片尺寸,输入格式为HxW,默认为“”。 |
--detection-module- name |
设置检测或分类模型的名称,默认为“”。 |
--resizer-module-name |
设置分类模型的名称,默认为“”。 |
--test-image |
设置测试集输入文件名,文件中包含了 数据集的图片名字,默认为“”。 |
--model-file |
设置模型存储的文件名,默认为“”。 |
--help |
打印参数信息。 |
--is-tensorflow- model |
运行tensorflow模型。默认为false。 |
8.1.3.3. perf¶
命令行输入参数 |
描述 |
--camera-id |
设置图片来源的摄像头id,默认为0。 |
--run-type |
设置图片输入模式类型,默认为“camera”。 |
--task-type |
设置任务类型,默认为“”。 |
--main-type |
设置模块主类型,detection或parsing。默认为“”。 |
--detection-model-name |
设置检测模型的名称,默认为“”。 |
--resizer-model-name |
设置分类模型的名称,默认为“”。 |
--model-file |
设置模型存储的文件名,默认为“”。 |
--imagelst-path |
设置测试集输入文件名,文件中包含了数据集的图片名字,默认为“img.lst”。 |
--image-size |
设置图片格式类型,包括720p,1080p,默认为“720P”。 |
--image-width |
设置图片宽度,默认为720。 |
--image-height |
设置图片高度,默认为1080。 |
--input-platform |
设置模型框架类型,包括mxnet,tensorflow。默认为mxnet。 |
--sleep-num |
设置读取图片的等待时间,默认为0。 |
--is-performance |
设置是否速度为主,默认为false。
|
--not-init-load-image |
设置当输入模块初始化时是否加载数据集:默认为false。
|
--stop-num |
设置运行停止之后的帧数,默认为0。 |
--group-proportion |
设置group proportion,默认为0。 |
--class-output-num |
分类模式的topk大小,只在分类模式下有效。默认为1。 |
--image-width-padding-num |
设置图片宽度的填充大小,默认为0。 |
--single-stage |
单阶段运行模型,默认为false。 |
--score-thresh |
检测模型后处理的分数阈值,默认为0。(当其取值为0时,不同模型将在后处理过程中取默认值)。 |
--nms-thresh |
检测模型后处理的iou阈值,默认为0.3。 |
--before-nms-topk |
检测模式下执行nms前的topk数,默认为5000。 |
--nms-topk |
检测模式下执行nms后的topk数,默认为750。 |
--client-port |
设置客户端口号,默认为5560。 |
--semaphore-num |
设置信号量大小,默认为5。 |
8.1.3.4. bpu_config.json¶
当前X2/J2平台的bpu中存在两个内核可参与运算,嵌入式应用包中的bpu_config.json文件能够配置运算内核个数和方式,bpu_config.json文件的参数说明如下表所示。
参数 |
描述 |
enable_core_num |
|
engine_type(可选) |
|
core_engine(可选) |
|
8.2. BPU 预测库¶
8.2.1. 模型相关功能¶
本小节介绍如何使用 BPU 预测库 API 来加载模型,获取模型相关的信息。
8.2.1.1. 模型加载¶
BPU 预测库 API 要加载的模型是 .hbm 文件。这种文件是 hbdk 编译工具产生出的二进制文件。其中包含了模型名和每个模型的指令、参数。
const char *bpu_model = "./model_zoo/mobileNetV2.hbm"; // specify model file path
BPUHandle bpu_handle;
int ret = BPU_loadModel(bpu_model, &bpu_handle);
if (ret != 0) {
std::cout << "here load bpu model failed: " << BPU_getLastError(bpu_handle) << std::endl;
return 1;
}
std::cout << "here load bpu model OK" << std::endl;
8.2.1.2. BPU 配置文件¶
可以在 BPU_loadModel 函数中传递一个配置文件,指定 BPU 预测库 API 运行时的参数。
int BPU_loadModel(const char* model_file_name, BPUHandle *handle, const char *config_file_name = nullptr);
config_file_name 指定配置文件的路径。配置文件是一个 json 格式的文件,形式如下:
{
"core_engine": "dual"
}
目前支持的配置参数如下:
core_engine 指定BPU预测库 API 使用的 engine 类型。可以配置为 naive 和 dual。默认为 naive。
8.2.1.3. 获取模型信息¶
可以使用以下方式获取模型信息:
int ret = BPU_getModelInputInfo(bpu_handle, model_name, &output_info);
std::cout << "model: " << model_name << " input info: " << std::endl;
for (int i = 0; i < output_info.num; ++i) {
std::cout << "(";
for (int j = output_info.ndim_array[i]; j < output_info.ndim_array[i+1]; ++j) {
std::cout << output_info.valid_shape_array[j] << ",";
}
std::cout << ")" << std::endl;
}
ret = BPU_getModelOutputInfo(bpu_handle, model_name, &output_info);
if (ret != 0) {
std::cout << "get model: " << model_name << " output info failed: " << BPU_getLastError(bpu_handle) << std::endl;
return 1;
}
std::cout << "model: " << model_name << " has output: " << output_info.num << std::endl;
for (int i = 0; i < output_info.num; ++i) {
std::cout << "name: " << output_info.name_list[i] << ", shape: ";
std::cout << "(";
for (int j = output_info.ndim_array[i]; j < output_info.ndim_array[i+1]; ++j) {
std::cout << output_info.aligned_shape_array[j] << ",";
}
std::cout << ")" << std::endl;
int out_type_size = sizeof(int8_t);
if (output_info.dtype_array[i] == BPU_DTYPE_FLOAT32) {
out_type_size = sizeof(float);
}
std::cout << "output size: " << out_type_size << std::endl;
}
return output_info.num;
8.2.2. 示例教程¶
Note
在实际使用中,camera,feedback 和 static 这三种模式下,都只能连接一个 client。
8.2.2.1. 静态图模式¶
参考 demo_code 中 static_class_example 函数的实现。
// create image iterator
// the iterator read image file, and resize them to (img_height, img_width), and then transfer them to nv12 format
ImageIterator img_iter(args.img_height, args.img_width);
ret = img_iter.init(args.test_image); // args.test_image is an image list file
if (ret != 0) {
std::cout << "init image iterator failed" << std::endl;
return 1;
}
while (cnt++ < need_frames) {
BPUFakeImage *fake_img_ptr = img_iter.next(); // get one image from iterator
if (fake_img_ptr == nullptr) {
break;
}
// alloc output buffer before run model
alloc_output_buffer(out_buf, num_out);
// create a local model_handle object to represent current context of model running.
BPUModelHandle model_handle;
// run model
ret = BPU_runModelFromImage(bpu_handle, model_name, fake_img_ptr,
out_buf.data(), out_buf.size(), &model_handle);
if (ret != 0) {
std::cout << "here run model from fake image failed: "
<< BPU_getLastError(bpu_handle) << std::endl;
return 1;
}
// wait for model run done, and get output
ret = BPU_getModelOutput(bpu_handle, model_handle);
if (ret != 0) {
std::cout << "here get model output failed: "
<< BPU_getLastError(bpu_handle);
return 1;
}
// parsing output data
std::vector<int> result_data(1);
std::vector<int> result_data(1);
ret = parseSoftmaxClassResultTopK(bpu_handle, output_info, model_name,
out_buf.data(), result_data.data(), 1);
if (ret != 0) {
std::cout << "parse class result failed" << std::endl;
return 1;
}
std::cout << "get class id : " << result_data[0] << " name: " << class_names[result_data[0]] << std::endl;
// please remember to release output buffer and model_handle
free_output_buffer(out_buf);
BPU_releaseModelHandle(bpu_handle, model_handle);
// also need to release image ptr
img_iter.free(fake_img_ptr);
}
8.2.2.2. 摄像头模式¶
要使用 camera 模式,首先需要理解 camera 和 pyramid 的关系。在 X2/J2 上,所有的 camera 数据都要先经过 pyramid 模块产生金字塔结果,然后才能被 APP 拿到。
因此,这里用 pyramid 表示 camera。
详情参见 BPU API。
要执行 camera 模式,首先需要初始化 camera 对应的 pyramid 模块。通过传入 vio 和 camera 的配置信息并指定 camera ID 的方式,可以创建对应的 pyramid handle。
pyramid 返回的数据是 nv12 类型,可以直接执行图像相关的模型,调用 BPU_runModelFromPyramid 即可。其他的处理方式与静态图方式相同。
// create a pyramid handle to represent a camera
BPUPyramidHandle pyr_handle;
// use pyramid
const char *vio_config = "./config/hb_vio.json";
const char *camera_config = "./config/hb_camera.json";
ret = BPU_createPyramid(vio_config, camera_config, 0, 0, &pyr_handle);
if (ret != 0) {
std::cout << "create pyramid failed" << std::endl;
return 1;
}
// when got a pyramid handle, we can get a frame data from pyramid
BPUPyramidBuffer pyr_buffer; // pyramid buffer represent all pyramid data
ret = BPU_getPyramidResult(pyr_handle, &pyr_buffer);
if (ret != 0) {
std::cout << "get pyramid result failed" << std::endl;
return 1;
}
alloc_output_buffer(out_buf, out_num);
BPUModelHandle model_handle;
// run model by data from pyramid
int pyramid_level = 0;
ret = BPU_runModelFromPyramid(bpu_handle, model_name, pyr_buffer, pyramid_level,
out_buf.data(), out_buf.size(),
&model_handle);
if (ret != 0) {
std::cout << "run model from pyramid failed" << std::endl;
return 1;
}
// wait for model run done, and get output
ret = BPU_getModelOutput(bpu_handle, model_handle);
if (ret != 0) {
std::cout << "here get model output failed: "
<< BPU_getLastError(bpu_handle);
return 1;
}
8.2.2.3. 回灌模式¶
回灌模式,即 feedback 模式,通常的使用场景是从网络传送图像数据到开发板上,然后对这些图像运行模型。
回灌模式跟 camera 模式很相似,但是数据来源不同。feedback 函数需要输入图像数据的地址,而 camera 是直接写到 memory 中。
BPUFeedbackHandle fb_handle;
/ create feedback handle
const char *fb_config = "./config/feed_back.json"; // feed_back.json specify image height & width
ret = BPU_createFeedback(fb_config, &fb_handle);
if (ret != 0) {
std::cout << "create feedback handle failed" << std::endl;
return 1;
}
BPUPyramidBuffer pyr_buffer;
// input nv12_data_ptr and image_len to get pyramid buffer
ret = BPU_getFeedbackResult(fb_handle, nv12_data, img_len, &pyr_buffer);
if (ret != 0) {
std::cout << "get pyramid result failed" << std::endl;
return 1;
}
// same as camera mode
......
8.2.2.4. Resizer 模式¶
示例代码参见:app_code/src/modules/network/rsz_class_module.cc。
通常运行完检测模型之后,需要对检测框的内容做进一步分析。由于检测框大小不一,因此,需要把检测框图 resize 成固定大小后,再输入到模型。
BPUModelHandle rsz_model_handle;
BPUPyramidBuffer pyr_buffer = pyrMsg->get_buffer();
int resizable_cnt = rsz_box.size();
// run model with resizer
auto ret = BPU_runModelFromResizer(bpu_handle_, model_name_.c_str(),
pyr_buffer, rsz_box.data(), rsz_box.size(),
&resizable_cnt, output_buf_.data(), output_buf_.size(), &rsz_model_handle);
if (ret != 0 && resizable_cnt == 0) {
LOG(ERROR) << "rsz model do not have box to be resized : " << count << "\n";
workflow->Return(this, 0, (*input[0])[0], context);
return;
} else if (ret != 0) {
LOG(FATAL) << "here rsz run model from pyr failed: " << BPU_getLastError(bpu_handle_) << "\n";
}
// LOG(INFO) << "here getting model output\n";
// wait for model run done, and get output
ret = BPU_getModelOutput(bpu_handle_, rsz_model_handle);
if (ret != 0) {
LOG(FATAL) << "here get model output failed: " << BPU_getLastError(bpu_handle_) << "\n";
}
......
// parse resize model output
// the output num is equal to resizable_cnt
std::vector<int> result(resizable_cnt);
LOG(INFO) << "resizable_cnt: " << resizable_cnt << "\n";
std::vector<int> result_data(1);
ret = parseSoftmaxClassResultTopK(bpu_handle, output_info, model_name,
out_buf.data(), result_data.data(), 1);
if (ret != 0) {
LOG(FATAL) << "call parse softmax for rsz failed\n";
}
// LOG(INFO) << "cls_names size: " << this->cls_names_.size() << std::endl;
if (this->cls_names_.size() != 0) {
int j = 0;
for (int i = 0; i < percep_len; ++i) {
// determine whether the current box has been processed according to whether you have set the box as resizable.
// if the resizable option value of the boxes is false, then the boxes cannot be processed by the resizing operation, and these boxes are not inputted into the model. Therefore, these boxes do not have output result.
/*** when you use the resizing results, you must judge whether the box is resizable. ***/
if (!rsz_box[i].resizable) {
continue;
}
int cls_id = result[j++];
percep_ptr[i].box.type = 2;
percep_ptr[i].property = cls_names_[cls_id];
percep_ptr[i].percep_type = 2; // fake id to show in client
// LOG(INFO) << percep_ptr[i].toString() << "\n";
}
}
8.2.3. 高效运行模型¶
8.2.3.1. Empty buffer模式¶
在前面的描述中,执行 runModel 系列函数之前,首先要创建 BPU_Buffer_Handle。创建 BPU_Buffer_Handle 之前,需要先申请一块内存空间。之所以这么做,是为了在 BPU_getModelOutput 函数中把模型 output copy 到 BPU_Buffer_Handle 保存的内存中。
当 model_handle 被释放之后,BPU_Buffer_Handle中 的内容还可以继续被使用。
但是 copy output buffer 的操作会产生额外耗时,尤其是当 output size 较大时。而且,考虑到 output data 在被解析函数处理完成之后就不需要再使用。因此,并不需要单独申请一块 buffer 来保存它。
基于这样的考虑,我们设计了 empty buffer 机制,在保持当前接口不变的前提下,去掉了 copy output 的操作,减小额外内存 copy 造成的性能消耗。
具体使用方式如下:
在创建 BPU_Buffer_Handle 时,提供了一个新的接口 BPU_createEmptyBuffer()。这个函数不需要额外参数,只是创建一个空的 BPU_Buffer,留待后续由 runModel 系列函数填充。
正常执行 runModel 系列函数,把第一阶段创建的 BPU_Buffer_Handle 作为这些 runModel 系列函数的 output buffer 参数。
正常执行 BPU_getModelOutput 函数。
得到 output 数据之后,先不要调用 BPU_releaseModelHandle,先对 output 的 BPU_Buffer 执行解析操作,得到解析结果。
在调用 BPU_releaseModelHandle 之前,先调用 BPU_freeBPUBuffer 释放 BPU_Buffer_Handle,然后再调用 BPU_releaseModelHandle 释放 model handle。
可以看到除了创建 BPU_Buffer_Handle 的方式有变化,在实际使用中没有区别。
8.2.3.2. Dual Engine 模式¶
对于 fasterrcnn 这样的模型,在会被分成多个 segment。有一部分 segment 在 BPU 上计算,一部分 segment 在 CPU 上计算。通常情况下一帧图像运行在 BPU 上的时候,CPU 就会空闲;运行在 CPU 上时,BPU 就会空闲。
因此,我们创建了 dual engine 方式。这种模式可以同时处理两帧图像,当一帧图像在 CPU 上运行时,另外一帧可以运行在 BPU 上。
这种方式能够更好的利用计算资源,提高整体系统的帧率。
使用 dual engine 时,需要在 BPU 的配置文件中设置 core_engine 为 dual,参见 BPU 配置文件。
8.2.4. 结果解析¶
当模型在 BPU 上执行完成之后,会得到 output buffer。针对不同的模型,output buffer 会有不同的格式,需要使用一些具体的方法把 output 转换成可以使用的结果(例如:分类结果,bounding box 等)。
8.2.4.1. 解析地平线特有 operator¶
像分类、SSD、YOLO 这样的模型,它们的最后一个 operator 是 convolution 或者 softmax,所以模型的输出也就是 convolution 或者 softmax 的输出。
但是这些模型输出的解析过程比较复杂,会产生额外的 CPU 消耗以及时间延迟。因此,地平线实现了一些特有的 operator。
这些 operator 由硬件实现,能够输出 bounding box 或者分类 ID。
由于这些 operator 不是公开的实现,需要使用特殊的方式解析他们的结果,我们这里提供了针对这些 operator 的解析 API。
解析 RCNNPostProcessing_X2:
BPURppBBox rpp_bbox;
int ret = BPU_parseRPPResult(bpu_handle_,
model_name_.c_str(),
&out_buf[0],
1,
&rpp_bbox);
if (ret != 0) {
std::cout << "here parse model output failed" << std::endl;
return 1;
}
BPU_parseRPPResult 函数用来解析 RCNNPostProcessing_X2 的输出。输入 output buffer,返回 BPUBBox 类型的结果框。BPUBBox 中包含框的位置、分类 type、score。
8.2.4.2. 解析普通 convolution¶
对于普通的 convolution 输出,根据具体模型的不同,需要有不同的解析方式。例如,SSD 和 YOLO 虽然都是 convolution 输出,但是解析方式很不一样。
同时受到硬件限制,BPU 的 convolution 输出跟原始的模型是不同的,它的 layout 发生了变化。在真正解析结果之前,首先需要把 BPU 的输出转换成原始模型的 layout。
当前我们提供了几种接口实现这样的转换:
enum BPULayoutType {
LAYOUT_1HW1 = 0,
LAYOUT_111C,
LAYOUT_1111,
LAYOUT_NHWC
};
/*
* \brief convert layout.
*/
int BPU_convertLayout(BPUHandle handle, void *to_data, const void *from_data,
const char *model_name, BPULayoutType layout_type,
uint32_t layer_index, uint32_t n_index,
uint32_t h_index, uint32_t w_index, uint32_t c_index);
其中经常使用的是 LAYOUT_111C,它的功能是提取出一个channel的数据。
在 common/parse_class_result.cc 中可以看到对这个函数的使用方式。
这段代码实现的功能是把分类模型的输出(nhwc shape 是1, 1, 1, 1000)转成原始 layout 格式,并计算最大值所在的位置。
仅仅为了得到分类 ID,不需要 softmax 的值。因此,为简化流程,这里没有计算 softmax。
int32_t *class_data = reinterpret_cast<int32_t*>(BPU_getRawBufferPtr(out_buffer[i]));
BPU_convertLayout(bpu_handle, reinterpret_cast<void*>(temp_buff), reinterpret_cast<void*>(class_data),
model_name, LAYOUT_111C, 0, 0, 0, 0, -1);
int max_id = 0;
float max_data = quanti_shift(temp_buff[0], p_shift[0]);
for (int j = 1; j < channel_size; ++j) {
float data = quanti_shift(temp_buff[j], p_shift[j]);
if (max_data < data) {
max_id = j;
max_data = data;
}
}
result_id[i] = max_id;
检测模型的解析也是类似的。详情参见:ssd_result_post_process.cc 和 yolo_result_post_process.cc。
8.3. 系统及应用信息查看¶
8.3.1. 查看系统 DDR 带宽¶
目前用于检测DDR带宽使用情况的工具是 hrut_ddr。将其放在 /usr/bin 或用户自己指定的执行文件目录下便可运行。该工具执行之后便可以打印 ddr 的各个速率。 目前配置的 ddr monitor 的采样间隔是1ms。 执行后的界面如下:
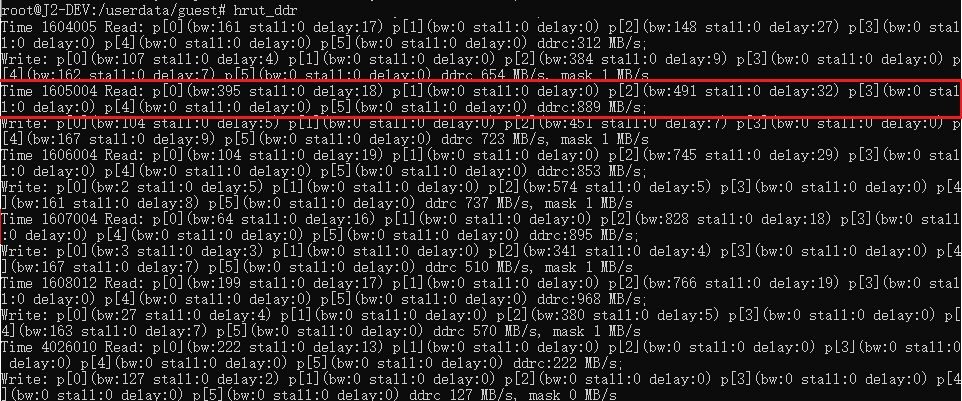
其中:
Time 后跟的是时间,单位:us,
Read 后跟的是 ddr 的6个接口的读取情况,bw 是该口的读取带宽占用情况,ddrc 是总读取情况,
Write 后跟的是 ddr 的6个接口的写入情况,bw 是该口的写入带宽占用情况,ddrc 是总写入情况。
DDR有6个接口(port),分别对应:
cpu(port0)
bif dma(port1)
bpu0(port2)
bpu1(port3)
vio(port4)
other peripheral(port5)
其优先级均可通过 ddr qos 内核的接口进行配置,sysfs 节点的路径位于 /sys/devices/system/ddr_monitor。其中,read_qos_ctrl/write_qos_ctrl 分别对应 read/write 的 qos 配置,配置情况类似。

以 read 为例:

可以看到全部6个 port,我们可以通过 echo 对某个特定 port 进行配置,并且可以通过 cat 读取配置的值。每个 port 的配置范围为0~15,值越大对应的 port 优先级越高。其中,all 表示的是所有6个端口的情况,配置范围也是0~15,配置后会将6个 port 配置成同一个值。读的时候则是显示6个 port 的值。
例如:

上图如将 vio 的 read 优先级配置为 1,并读取配置的值(注意命令中的空格)。
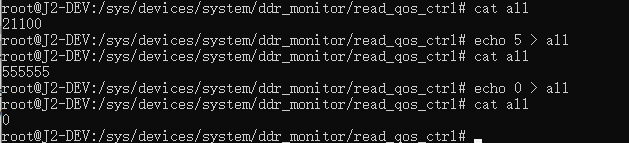
上图将所有 port 配置为5, 然后配置为0。
Note
如果输出结果以0开头,则自动略去0。
8.3.2. 查看应用信息¶
在运行应用之前,可以通过配置 config.json 文件来设置输出 log 等级,以此来控制输出的内容,设置 vlog_level 等级大于等于1即可使应用输出帧率信息,模型检测时间等。
{
"mode": 0,
"vlog_level":
0:输出init相关
1:输出init相关及性能相关
2:输出init相关、性能相关、Forward执行相关及模型输出相关
3:输出init相关、性能相关、Forward执行相关、模型输出相关及方法执行相关
}
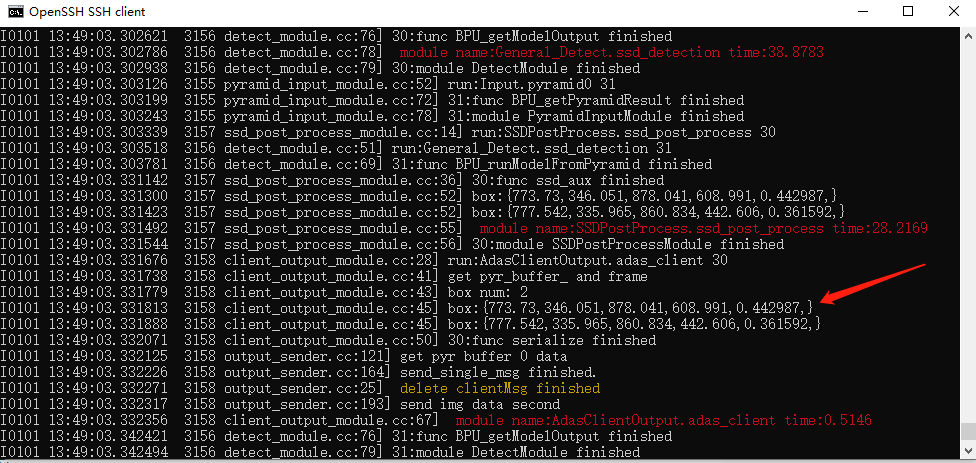
启动应用后,可以看到程序不断刷新的输出 log,如 frame_rate 为帧率,ssd_detection time 为 ssd 模型的检测处理耗时等。
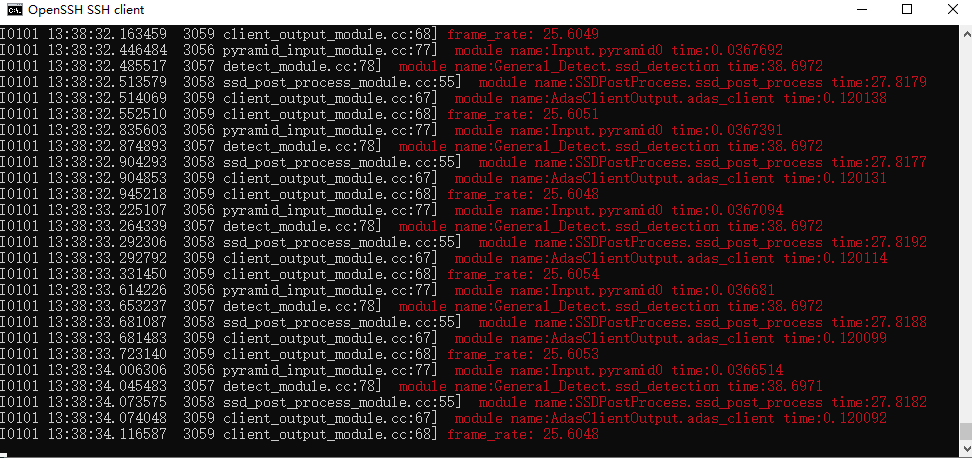
设置 vlog_level 等级大于等于3即可使应用输出检测框的坐标信息及确信度。