7. 编译器¶
7.1. 开发简介¶
本章介绍如何基于 X2/J2 开发模型、编译模型,如何用编译后的模型库开发应用,以及如何预估性能,分析瓶颈,验证数据一致性。
7.1.2. X2/J2 Compilation Tools¶
X2/J2 Compilation Tools 主要包含以下命令行工具:
- 模型编译工具
hbdk-cc 将模型(MXNet: .json 和 .params;TensorFlow:.pb)编译成目标文件(.hbm)。
- 模型链接(打包)工具
hbdk-pack 将一个或多个目标文件(.hbm)链接成模型库文件(.hbm)。
- 性能分析工具
hbdk-perf 可以根据 X2/J2 的机器指令,评估模型在 X2/J2 上的性能,包括帧率(Frame Per Second,FPS)、带宽等。
- 模型验证工具
hbdk-model-verifier 验证模型一致性。
- 模拟器
hbdk-sim 为编译产生的模型提供仿真模拟执行的环境。
7.2. 算法模型编译¶
本节主要介绍如何编译模型以及如何用模拟器运行模型。
7.2.1. 模型编译¶
编译模型的工具为 hbdk-cc,它的输入为模型文件(MXNet:.json 和 .params;TensorFlow:.pb),输出为编译后的目标文件(.hbm),目标文件包含编译后的指令与参数以及模型的描述信息。
在使用 hbdk-cc 编译 X2/J2 的模型时,主要用到如下选项:
必选选项
- -m arg
指定模型 (MXNet: *.json; TensorFlow: *.pb)。
- -o arg
指定输出文件的名字,这里的 arg 为文件名。
- --march arg
目标 BPU 微架构,支持 march:bernoulli。
MXNet 必选选项
- -p arg
指定模型参数文件。
MXNet/TensorFlow 必选选项
- -s arg
指定模型输入形状。
可选选项
- -h,--help
打印出帮助信息并退出。
- -v,--version
打印出版本信息并退出。
- -f,--framework arg
指定训练模型的框架(默认:MXNet)。
- -i,--input-source arg
指定 模型输入来源。如果输入数据是一张完整的图,通常使用 pyramid。如果输入数据是图像 ROI,通常使用 resizer。如果是非图像数据,通常使用 DDR,
pyramid,来自图像金字塔的某一层,
ddr,来自 ddr,
resizer,来自 resizer 输出 buffer,
Note
如果是 resizer 模式,shape 参数对应为 resize 之后的 shape。
- -n,--name arg
指定模型名字。
- --core-num arg
指定使用的 BPU 核数(默认值:1)。
优化选项
- --fast
优化目标为每帧执行时间最小(默认)。
- --ddr
优化目标为 DDR 访存最小。
- --O0
没有优化(默认)。
- --O1
打开 1 级优化。
- --O2
打开编译器自动性能和带宽优化。
- --O3
打开 3 级优化。
关于详细的命令行选项信息,使用命令 hbdk-cc --help 查看。
7.2.1.1. 模型输入来源¶
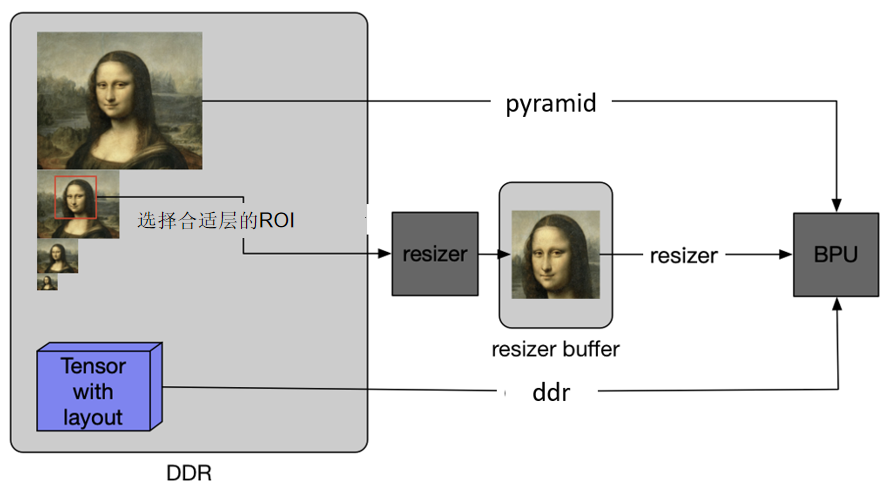
对于上板的模型,通常有三种输入数据的来源,实际项目中,需要根据实际情况进行选择:
- Pyramid
camera 送进来的图形会生成图像金字塔。图像金字塔即原图按照一定规则,缩放成不同的大小,供使用者按需使用,
- Resizer
是一种专门做图像缩放的硬件,采用 YUV420 sp 格式输入,可以改变图像的尺寸,来满足模型输入形状的要求。resizer 并不能无限放大或缩小抠图区域, 通常通过选择不同图像金字塔的层来控制抠图大小和目标大小的比例。关于 resizer 的限制,参见 5.3.5 章节 其他限制。
- DDR
通用性最好的一种形式,但对数据格式要求最严格,需要提前将数据按照 X2/J2 的数据排布要求排好,通常用于特殊模型的输入,或者 debug 场景使用。
7.2.1.2. 编译示例¶
MXNet 模型:
hbdk-cc --march bernoulli -m model_0.json -p real_0.params -s 1x540x960x3 -i ddr --O3 -o YOLOV3.hbm
TensorFlow 模型:
hbdk-cc --march bernoulli -f tf -m model_0.pb -s 1x540x960x3 -i pyramid --O3 -o YOLOV3.hbm
Note
输出 HBM 文件名使用 -o 选项指定,例如 YOLOV3,ResNet18,这里同时也是模型的名字。如果想要区分文件名和模型名,使用 -n 选项指定模型名字。
7.2.2. 模型链接(打包)¶
模型链接(打包)主要使用 hbdk-pack 工具。
hbdk-pack 输入至少一个编译好的模型目标文件(.hbm),输出一个模型目标文件(.hbm),链接(打包)后的文件包含多个模型的指令、参数以及全部的模型描述信息。
使用 hbdk-pack 工具链接多个模型会用到的选项:
- -o, --output arg
指定输出文件名。
- -h, --help
打印帮助信息并退出。
- -v, --version
打印版本信息并退出。
- --tag
为打包好的 HBM 文件打标签。标签名字上限为 63 个字节。
Note
打包生成的 hbm 文件大小应小于硬件内存的限制,可以在开发板上使用命令行 dmesg | grep “ION Carveout” 查看硬件内存空间大小限制。因为此空间还需要放其他数据,所以 hbm 文件可以使用的空间大小会略小于硬件可用的内存大小。
7.2.3. 模拟器¶
使用命令行工具 hbdk-sim 来运行编译后的模型主要用到的选项有:
- -o, --output arg
输出目录名。
- -h, --help
显示此帮助并退出。
- -v, --version
显示版本号并退出。
- -n, --model_name xxx
指定运行的模型名,“xxx” 是在运行 hbdk-cc 时指定的模型名称。 模型名保存在 hbm 文件中,此模型名可以被 hbdk-disas 查看。
- -f, --hbm model.hbm
指定模型目标文件。
- -i, --input-binary
分别指定输入数据的二进制文件,根据要运行的模型的输入需要来指定:
如果编译时使用 -i pyramid 或 -i resizer, 则指定 -i [INPUT_YUV420SP].yuv。 输入文件需要是图片的 YUV420spNV12 格式的二进制, 可以用 openCV 的 cvtColor 接口把 jpg/png 等格式的图片转换成 YUV420spNV12。
如果编译时使用 -i ddr,则指定 -i NHWC.dat, 此文件存储了 NHWC 格式的输入数据的二进制。
- --perf
模拟器会将模型性能信息打印到 stdout,例如:帧率、加载/存储带宽,运行时间等。
- --core-id arg
运行该模型的BPU core id,默认值:0。
core id 1:在BPU core 1 上运行。
core id 0,1:在BPU core 0 和 1 上并行运行。
core id 1,0:在BPU core 0 和 1 上并行运行。
- --input-source arg
所有输出来源(ddr/resizer/pyramid),多个用英文逗号分隔。 需要与生成 hbm 时 hbdk-cc 指定的输入来源一致。
- --yuv-size arg
所有输入 YUV 图片的大小(HxW),多个用英文逗号分隔。 此选项只对 pyramid 和 resizer 输入来源有效。
- --yuv-stride arg
所有输入 YUV 图片的间隔(stride(HxW)),多个用英文逗号分隔。 此选项只对 pyramid 和 resizer 输入来源有效。
- --yuv-roi-coord arg
所有输入 YUV 图片的 Roi 坐标(HxW),多个用英文逗号分隔。 此选项只对 pyramid 和 resizer 输入来源有效。
- --yuv-roi-size arg
所有输入 YUV 图片的 Roi 大小(HxW),多个用英文逗号分隔。 此选项只对 pyramid 和 resizer 输入来源有效。对于 pyramid 输入来源,必须匹配模型的输入尺寸。
关于选项详情,输入命令 hbdk-sim --help 进行查看。
7.2.3.1. 模拟器示例¶
hbdk-sim -f YOLOV3.hbm -n YOLOV3 -i YOLOV3_input.yuv --input-source pyramid --yuv-size 704x1280 --yuv-stride 1280 --yuv-roi-coord 10x20 --yuv-roi-size 540x960
7.2.4. 编译、链接和模拟器示例¶
针对 X2/J2 平台,编译并链接模型:
MXNet 模型:
hbdk-cc --march bernoulli -m model_0.json -p real_0.params -s 1x540x960x3 -i ddr --O3 -o YOLOV3.hbm
hbdk-cc --march bernoulli -m model_1.json -p real_1.params -s 1x128x128x3 -i ddr --O3 -o ResNet18.hbm
hbdk-pack YOLOV3.hbm ResNet18.hbm -o model.hbm
Tensorflow 模型:
hbdk-cc --march bernoulli -f tf -m model_0.pb -s 1x540x960x3 -i pyramid --O3 -o YOLOV3.hbm
hbdk-cc --march bernoulli -f tf -m model_1.pb -s 1x128x128x3 -i resizer --O3 -o ResNet18.hbm
hbdk-pack YOLOV3.hbm ResNet18.hbm -o model.hbm
运行模拟器:
hbdk-sim -f YOLOV3.hbm -n YOLOV3 -i YOLOV3_input.yuv --input-source pyramid --yuv-size 704x1280 --yuv-stride 1280 --yuv-roi-coord 10x20 --yuv-roi-size 540x960
hbdk-sim -f ResNet18.hbm -n ResNet18 -i ResNet18_input.yuv --input-source resizer --yuv-size 704x1280 --yuv-stride 1280 --yuv-roi-coord 224x430 --yuv-roi-size 93x99
Note
模拟器(以及真实的 BPU 开发板)的 pyramid 和 resizer 输入为 YUV420SP(即 NV12)格式。关于 YUV420SP 格式,请参考 NV12 yuv pixel format。
有许多在线或离线的工具可以将 jpeg 或 png 格式的图片转换为 NV12。例如,可以使用 openCV 库的 cvtColor 函数或 ffmpeg 进行格式转换。关于 cvtColor 使用,参见 OpenCV 官方文档:cvtColor - OpenCV 文档。关于 ffmpeg 使用,参见 ffmpeg yuv to jpeg and jpeg to yuv。
7.3. 模型性能分析¶
在模型设计好之后,想了解模型能跑多快,可以使用 hbdk-perf 命令行工具。这个工具分析 hbm 文件里编译好的模型,基于指令序列预估模型整体性能,包括帧率、延迟、访存带宽、计算量、MAC 利用率等。如果模型是用 -g 编译的,还可以输出网络每一层的详细信息。
Note
该软件预估结果接近实际上板时的真实性能(偏差一般小于5%)。该工具目前仅支持非异构的模型。
使用示例:
hbdk-perf models.hbm -o output_directory
这个命令会分析 model.hbm 里的所有模型,在 output_directory 目录里生成若干报告。其中,
- -o
指定输出报告的路径,默认是当前目录。
关于选项详情,输入命令 hbdk-perf --help 查看。
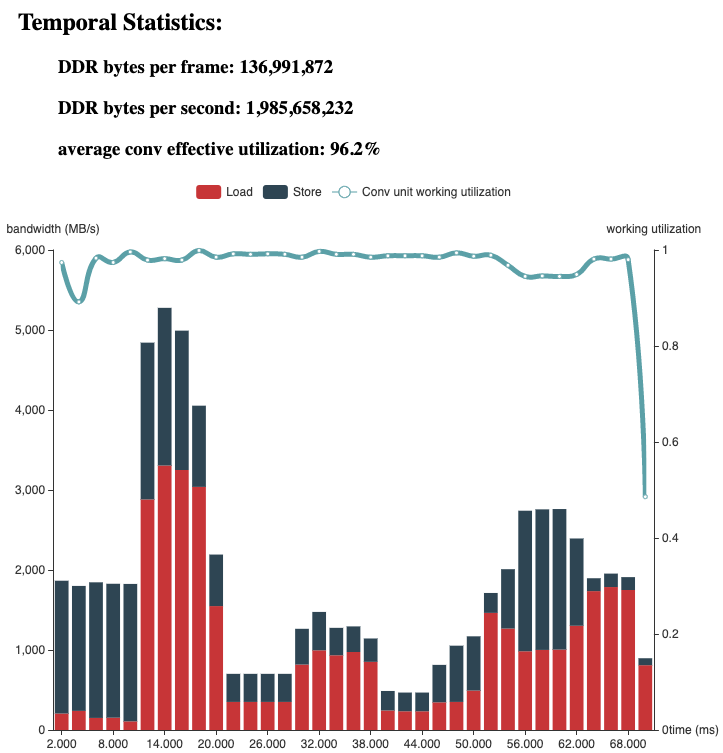
可得到如下的性能分析结果(节选自 {model_name}.json 中的 summary):
"summary": {
"BPU OPs per frame (effective)": 27105689600,
"BPU march": "bernoulli",
"BPU utilization (effective)": 0.962,
"DDR megabytes per frame": 130.646,
"FPS": 14.5
}
此外,hbdk-perf 会输出模型性能分析的 html 文件({model_name}.html),帮助可视化分析模型的详细性能:
7.4. 模型验证¶
对于许多场景,验证从 HBM 文件中获取的推理结果与从预测库获取的推理结果的一致性非常重要。为了加速应用的开发和故障定位过程,我们提供一个命令行工具来辅助一致性验证。可以在模型部署之前使用这个工具来确保模型的运行时行为与预测库一致。也可以在应用开发过程中针对特定输入数据使用这个工具来辅助故障定位。本节将介绍这个工具的依赖及使用方法,并通过举例来帮助理解工具的主要参数。
使用这个工具之前需要先安装一个独立的 wheel 包 hbdk_model_verifier 。在安装后,可以通过命令行 hbdk-model-verifier 调用此工具。这个工具包含两个可执行程序来在 BPU 开发板和模拟器中利用 HBM 文件进行前向推理。其中也包括一些 python 脚本来进行结果的解析和对比。
需要注意的是由 DETECTION_POST_PROCESS 等一系列操作产生的结果在 BPU 和预测库中是以不同的格式存储的。如果用户需要搭建自己的一致性验证环境,必须要小心处理这些格式上的差异。相关细节请参考 verify.py 或者 模型部署 。
在运行 hbdk_model_verifier 之前,请确保环境中已安装以下依赖:
7.4.1. 环境依赖¶
hbdk 和 hbdk-model-verifier 版本兼容。
BPU开发板上搭载了最新的系统镜像。
开发板的 /usr/lib 路径或者 LD_LIBRARY_PATH 路径中含有 BPU 系统软件库 libcnn_intf.so , libvio.so 和 libfb.so 。
工具运行在 python3.6 环境中,python 环境需要预编译 openssl。
以下是 hbdk-model-verifier 的命令行参数。
7.4.2. 命令行选项¶
usage: hbdk-model-verifier [-h] --model-input MODEL_INPUT --hbm HBM
--model-name MODEL_NAME [--yuv-shape YUV_SHAPE]
[--model-json MODEL_JSON]
[--model-param MODEL_PARAM] [--model-pb MODEL_PB]
[--roi-coord ROI_COORD] [--roi-size ROI_SIZE]
[--vio-config VIO_CONFIG]
[--pyramid-ds-factor PYRAMID_DS_FACTOR]
[--local-work-path LOCAL_WORK_PATH]
[--remote-work-path REMOTE_WORK_PATH] [--ip IP]
[--username USERNAME] [--password PASSWORD]
[--port PORT] [--skip-bpu] [--force-run-simulator]
[--version]
验证 Horizon BPU 部署的模型一致性的工具。
可选参数
- -h, --help
显示帮助信息并退出。
- --model-input MODEL_INPUT
(必需)模型输入数据。支持 jpg/png/yuv 格式图像文件或 int8 二进制/文本张量数据。
- --hbm HBM
(必需)包含需要验证的模型的 hbm 文件。
- --model-name MODEL_NAME
(必需)用于验证的模型名称。
- --yuv-shape YUV_SHAPE
yuv 图像大小。HxW 格式中应为 string。
- --model-json MODEL_JSON
MXNet 模型 Json 路径。
- --model-param MODEL_PARAM
MXNet 模型 param 路径。
- --model-pb MODEL_PB
Tensorflow 模型 protobuffer 路径
- --roi-coord ROI_COORD
resizer 模型 roi 坐标,[HxW]
- --roi-size ROI_SIZE
resizer 模型 roi 大小,[HxW]
- --vio-config VIO_CONFIG
pyramid/resizer 模型 vio 配置文件。
- --pyramid-ds-factor PYRAMID_DS_FACTOR
输入层 pyramid 下采样系数。
- --local-work-path LOCAL_WORK_PATH
本地路径,用于存储临时数据和最终结果。默认:“.”。
- --remote-work-path REMOTE_WORK_PATH
远程 BPU路径,用于存储临时数据。默认:/userdata。
- --ip IP
远程 BPU IP 地址。
- --username USERNAME
远程 BPU 登录用户名,默认:root。
- --password PASSWORD
远程 BPU 登录密码,默认无密码。
- --port PORT
远程 BPU 登录端口,默认端口号:22。
- --skip-bpu
使用模拟器代替 BPU 执行。
- --force-run-simulator
运行模拟器,并将结果添加至比较结果。
- --version
显示程序版本号,并退出。
输入相关的选项
对于用选项 -i/--input-source pyramid/resizer 编译的模型,输入数据必须是图片,支持 jpg,png 和 nv12 格式的图片。当输入 jpg 或者 png 时,会调用 openCV 的接口来将图片转换到 YUV 颜色空间。如果输入 nv12 格式的图片,则不会发生任何数据预处理。
对于用选项 -i/--input-source ddr 编译的模型,输入数据可以是二进制或者文本。
- --model-input
(必需)输入数据,可以是 jpg、png 和 nv12 格式的图片或二进制或文本格式的张量数据。图片的宽必须和模型的输入张量宽度一致,图片的高可以稍大于模型输入张量的高。例如,模型输入分辨率为 704x1280,输入图像的分辨率可以为 720x1280。
- --yuv-shape
(可选,nv12 输入为必需)如果 yuv 图像作为模型输入给出,图像的大小必须由该选项指定。该选项的参数应为 string, 格式为 HxW,其中 H 和 W 是图像的高和宽。
图像金字塔和resizer相关的选项
如果想要在图像金字塔上选择某一层或者某个 ROI 作为模型的输入,可以使用以下选项。
- --vio-config
(可选,如指定 pyramid-ds-factor 则为必需)BPU vio 模型的配置文件。该工具从中读取 pyramid 配置文件。关于该文件详情,参见《MU-2020-1-C-X2J2平台系统软件接口手册》4.6 VIO 配置文件说明。
- --pyramid-ds-factor
(可选)图像金字塔可以生成上采样、下采样和基于 ROI 的下采样层。但是该工具仅支持主要下采样层的输入数据。例如,base 图像大小为 720x1280,--pyramid-ds-factor 4 意为从第 1/4 层获取输入,且输入数据为 180x320。
- --roi-coord
(可选,对于 resizer model 为必需)BPU resizer 的 ROI 的起点坐标。该参数应为 string,格式为 HxW, 其中 H 为起始线 index,w 为 起始 column index。
- --roi-size
(可选,对于 resizer model 为必需)BPU resizer 的 ROI 大小。参数应为 string,格式为 HxW,其中 H 和 W 是 ROI 的高和宽。
模型相关的选项
- --hbm
(必需)模型 hbm 文件。
- --model-name
(必需)需验证的模型名称。
- --model-json
(可选,MXNet 模型必需)MXNet 模型结构 json 文件,由 Gluon Horizon 输出。
- --model-param
(可选,MXNet 模型必需)MXNet 模型参数文件。
- --model-pb
(可选,Tensorflow 模型必需)TensorFlow 模型 pb 文件,由 Horizon TensorFlow Plugin 输出。
开发板相关的选项
- --ip
(可选,如不设置 --skip-bpu 则为必需)开发板 IP。
- --username
(可选,默认使用 root)用户名,用于登录开发板。
- --password
(可选,默认没有密码)密码,用于登录开发板。
- --port
(可选,默认 22)端口,用于连接开发板。
其他选项
- --remote-work-path
(可选,默认 /userdata)存储临时文件到 BPU 开发板的路径。该路径必须提前创建。
- --local-work-path
(可选,默认 ‘.’)本地路径,用于存储结果。
- --force-run-simulator
(可选,默认 false)设置该 flag 来运行 BPU 模拟器。
- --skip-bpu
(可选,默认 false)用 BPU 模拟器来代替 BPU 开发板。只比较训练库和 BPU 模拟器产生的结果。
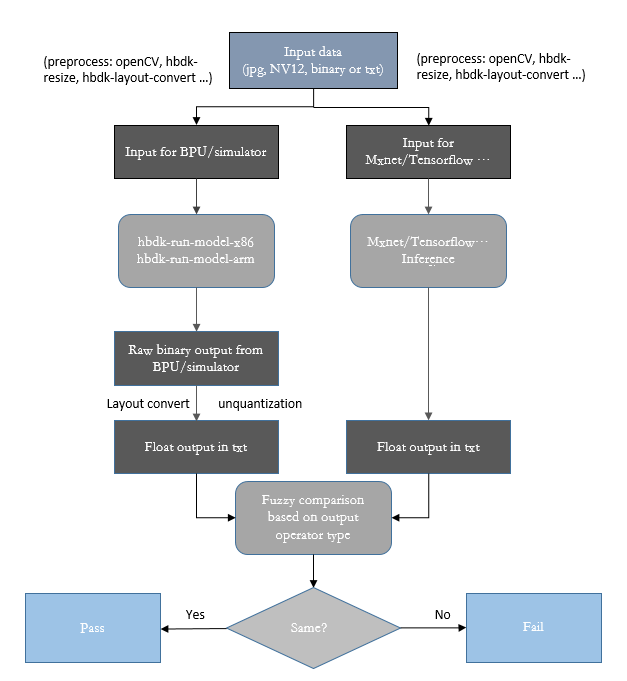
hbdk-model-verifier 的简要工作流程如下图。它会对输入数据做一些必要的预处理,然后将数据送给预测库和一个基于运行时接口的测试程序分别做前向预测。然后它会取回双方预测的结果并逐一对比。
7.4.3. 示例¶
以下为示例展示如何使用该工具排查应用故障。
假设应用使用SSD模型来做目标检测,BPU 开发板连接了一个 1080P 的摄像头,检测模型以图像金字塔的 1/2 下采样层作为输入。
作为应用开发者,当发现检测结果中漏掉了一些目标时,第一步应该是将出错帧的图像存储下来,然后使用这一帧图像作为输入来运行 hbdk-model-verifier:
hbdk-model-verifier --hbm ssd.hbm --model-name ssd --model-input sample_input.jpg --model-json mobilenetv1_1_0_voc_infer-symbol.json --model-param mobilenetv1_1_0_voc_infer-0000.params --ip 10.33.23.127
11-05-2019 21:21:14 root:INFO:======> Parse cmd done
11-05-2019 21:21:14 root:INFO:======> Check HBDK tool existence
11-05-2019 21:21:14 root:INFO:executing cmd: which hbdk-config
11-05-2019 21:21:14 root:INFO:executing cmd: which hbdk-disas
11-05-2019 21:21:14 root:INFO:executing cmd: which hbdk-cc
11-05-2019 21:21:14 root:INFO:executing cmd: hbdk-cc --version
11-05-2019 21:21:15 root:INFO:executing cmd: hbdk-config --aarch64-link-dir
11-05-2019 21:21:15 root:INFO:======> HBDK tools all detected
11-05-2019 21:21:15 root:INFO:executing cmd: hbdk-disas ssd.hbm
11-05-2019 21:21:15 root:INFO:======> Preprocess BPU Input Data
11-05-2019 21:21:15 root:INFO:======> Preprocess BPU Input Data Done
11-05-2019 21:21:15 root:INFO:======> Try to connect BPU
11-05-2019 21:21:15 paramiko.transport:INFO:Connected (version 2.0, client dropbear_2018.76)
11-05-2019 21:21:16 paramiko.transport:INFO:Authentication (password) failed.
11-05-2019 21:21:16 paramiko.transport:INFO:Authentication (none) successful!
11-05-2019 21:21:16 paramiko.transport.sftp:INFO:[chan 0] Opened sftp connection (server version 3)
11-05-2019 21:21:16 root:INFO:======> BPU connected
11-05-2019 21:21:16 root:INFO:REMOTE: executing [mkdir -p /userdata/hbdk_model_verifier_20191105212114]
11-05-2019 21:21:17 root:INFO:REMOTE: executing [mkdir /userdata/hbdk_model_verifier_20191105212114/bpu_output]
11-05-2019 21:21:18 root:INFO:Uploading ssd.hbm to /userdata/hbdk_model_verifier_20191105212114/ssd.hbm
11-05-2019 21:21:20 root:INFO:Uploading libhbrt_bernoulli_aarch64.so to /userdata/hbdk_model_verifier_20191105212114/libhbrt_bernoulli_aarch64.so
11-05-2019 21:21:21 root:INFO:Uploading hbdk-run-model-aarch64 to /userdata/hbdk_model_verifier_20191105212114/hbdk-run-model-aarch64
11-05-2019 21:21:23 root:INFO:Uploading bpu_input_0.yuv to /userdata/hbdk_model_verifier_20191105212114/bpu_input_0.yuv
11-05-2019 21:21:23 root:INFO:REMOTE: executing [cd /userdata/hbdk_model_verifier_20191105212114 && chmod u+x hbdk-run-model-aarch64 && export HBRT_LOG_LEVEL=99 && flock -x /tmp/hbdk_model_verifier.lock ./hbdk-run-model-aarch64 -i bpu_input_0.yuv -f ssd.hbm -n ssd -p None -o /userdata/hbdk_model_verifier_20191105212114/bpu_output]
11-05-2019 21:21:24 root:WARNING:receive following warnings from remote BPU:
11-05-2019 21:21:24 root:WARNING:warning: yuv_img_size is not provided. Use input shape [540x960] by default.
11-05-2019 21:21:24 root:WARNING:warning: roi for yuv input [bpu_input_0.yuv] is not provided. Set the entire image as ROI.
11-05-2019 21:21:24 root:INFO:
======> BPU model execution time: 63.101000 ms
11-05-2019 21:21:24 root:INFO:REMOTE: executing [cd /userdata/hbdk_model_verifier_20191105212114 && tar -cvf bpu_output.tar bpu_output]
11-05-2019 21:21:25 root:INFO:Downloading /userdata/hbdk_model_verifier_20191105212114/bpu_output.tar to /hbdk_model_verifier_20191105212114/bpu_output.tar
11-05-2019 21:21:26 root:INFO:REMOTE: executing [rm -r /userdata/hbdk_model_verifier_20191105212114]
11-05-2019 21:21:27 root:INFO:executing cmd: tar -xvf bpu_output.tar
11-05-2019 21:21:27 root:INFO:executing cmd: rm bpu_output.tar
11-05-2019 21:21:28 root:INFO:======> Preprocess Framework Input Data
11-05-2019 21:21:34 root:INFO:======> Preprocess Framework Input Data Done
11-05-2019 21:21:34 root:INFO:======> Run Model by hbdk-pred
11-05-2019 21:21:34 root:INFO:executing cmd: hbdk-pred -s 1x540x960x3 -o framework_output -b framework_input_0.bin --gen-txt-output --march bernoulli -m mobilenetv1_1_0_voc_infer-symbol.json -p mobilenetv1_1_0_voc_infer-0000.params
11-05-2019 21:21:39 root:WARNING:receive following warning from hbdk-pred
11-05-2019 21:21:39 root:WARNING:[21:21:36] src/c_api/c_predict_api.cc:460: stale arg param of data for binding.
11-05-2019 21:21:39 root:INFO:======> Compare Results on BPU Board vs. Framework
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_clspredict0_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_clspredict1_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_clspredict2_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_clspredict3_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_clspredict4_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_clspredict5_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_boxpredict0_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_boxpredict1_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_boxpredict2_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_boxpredict3_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_boxpredict4_conv_output.txt] is same.
11-05-2019 21:21:40 root:INFO: [SUCCESS] output file [hbdk_output_train_ssd_boxpredict5_conv_output.txt] is same.
验证结果会打印到控制台。这里所有 BPU 模拟器的输出和预测库的输出都是一致的。如果模型通过了 hbdk-model-verifier 的一致性验证,那么应用的故障很可能是出在数据的预处理,输出数据的后处理或者其余应用代码中。也有可能是这个模型的精度本来就不太好。如果模型没有通过 hbdk-model-verifier 的一致性验证,可能的原因包括输入数据的尺寸不匹配,hbm 的版本和当前环境中的 hbdk 版本不兼容等。大多数原因都可以在工具打印出来的警告中发现线索。如果无法确定是什么原因导致了验证失败,请联系技术人员提供更多支持。
验证过程产生的模拟器输出和预测库输出全都会在当前路径或者参数 --local-output-path 指定的路径中存储下来。可以用这些结果与应用中实时产生的结果做对比。
.
├── bpu_input_0.yuv
├── bpu_output
│ ├── hbdk_output0_feature_train_ssd_clspredict0_conv_output_elem_float.txt
│ ├── hbdk_output0_feature_train_ssd_clspredict0_conv_output_elem_int.txt
│ ├── hbdk_output10_feature_train_ssd_boxpredict4_conv_output_elem_float.txt
│ ├── hbdk_output10_feature_train_ssd_boxpredict4_conv_output_elem_int.txt
│ ├── hbdk_output11_feature_train_ssd_boxpredict5_conv_output_elem_float.txt
│ ├── hbdk_output11_feature_train_ssd_boxpredict5_conv_output_elem_int.txt
│ ├── hbdk_output1_feature_train_ssd_clspredict1_conv_output_elem_float.txt
│ ├── hbdk_output1_feature_train_ssd_clspredict1_conv_output_elem_int.txt
│ ├── hbdk_output2_feature_train_ssd_clspredict2_conv_output_elem_float.txt
│ ├── hbdk_output2_feature_train_ssd_clspredict2_conv_output_elem_int.txt
│ ├── hbdk_output3_feature_train_ssd_clspredict3_conv_output_elem_float.txt
│ ├── hbdk_output3_feature_train_ssd_clspredict3_conv_output_elem_int.txt
│ ├── hbdk_output4_feature_train_ssd_clspredict4_conv_output_elem_float.txt
│ ├── hbdk_output4_feature_train_ssd_clspredict4_conv_output_elem_int.txt
│ ├── hbdk_output5_feature_train_ssd_clspredict5_conv_output_elem_float.txt
│ ├── hbdk_output5_feature_train_ssd_clspredict5_conv_output_elem_int.txt
│ ├── hbdk_output6_feature_train_ssd_boxpredict0_conv_output_elem_float.txt
│ ├── hbdk_output6_feature_train_ssd_boxpredict0_conv_output_elem_int.txt
│ ├── hbdk_output7_feature_train_ssd_boxpredict1_conv_output_elem_float.txt
│ ├── hbdk_output7_feature_train_ssd_boxpredict1_conv_output_elem_int.txt
│ ├── hbdk_output8_feature_train_ssd_boxpredict2_conv_output_elem_float.txt
│ ├── hbdk_output8_feature_train_ssd_boxpredict2_conv_output_elem_int.txt
│ ├── hbdk_output9_feature_train_ssd_boxpredict3_conv_output_elem_float.txt
│ └── hbdk_output9_feature_train_ssd_boxpredict3_conv_output_elem_int.txt
├── filetree
├── framework_input_0.bin
├── framework_output
├── hbdk_output_train_ssd_boxpredict0_conv_output.txt
├── hbdk_output_train_ssd_boxpredict1_conv_output.txt
├── hbdk_output_train_ssd_boxpredict2_conv_output.txt
├── hbdk_output_train_ssd_boxpredict3_conv_output.txt
├── hbdk_output_train_ssd_boxpredict4_conv_output.txt
├── hbdk_output_train_ssd_boxpredict5_conv_output.txt
├── hbdk_output_train_ssd_clspredict0_conv_output.txt
├── hbdk_output_train_ssd_clspredict1_conv_output.txt
├── hbdk_output_train_ssd_clspredict2_conv_output.txt
├── hbdk_output_train_ssd_clspredict3_conv_output.txt
├── hbdk_output_train_ssd_clspredict4_conv_output.txt
└── hbdk_output_train_ssd_clspredict5_conv_output.txt
7.5. 其他实用工具¶
7.5.1. hbdk-disas¶
将模型编译的目标文件 .hbm 反汇编,.hbm 文件格式是地平线自定义文件格式,包含模型名字、模型编译选项、模型文件和参数文件的 crc 校验码、输入输出特征信息、段信息,以及 BPU 指令和数据信息。该工具以可读地形式显示除 BPU 指令和数据以外的其他信息。
可选选项
-o,--output arg 输出文件名字
-h,--help 打印出帮助信息并退出
-v,--version 打印出版本信息并退出
示例
hbdk-disas model.hbm
反汇编 model.hbm。
7.5.2. hbdk-layout-convert¶
数据排布转换工具。数据排布 是 X2/J2 硬件特殊的要求。该工具将输入图片(NV12)/二进制排布转换成另一种排布格式。
必选选项
- --src-dim arg
输入数据维度(NxHxWxC)
- --dst-dim arg
输出数据维度(NxHxWxC)
- --src-layout arg
输入数据排布
- --dst-layout arg
输出数据排布
- --src-file arg
输入数据文件
- --dst-file arg
输出数据文件
可选选项
- --element-size arg
元素所占字节数,可选1,2,4,8,默认值:1
- --convert-endian
转换输入数据的大小端
- -h,--help
打印出帮助信息并退出
- -v,--version
打印出版本信息并退出
支持的数据排布及数据对齐要求
数据排布详情,参见 数据排布。
数据排布名称 |
数据对齐 |
NCHW_8C |
1x1x1x8 |
NHCW_16W16C |
1x1x16x16 |
NHCW_16W16C_S2D |
1x1x32x16 |
NHCW_32C |
1x1x1x32 |
NHCW_8W4C |
1x1x8x4 |
NHCW_8W4C_S2D |
1x1x16x4 |
NHCW_32W2C |
1x1x32x2 |
NHWC_4W8C |
1x1x4x8 |
NHWC_NATIVE |
1x1x1x1 |
YUV |
(NV12) |
示例
hbdk-layout-convert --src-dim 1x128x128x3 --dst-dim 1x128x128x3 --src-layout NV12 --dst-layout NHWC_NATIVE --src-file nv12.yuv --dst-file input_native.bin
将大小为 1x128x128x3、排布为 nv12 的数据转为 NHWC_NATIVE。
7.5.3. hbdk-resize¶
调整图片(NV12)大小,也可以调整 ROI(Region Of Interest)大小,ROI 允许超出原图像的边界。
必选选项
- --march arg
目标 BPU 微架构,支持 march:bernoulli。
- --src-size arg
整个输入图像(NV12)的尺寸(HxW)。
- --dst-size arg
整个输出图像(NV12)的尺寸(HxW)。
- --src-file arg
输入(NV12)图像文件名。
- --dst-file arg
输出(NV12)图像文件名。
可选选项
- --roi-coord arg
需要调整输入 ROI 在原图中的坐标(HxW)。
- --roi-size arg
需要调整输入 ROI 的尺寸(HxW)。
- -h,--help
打印出帮助信息并退出。
- -v,--version
打印出版本信息并退出。
示例
hbdk-resize --march x2 --src-size 540x960 --dst-size 128x128 --src-file tmp_default_options/input_0_pyramid_960x540_nv12.yuv --dst-file tmp_default_options/input_0_small_box_128x128_nv12.yuv --roi-coord 174x384 --roi-size 192x192
在 X2 上,将大小为 540x960 的原图中坐标为(174,384)、大小为 192x192 的 ROI,调整大小为 128x128 的图像。
7.5.4. hbdk-config¶
打印 HBDK 工具多种路径信息和编译选项, 该工具可用于配置 HBDK 工具使用脚本。
可选选项
- -h,--help
打印出帮助信息并退出。
- --prefix
打印 HBDK 安装根路径。
- --bin-prefix
打印 HBDK 可执行文件路径。
- --include-dir
打印 HBDK 头文件路径。
- --includes
打印包含 HBDK 头文件的编译选项。
- --aarch64-ldflags,--aarch64-links
打印链接 HBDK aarch64 库的编译选项。
- --aarch64-link-dir
打印 HBDK aarch64 库路径。
- --x86-sim-ldflags,--x86-sim-links
打印链接 HBDK x86模拟器库的编译选项。
- --x86-sim-link-dir
打印 HBDK x86模拟器库的路劲。
- --version
打印 HBDK 的版本信息并退出。
- --public-version
打印 HBDK 公开版本信息并退出。
- --hbdktest-cmake-file
打印 hbdktest CMake 文件的路径。
示例
export PATH=`hbdk-config --bin-prefix`:$PATH
将 HBDK 可执行文件路径加到 PATH 环境变量中。
7.6. 模型部署¶
本节介绍 HBDK 的运行时机制与应用程序接口。
HBDK 的运行时为上层应用提供了一些列应用程序接口。这些接口可以用来解析 HBM 文件,获取 HBM 文件中的模型信息以及运行模型和获取相应的结果。这些应用程序接口以动态库 libhbrt_bernoulli_aarch64.so 的形式提供,这个动态库可以在 HBDK 的 wheel 包的 lib64/aarch64 目录下找到,也可以在安装了 HBDK 的 python 环境中通过命令 hbdk-config --aarch64-link-dir 获得这个动态库的路径。相关的头文件在 wheel 包的 include 目录下,也可以通过命令 hbdk-config --include-dir 获取头文件路径。
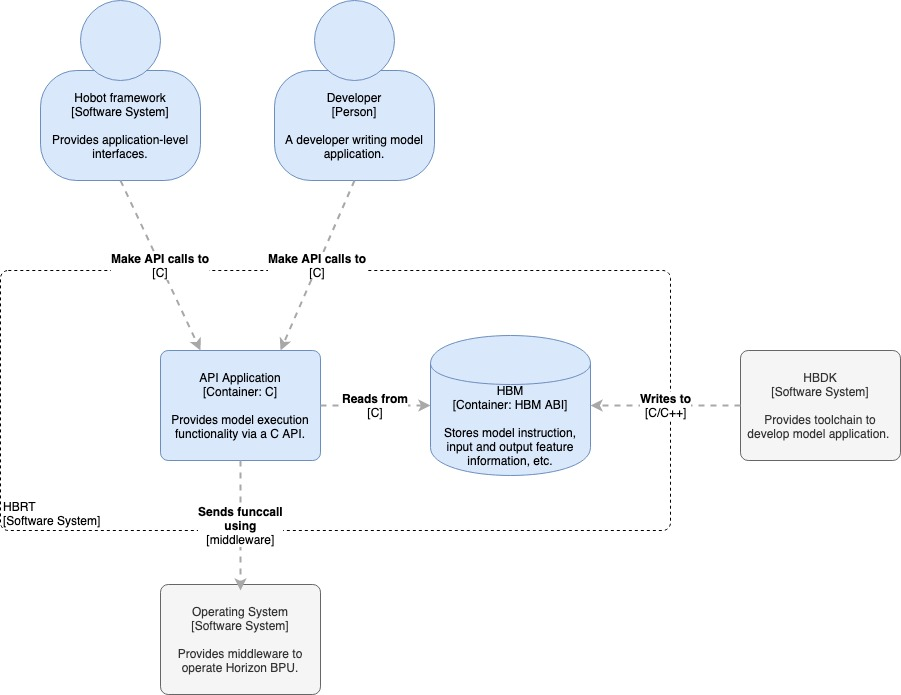
在开发实际应用时,由若干依赖库是必须的。如上图所示,实际应用至少需要 BPU 的驱动库(由 libcnn_intf.so,libvio.so 等组成),HBDK 的运行时库,含有一个或多个模型的 HBM 文件等。HBDK 的运行时将会运行在应用程序代码与 BPU 的驱动之间。
7.6.1. 概念¶
在正式介绍具体的应用程序接口前,我们先引入以下概念,这些概念将有助于理解 HBDK 的运行时机制。
运行实例(Running instance):我们把一个模型的一次前向预测的过程称为一个运行实例。HBDK 运行时使用一系列的数据结构来记录模型运算的状态与上下文。模型的输入/输出地址,当前的执行状态以及其他的信息也被记录在这些数据结构中。由于整个系统的内存限制,HBDK 运行时最多可以处理 256 个并发的运行实例。
数据排布(Data layout):为了加速 BPU 的计算,一些模型的输入/输出会被以特殊的排布来存储。例如,模型的输出可能被组织成 8 像素 4 通道的数据块的形式。关于数据排布的细节,请参考 HBDK 运行时 API。
特征图的维度(Feature map dimension):在 HBDK 的运行时机制中,所有的特征图(feature map)都被当作 4 维张量(NxHxWxC)处理。在一些框架中有些特征图不是 4 维的,这些特征图的维度会被扩展或者压缩到 4 维。例如 Detection_post_process 的 im_info 输入在 MXNet 框架中是一个 3 维张量(Nx1x2),在 HBDK 运行时中它会被扩展成 Nx1x1x2。
模型段(Segment):对基于 bernoulli 架构的 BPU 来说,有一些运算不能被芯片原生地支持,HBDK 运行时为其中的一部分运算提供了高效的 ARM 实现或者对 BPU 的即时编译。在静态编译过程中,若模型的某一层将会在CPU上执行或者即时编译,相关的提示将会在控制台中打印出来。在编译后,整个模型会被拆分为若干个模型段,每一个模型段都包含 CPU 或者 BPU 指令来执行模型中某几层的运算。
函数调用(Functioncall):BPU 的计算由 functioncall 来触发。一个 functioncall 会设置一些寄存器并告知BPU相关的指令地址。每一个在 BPU 上执行的模型段都会包含一个或多个 functioncall。
HBDK运行时的应用程序接口遵循以下编码规则:
所有的接口都会返回一个状态码。hbrtSuccess 表示相关的接口正常退出,其余状态则表示相关接口内部发生了错误。
接口的参数列表中输出相关的参数放在前面。
所有的接口都不会故意阻塞或者中断调用线程。
本节剩下的部分将逐一介绍HBDK运行时中主要的接口。查看 API 的完整列表与使用方法,参见 HBDK 运行时 API。
7.6.2. 加载/卸载 HBM¶
使用以下接口来将 HBM 文件加到到 BPU 内存中。
HBDK_PUBLIC extern hbrt_error_t hbrtLoadHBMFromFile(hbrt_hbm_handle_t *hbm_handle, const char *hbm_path);
和其他的大多数接口一样,这个接口会返回一个句柄,这个句柄可以当作 HBM 文件的标识符。在 HBM 的加载过程中,BPU 的指令和模型参数将会被传输到 BPU 内存中。用来记录模型运行时所需信息的数据结构将会被从 HBM 文件中取出并存储在 CPU 内存。同时,HBDK 运行时也会自动检查 HBM 文件的完整性和与当前运行时动态库的兼容性。
在某个时刻,若应用程序不再需要某个 HBM 文件中的任何模型,可以调用以下接口来释放该 HBM 占用的 BPU 内存。
HBDK_PUBLIC extern hbrt_error_t hbrtOffloadHBM(hbrt_hbm_handle_t hbm_handle);
7.6.3. 获取模型信息¶
有许多接口可以用来获取 HBM 文件中的模型信息。例如,通过以下接口,可以查询 HBM 文件中的模型数量和这些模型的名称。
HBDK_PUBLIC extern hbrt_error_t hbrtGetModelNumberInHBM(uint32_t *model_number, hbrt_hbm_handle_t hbm_handle);
HBDK_PUBLIC extern hbrt_error_t hbrtGetModelNamesInHBM(const char ***model_names, hbrt_hbm_handle_t hbm_handle);
通过以下接口,可以使用名称来获取对应模型的句柄。
HBDK_PUBLIC extern hbrt_error_t hbrtGetModelHandle(hbrt_model_handle_t *model_handle, hbrt_hbm_handle_t hbm_handle, const char *model_name);
而使用模型的句柄,又可以查询该模型输入/输出的数量,获取输入/输出的特征图的句柄,以及查询模型的预估延迟等。
HBDK_PUBLIC extern hbrt_error_t hbrtGetInputFeatureNumber(uint32_t *input_number, hbrt_model_handle_t model_handle);
HBDK_PUBLIC extern hbrt_error_t hbrtGetInputFeatureHandles(const hbrt_feature_handle_t **feature_handle, hbrt_model_handle_t model_handle);
HBDK_PUBLIC extern hbrt_error_t hbrtGetOutputFeatureNumber(uint32_t *output_number, hbrt_model_handle_t model_handle);
HBDK_PUBLIC extern hbrt_error_t hbrtGetOutputFeatureHandles(const hbrt_feature_handle_t **feature_handle, hbrt_model_handle_t model_handle);
HBDK_PUBLIC extern hbrt_error_t hbrtGetModelEstimatedLatency(uint32_t *latency, hbrt_model_handle_t model_handle);
利用特征图的句柄,可以查询特征图的有效尺寸,在 BPU 中对齐后的尺寸,数据类型,产生该特征图的操作的类型等。
HBDK_PUBLIC extern hbrt_error_t hbrtGetFeatureValidDimension(hbrt_dimension_t *dim, hbrt_feature_handle_t feature_handle);
HBDK_PUBLIC extern hbrt_error_t hbrtGetFeatureAlignedDimension(hbrt_dimension_t *dim, hbrt_feature_handle_t feature_handle);
HBDK_PUBLIC extern hbrt_error_t hbrtGetFeatureElementType(hbrt_element_type_t *element_type, hbrt_feature_handle_t feature_handle);
HBDK_PUBLIC extern hbrt_error_t hbrtGetFeatureOperatorType(hbrt_output_operator_type_t *type, hbrt_feature_handle_t feature_handle);
7.6.4. 模型执行¶
用户需要通过调用以下接口启动一个运行实例来触发模型的前向预测。
HBDK_PUBLIC extern hbrt_error_t hbrtRiStart(void **p_funccall_buffer, uint32_t *generated_funccall_num, hbrt_model_handle_t model_handle, const hbrt_ri_input_info_t *input_infos, const hbrt_ri_config_t *ri_config, uint32_t ri_id, uint32_t interrupt_number);
这个接口会返回一个写有若干 functioncall 的缓冲区地址。这个地址可以直接作为 BPU 驱动库接口 cnn_core_set_fc 或 cnn_core_set_fc_group 的输入参数。HBDK运行时负责对改缓冲区的管理,相应的内存会在调用 hbrtRiDestroy 时得到释放,调用者的代码中不应该再对该缓冲区进行释放操作。接口的 input_infos 和 ri_config 参数配置了模型的输入和输出信息。ri_id 参数是运行实例的标识符。如上文提到的,受限于 BPU 内存,HBDK 运行时最多只能处理 256 个并发的运行实例,所以 ri_id 的合法数值范围是 0 到 255。上层代码中应该有相应模块把 ri_id 作为一种资源管理起来并确保不会出现冲突或者溢出。在 BPU 完成一批 functioncall 的处理之后,它会向 CPU 发出编号为 interrupt_number 的中断请求,BPU 驱动库的中断管理模块会处理这些中断请求并通过 cnn_core_wait_fc_done 等接口来与应用程序进行交互。用户定义中断号的范围是 0 到 4095,上层代码也应该合理地管理中断号的使用以确保使用相同中断号的 functioncall 不会被同时送入 BPU。
模型在编译过程中可能会被拆分成多个模型段,其中的一部分需要在 CPU 上执行。所以当收到 functioncall 的中断后,上层代码应该调用以下接口来继续执行模型预测。
HBDK_PUBLIC extern hbrt_error_t hbrtRiContinue(void **funccall_buffer, uint32_t *generated_funccall_num, uint32_t ri_id, uint32_t interrupt_number);
这个接口会在需要时完成在 CPU 上的计算。如果之后还有需要在 BPU 上完成的计算,这个接口还会生成一些 functioncall。一个比较简单的完整执行模型推理的步骤可以是在一个循环中反复调用 hbrtRiContinue 和 BPU 驱动接口,直到 hbrtRiContinue 返回的 generated_funccall_num 为 0。
有时候我们需要以同一帧数据作为输入多次执行同一个模型。一个典型的场景是应用程序使用一个检测模型对摄像头的输入做全图检测,然后每一个检测框作为 BPU resizer 的 ROI再来运行一些属性提取的模型。在这种场景下,ROI 的数量可能会比较大,此时 hbrtRiStart 可用的 ri_id 可能就不够了。对于这种场景,可以使用以下接口。
HBDK_PUBLIC extern hbrt_error_t hbrtRiBatchStart(void **p_funccall_buffer, uint32_t *generated_funccall_num, hbrt_model_handle_t model_handle, const hbrt_ri_input_info_t **model_input_infos, const uint32_t *model_input_batch_size, const hbrt_ri_config_t *ri_config, uint32_t ri_id, uint32_t interrupt_number);
这个接口类似于 hbrtRiStart,只是它每次可以接收一批输入。在这个接口里,model_input_infos 变成了一个二维数组,第一维是模型的输入特征图的数量,第二维是批的大小。model_input_batch_size 是模型每一个输入的批大小。对于多输入的模型,它的所有输入的批大小应该为 1 或者等于同一个非 1 的数。批大小为 1 的输入会被广播到与其他输入匹配。如果模型在编译时输入尺寸的 N 不等于 1,那么这个 NxHxWxC 的整个特征图会被处理成一个输入张量。例如,如果模型编译时使用了 -s/--shape 4x128x128x3,表示这个模型一次性处理4个 128x128x3 的输入张量,在应用程序中对于某一帧输入数据产生了 13 个检测框,那么批大小应该是 ceil(13/4) = 4 而不是 13。另一点需要注意的是只有不包含 CPU 计算的纯 BPU 模型可以通过以上接口启动。
在模型执行完成之后,可以调用以下接口来释放运行实例占用的资源。
HBDK_PUBLIC extern hbrt_error_t hbrtRiDestroy(uint32_t ri_id)
资源的释放可以在模型的所有 segment 执行完成之前进行。可以释放在模型运行的中间调用以上接口来释放资源,此时这一次前向推理将被放弃。
7.6.5. 获取和解析模型输出¶
取决于模型输出数据的用途和后处理的计算模式,应用程序可以使用不同层次的接口来获取模型输出。这些接口应该在 hbrtRiDestroy 之前调用。
最简单的方法是调用以下接口。
HBDK_PUBLIC extern hbrt_error_t hbrtRiGetOutputData(void **data, uint32_t ri_id, uint32_t output_index, DATA_WORK work);
这个接口会以 work 参数指定的格式返回模型的第 output_index 个输出。这里的 work 是一个枚举类型,包括以下可能的取值。
typedef enum {
WORK_CPUMALLOC_RAW = 0, /// return address allocated by bpu_cpumem_alloc.
WORK_MALLOC_NATIVE, /// return address allocated by malloc in stdlib. The data shall be converted to native layout in order NHWC
WORK_MALLOC_NATIVE_NOPADDING, /// return address allocated by malloc in stdlib. The data shall be in native layout (NHWC) without padding
WORK_MALLOC_NATIVE_NOPADDING_INT32, /// return address allocated by malloc in stdlib. The data shall be in native layout (NHWC) without padding and each element shall be converted to int32
WORK_MALLOC_NATIVE_NOPADDING_FLOAT, /// return address allocated by malloc in stdlib. The data shall be in native layout (NHWC) without padding and each element shall be converted to float
WORK_BPU_RAW, /// return BPU address. No data transfer shall happen between BPU and CPU.
} DATA_WORK;
例如,如果设置 work 为 WORK_MALLOC_NATIVE_NOPADDING_FLOAT,这个接口会以浮点格式返回native排布、没有 pad 的输出。而如果 work 设置为 WORK_BPU_RAW,这个接口就会直接返回对应输出的 BPU 地址。
也可以使用相应输出特征图的句柄和运行实例的 ID 调用以下接口来获取模型输出。
HBDK_PUBLIC extern hbrt_error_t hbrtRiGetOutputData(void **data, uint32_t ri_id, uint32_t output_index, DATA_WORK work);
或者通过以下接口获取输出的 BPU 地址。
HBDK_PUBLIC extern hbrt_error_t hbrtRiGetFeatureBpuAddress(bpu_addr_t *addr, uint32_t ri_id, hbrt_feature_handle_t fh);
为了提升应用的性能,我们推荐从BPU的原始输出数据开始进行后处理。假设后处理算法需要输入浮点数据,此时需要的数据转换步骤是最多的。这些步骤包括 数据layout转换 -> 去除padding -> 反量化 。如果后处理算法能够以跳读的方式获取模型输出,那么去除 padding 的步骤可以被省略。下面简要介绍 BPU 输出数据处理的每一个步骤。
调用以下接口来进行数据的 layout 转换。
HBDK_PUBLIC extern hbrt_error_t hbrtConvertLayout(void *to_data, hbrt_layout_type_t to_layout_type, const void *from_data, hbrt_layout_type_t from_layout_type, hbrt_element_type_t element_type, hbrt_dimension_t aligned_dim, bool convert_endianness);
HBDK_PUBLIC extern hbrt_error_t hbrtConvertLayoutRoi(void *to_data, hbrt_layout_type_t to_layout_type, const void *from_data, hbrt_layout_type_t from_layout_type, hbrt_element_type_t element_type, hbrt_dimension_t aligned_dim, bool convert_endianness, hbrt_roi_t roi);
HBDK_PUBLIC extern hbrt_error_t hbrtConvertLayoutToNative1HW1(void *to_data, const void *from_data, hbrt_layout_type_t from_layout_type, hbrt_element_type_t element_type, hbrt_dimension_t aligned_dim, bool convert_endianness, uint32_t n_index, uint32_t c_index);
HBDK_PUBLIC extern hbrt_error_t hbrtConvertLayoutToNative111C(void *to_data, const void *from_data, hbrt_layout_type_t from_layout_type, hbrt_element_type_t element_type, hbrt_dimension_t aligned_dim, bool convert_endianness, uint32_t n_index, uint32_t h_index, uint32_t w_index);
注意这些接口只进行 layout 转换,数据的维度和数据类型不会发生改变。接口的 aligned_dim 参数既是输入张量的维度也是输出张量的维度。BPU 上的部分单元可能产生按照大端存储的结果,对于这些结果应该设置接口的 convert_endianness 为 true 来在小端平台上完成大小端转换。可以通过以下接口查询一个特征图是否是按照大端存储。
HBDK_PUBLIC extern hbrt_error_t hbrtFeatureIsBigEndian(bool *isBigEndian, hbrt_feature_handle_t feature_handle);
hbrtConvertLayout 会一次性完成整个特征图的转换,而 hbrtConvertLayoutRoi 只转换整个特征图中的一个 ROI。如果输出数据的通道数很多,我们推荐在一个三重循环中调用 hbrtConvertLayoutToNative111C 来完成 layout 转换并做后处理,这个接口每次只转换一个像素点的所有通道值的数据。这样可以更好地利用 CPU 的缓存局部性。另一种极端是输出数据只有一个通道,此时在一个两重循环中调用 hbrtConvertLayoutToNative1HW1 可能会获得更好的性能。另外一个优化后处理的方向是将数据转换和后处理逻辑融合在一起。例如,对于用来完成实例分割任务的模型,模型输出可能是每个像素块对于不同类别的置信度,后处理逻辑可能只是简单地对于每个像素块找出置信度最高的类别。在这种场景下,可以每次调用 hbrtConvertLayoutToNative111C 转换输出数据一个像素点的所有通道值,然后遍历转换的结果找到数值最大的类别。之后用来存储转换结果的内存就可以被释放或者重新用来存储下一个像素点转换的结果。
以下接口可以用来去除 padding。通常我们不推荐使用这些接口,在后处理中进行跳读总是可以获得更好的性能。
HBDK_PUBLIC extern hbrt_error_t hbrtRemovePadding(void *data_wo_padding, hbrt_dimension_t dim_wo_padding, const void *data_with_padding, hbrt_dimension_t dim_with_padding, hbrt_element_type_t element_type);
以下接口相反地可以为数据加上 padding。对于从 DDR 输入的模型,如果产生输入数据的模块不支持跳写,可能需要调用以下接口来预处理 BPU 输入数据。
HBDK_PUBLIC extern hbrt_error_t hbrtAddPadding(void *data_with_padding, hbrt_dimension_t dim_with_padding, const void *data_wo_padding, hbrt_dimension_t dim_wo_padding, hbrt_element_type_t element_type);
可以使用以下 API 量化模型输入数据,或者反量化模型输出数据。
HBDK_PUBLIC extern hbrt_error_t hbrtQuantize(void *to_int_data, hbrt_element_type_t to_int_element_type, hbrt_dimension_t dim, const uint8_t *shifts, const float *from_float_data);
HBDK_PUBLIC extern hbrt_error_t hbrtUnquantize(float *to_float_data, hbrt_element_type_t from_int_element_type, hbrt_dimension_t dim, const uint8_t *shifts, const void *from_int_data);
需要注意的并不是所有的 BPU 输出都需要进行转换。一些操作产生的输出可以被直接解析。可以通过以下接口来查询一个特征图是被什么样的操作产生。
HBDK_PUBLIC extern hbrt_error_t hbrtGetFeatureOperatorType(hbrt_output_operator_type_t *type, hbrt_feature_handle_t feature_handle);
这些操作包括:
typedef enum {
OUTPUT_BY_UNKNOWN = 0,
OUTPUT_BY_CONV, ///< This tensor is generated by conv
OUTPUT_BY_DETECTION_POST_PROCESS, ///< This tensor is generated by DetectionPostProcess_X2
OUTPUT_BY_RCNN_POST_PROCESS, ///< This tensor is generated by RCNNPostProcessing_X2
OUTPUT_BY_DETECTION_POST_PROCESS_STABLE_SORT, ///< This tensor is generated by DetectionPostProcess_X2 with stable
///< sort
OUTPUT_BY_CHANNEL_ARGMAX, ///< This tensor is generated by channel_argmax
} hbrt_output_operator_type_t;
如果一个输出特征图是被 CONV 产生的,通常它需要经过以上部分或者全部的步骤来完成数据转换。但是如果输出特征图是由其余已知的操作产生的,则可以使用以下的数据结构来直接解析结果。
对于 OUTPUT_BY_DETECTION_POST_PROCESS, OUTPUT_BY_DETECTION_POST_PROCESS_STABLE_SORT 和 OUTPUT_BY_RCNN_POST_PROCESS, 输出数据的第一个元素(可能是 uint16 或者 float32)表示有效数据有多少个 byte。然后略过相应数据结构的 byte 数,从第二个数据结构开始,每几个 bytes 可以用以下数据结构来读取。
/**
* DetectionPostProcess_X2 output and RCNNPostProcessing_X2 int16 output data type.
* @note DetetionPostProcess_X2's output consists of 16-byte output byte size and
* N bernoulli_hw_detection_post_process_bbox_type_t, where N is valid box number.
* The output byte size = N * sizeof(bernoulli_hw_detection_post_process_bbox_type_t)
* The entire output is organized as:
* (uint16_t)output_byte_size ******(14 byte padding)
* (bernoulli_hw_detection_post_process_bbox_with_pad_type_t) box0
* (bernoulli_hw_detection_post_process_bbox_with_pad_type_t) box1
* ...
*/
typedef struct {
int16_t left;
int16_t top;
int16_t right;
int16_t bottom;
int8_t score;
uint8_t class_label;
int16_t padding[3];
} bernoulli_hw_detection_post_process_bbox_with_pad_type_t;
对于 OUTPUT_BY_CHANNEL_ARGMAX ,如果输出只有一个通道,那么结果已经是拥有最高置信度的通道的序数。如果结果有两个通道,那么第一个通道是序数,第二个通道是最高的置信度。
7.6.6. 辅助接口¶
HBDK 运行时还提供了一些接口用来辅助应用开发和故障排查。例如,如果在产品的生命周期中需要更新HBDK的版本,就可能需要解决兼容性问题。调用以下接口可以在运行时库与 HBM 文件或者应用代码中使用的头文件不兼容时报出警告。
static inline hbrt_error_t hbrtIsCompatibleHeader()
HBDK_PUBLIC extern hbrt_error_t hbrtGetVersion(hbrt_version_info_t *version)
HBDK_PUBLIC extern hbrt_error_t hbrtGetHbmHbrtVersion(hbrt_version_info_t *version, hbrt_hbm_handle_t hbm_handle)
HBDK_PUBLIC extern hbrt_error_t hbrtGetModelHbrtVersion(hbrt_version_info_t *version, hbrt_model_handle_t model_handle)
HBDK_PUBLIC extern hbrt_error_t hbrtIsCompatibleVersion(hbrt_version_info_t v1, hbrt_version_info_t v2)
hbrtIsCompatibleHeader 检查头文件中记录的版本号与运行时库的版本号是否兼容。hbrtGetVersion 返回运行时库的版本号,hbrtGetHbmHbrtVersion 返回 HBM 文件的版本号,如果 HBM 文件中只包含一个模型,则 HBM 文件的版本号与编译这个模型使用的 HBDK 的版本号一致,若 HBM 文件中包含多个模型,则 HBM 文件的版本号与最后一次打包模型使用的 HBDK 的版本号一致。由于不同版本的 HBDK 编译产生的模型可以打包在一起,HBM 文件中的多个模型可能会有多个不同的版本号。可以通过 hbrtGetModelHbrtVersion 接口获取每一个模型的版本号。如果主版本号或者副版本号不同,那么这两个版本是不兼容的。
以下接口可以在模型执行完毕后将输出存储到文件中。这些结果可以用来与 MXNet/Tensorflow 或者其他预测库做对比来帮助故障排查。
完整的 API 列表与使用方法,请参考 HBDK 运行时 API。
HBDK_PUBLIC extern hbrt_error_t hbrtDumpModelOutputToFile(const char *path, const char *filename_prefix, uint32_t ri_id);
7.7. 模型保护方案¶
7.7.1. 模型保护¶
模型保护目的是防止地平线或客户的模型被其他人盗用。整体的方案分为两个部分:
编译阶段在编译得到的可执行文件中加入签名,
在运行时加载阶段校验可执行文件中的签名和设备上的签名文件。如果校验失败,则中止模型加载过程。
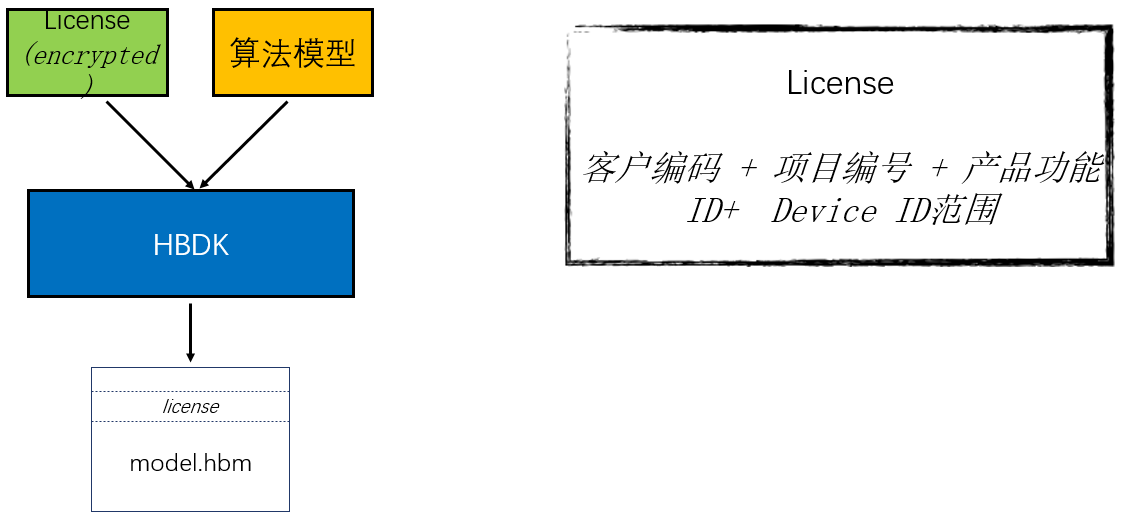
上图为编译阶段的流程。编译器输入模型文件和加密后的 license 文件(即签名文件),编译器会将 license 的内容添加到生成的可执行文件中。其中,License 可以由客户编码、项目编码、产品功能编码和 Device ID 范围组成。在编译阶段,为了防止 license 的内容泄漏,license 需要是加密后的密文。
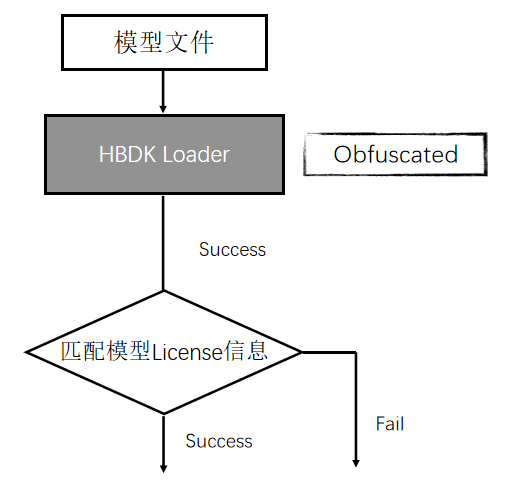
上图为运行时模型校验过程,在运行时加载过程中会读取模型文件中的 license 信息和设备上的 license 信息,将这些信息解密后进行比对。如果匹配成功,则正常进行加载流程;如果匹配失败,则中止加载流程,并返回错误码给上层代码。另外,为了防止运行时代码会破解,运行时加载模块会使用特殊的编译器进行模糊化处理。
7.7.2. 使用流程说明¶
创建 license.txt 文件,将 key 写到 license.txt 中,长度 64 bytes(64个字符)。
Note
license 中不能含有 \0 字符。
将 license.txt 发送给地平线 FAE,生成加密后的 license文件:license-hbcc 和 license-client。
将 license-hbcc 拷贝到 hbcc 编译器服务器当前用户的 ~/.hbcc/ 目录,并重命名为 license。
将 license-client 拷贝到 X2 开发板当前用户的 ~/.hbcc/ 目录,并重命名为 license。
正常编译,执行测试程序。