9. 常见问题¶
9.1. 示例模型和公板网络有何异同?¶
示例模型和公版网络异同说明如下:
9.1.1. 检测模型¶
9.1.1.1. SSD¶
Q&A
公版能在X2/J2上运行?论文版本,不能在X2/J2运行。
修改网络后,性能提升?是。
说明
backbone不同,论文版本是VGG,GluonCV支持的backbone比较多,包括mobilenet、VGG、restnet等,我们的示例暂时只包含mobilenet。
公版提供的示例的模型输入包括512x512和300x300,我们提供的示例暂时只包含512x512。
公版后接卷积之间添加了1x1卷积用于减小模型容量,我们的网络中没有添加。
9.1.1.2. YOLOV3¶
Q&A
公版能在X2/J2上运行?否,不支持leaky relu。
修改网络后,公版能在X2/J2上运行?是。
修改网络后,性能提升?是。性能提升没有SSD明显。
说明
用relu替换leaky relu;
类太多也可能会导致速度慢。
9.1.1.3. Faster RCNN¶
Q&A
公版能在X2/J2上运行?否,不支持deconvolution。
修改网络后,公版能在X2/J2上运行?是。
修改网络后,性能提升?否。
说明
RPN的分类器,公版是使用softmax,tensorflow使用sigmoid;
RPN提取proposal的operator,公版是根据score选择top k个bbox去做nms,tensorflow是选择大于等于设置的score threhold的bbox去做nms,选择做nms的数量超过4095时,tensorflow会随机选择k个bbox去做nms,而不是传统的top k个bbox。这个区别会导致如果score threshold设置的太小,进而导致rpn做nms前的bbox数量超过4095时,性能会有大幅下降。但是在实际使用中,一版会卡比较高的score,所以对实际产品的使用基本不会有影响;
roi feature提取,公版是使用RoIPooling,tensorflow使用RoIAlign;
roi feature提取后的shape,公版是(7, 7),tensorflow是(8, 8);
rcnn head,公版是2个FC,然后用2个FC分别输出classification和regression的结果;tensorflow是3个convolution将roi feature下采样到(1, 1),然后接2个pointwise convolution分别输出classification和regression的结果;
rcnn后处理,公版是对每个proposal,遍历所有的类别,只要score大于等于threshold,就输出相应的框,tensorflow是对每个proposal,只去score最高的类别,且这个score大于等于threshold,就输出相应的框。这个区别会导致tensorflow在测试MAP的时候,会导致性能大约下降1个MAP,但是在实际使用的时候,为了减少误报,score往往会卡的比较高,这时候后处理的差别基本不会导致性能损失。
9.1.1.4. FPN+Mask RCNN¶
Q&A
公版能在X2/J2上运行?否,不支持deconvolution。
修改网络后,公版能在X2/J2上运行?是。
修改网络后,性能提升?否。
说明
mask rcnn
RPN的分类器,公版是使用softmax,tensorflow使用sigmoid;
RPN提取proposal的operator,公版是根据score选择top k个bbox去做nms,tensorflow是选择大于等于设置的score threhold的bbox去做nms,选择做nms的数量超过4095时,tensorflow会随机选择k个bbox去做nms,而不是传统的top k个bbox。这个区别会导致如果score threshold设置的太小,进而导致rpn做nms前的bbox数量超过4095时,性能会有大幅下降。但是在实际使用中,一版会卡比较高的score,所以对实际产品的使用基本不会有影响;
roi feature提取,公版是使用RoIPooling,tensorflow使用RoIAlign;
roi feature提取后的shape,公版是(7, 7),tensorflow是(8, 8);
rcnn head,公版是2个FC,然后用2个FC分别输出classification和regression的结果;tensorflow是3个convolution将roi feature下采样到(1, 1),然后接2个pointwise convolution分别输出classification和regression的结果;
rcnn后处理,公版是对每个proposal,遍历所有的类别,只要score大于等于threshold,就输出相应的框,tensorflow是对每个proposal,只去score最高的类别,且这个score大于等于threshold,就输出相应的框。这个区别会导致tensorflow在测试MAP的时候,会导致性能大约下降1个MAP,但是在实际使用的时候,为了减少误报,score往往会卡的比较高,这时候后处理的差别基本不会导致性能损失;
mask roi的选择,公版是使用rpn出来的proposal,tensorflow是使用rcnn得到的bbox;
mask roi feature提取后的shape,公版是(14, 14),tensorflow是(16, 16);
mask head,公版使用deconvolution做上采样,tensorflow使用双线性插值做上采样。
9.2. 如何评估真机模型精度和一致性?¶
9.2.1. 性能指标获取¶

9.2.1.2. 模型基本参数获取¶
本节所描述操作需要在开发机上完成。
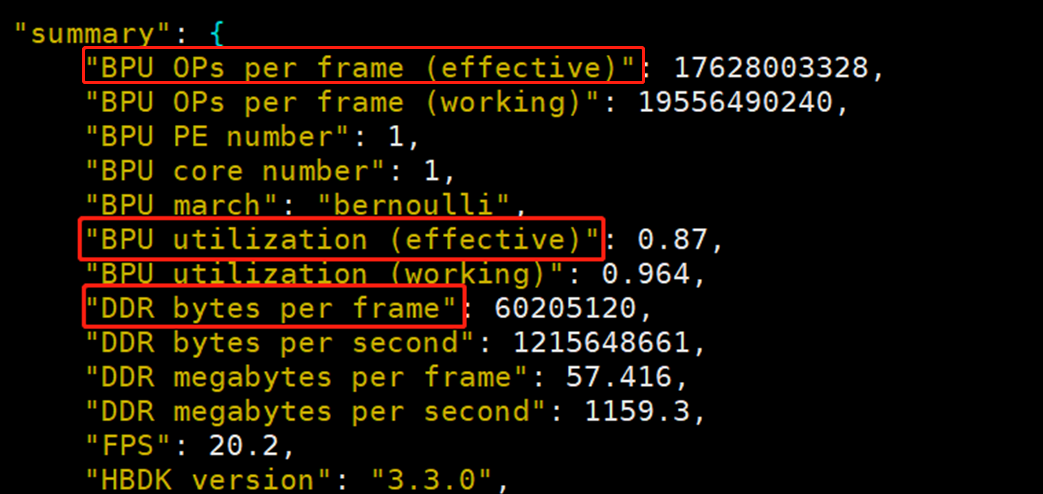
本处关注的模型基本参数包括 DDR_bytes_per_frame (每帧图片处理的DDR数据大小)和 BPU_Ops_per_frame_effective (不包含padding的BPU Ops)。在获取基本参数前,需要准备好以下资源。
编译好的模型文件(xxx.hbm)
HBDK工具包
获取参数的命令格式如下:

其中,
xxx.hbm 为准备好的模型;
该命令的分析结果从当前目录下的 xxx.json 中获取。
以 yolo3 为例,执行分析命令如下:

打开 out.json 文件,查看 summary 字段内容如下:
9.2.1.3. 板上运行参数获取¶
本节所描述操作需要在 x2/j2 开发板上完成。
本处关注的运行参数包括 BPU_Latency、Post_Process_Latency、BPU_AV、CPU_AV 和 Frame_Rate,使用 perf.sh 即可获得。
在获取参数前,需要完成以下准备事项:
进入嵌入式包,将 perf.sh 放置在 perf 文件夹;
修改 perf 文件夹中的 config.json,修改 log_level 为1。
perf.sh 将持续运行十分钟,对模型执行的平均性能进行评估。启动命令如下:

其中的 xxxx.sh 表示 perf 文件夹中的具体模型启动脚本,以 mobileNetV2 为例,脚本启动命令如下图:

执行完成后通过 userdata/analysis_report.log 获取结果如下:

其中,General_Detect.cls_module time 为 BPU_Latency;class_post_process time 为 Post_Process_Latency。
9.2.1.4. 计算性能指标¶
模型计算量(GOPs)=BPU_Ops_per_frame_effective /(1000*1000*1000)
DDR带宽利用率=DDR_bytes_per_frame*Frame_Rate/(2666*1000*1000*32/8)
MAC利用率=BPU_utilization_effective
CPU利用率=CPU_AV
前向网络耗时=BPU_Latency
后处理耗时=Post_Process_Latency
BPU1 利用率=BPU1_AV
BPU2 利用率=BPU2_AV
9.2.2. 精度指标获取¶
9.2.2.1. 预处理工具 val_send 使用¶
val_send.py 在 docker 中提供。执行命令 pyt3 val_send.py -h 获取使用说明。
python3 val_send.py -h
usage: val_send.py [-h]
--type {classification,ssd,yolo,fasterrcnn,maskrcnn,parsing}
--image_list IMAGE_LIST
--board_ip BOARD_IP
optional arguments:
-h, --help show this help message and exit
--type {classification,ssd,yolo,fasterrcnn,maskrcnn,parsing}
the model type for validation .
classification -- use size 224x224;
ssd -- use ssd size 512x512;
yolo -- use yolo size 416x416;
fasterrcnn -- use fasterrcnn min_max_scale: (600,1000);
maskrcnn -- use maskrcnn min_max_scale: (800,1000);
parsing -- use parsing size:(1024,2048);
--image_list IMAGE_LIST
list file which contains name of test images.
--board_ip BOARD_IP the ip address of your X2/J2.
其中,
type为模型类型,支持classification、ssd、yolo、fasterrcnn、maskrcnn、parsing;
image_list为图片地址列表文件,每行包含一张测试图片的路径;image_list文件组织形式如下图。
board_ip是x2/j2开发板的ip地址。
以fasterrcnn为例,val_send使用命令如下:
python3 val_send.py --type fasterrcnn --image_list voc.lst --board_ip 10.64.35.123
9.2.2.2. 嵌入式端应用eval使用¶
启动应用
使用嵌入式包中eval下的start_***.sh可以在x2/j2开发板上启用相应模型,命令如下。
sh start_mobileNetV1.sh以start_mobileNetV1.sh为例,内容如图所示:

评测应用的输入参数命令如下表所示:
命令参数
描述
使用场景
--detection-module-name
模型名称
分类、检测
--model-file
模型文件名
分类、检测
--log-file-name
日志文件名
分类、检测
--is-yolo
--is-ssd
--is-fasterrcnn
--is-maskrcnn
--is-parsing
模型输出的四种 解析格式,包括 yolo,ssd, fasterrcnn, maskrcnn,parsing
检测、分割
结束应用
当评测应用正常结束时会如下图所示:
可通过在终端输入q或Q来正常结束应用程序,当然也可以在程序运行时通过q或Q强行停止评测应用。
9.2.2.3. 评测工具使用(嵌入式日志解析)¶
评测应用会将输出日志保存在当前目录下,可对输出的日志文件进行解析,基于不同任务的评价指标计算得到测试集在嵌入式平台上的精度。
get_***_accuracy_alone.py系列评测脚本均在docker镜像中提供。
classification日志解析
使用accuracy_tools/get_class_accuracy_alone.py可以根据嵌入式日志获取classification精度。
python3 get_class_accuracy_alone.py -h usage: get_class_accuracy_alone.py [-h] --log_file LOG_FILE --gt_file GT_FILE optional arguments: -h, --help show this help message and exit --log_file LOG_FILE log file from embedded application. --gt_file GT_FILE the file contains image name and label.其中,
log_file是嵌入式端记录的日志文件;
gt_file是包含图片名称&label的列表文件,
gt_file文件组织形式如下图。每行包含一张测试图片名称和label,以空格分隔。
执行结果如下,第一个值为top1精度,第二个值为top5精度。

detection日志解析
使用accuracy_tools/get_detection_accuracy_alone.py可以根据嵌入式日志获取detection精度。
python get_detect_accuracy_alone.py -h optional arguments: -h, --help show this help message and exit --type {ssd,yolo,fasterrcnn} log type for check. ssd -- use ssd size 512x512; yolo -- use yolo size 416x416; fasterrcnn -- use fasterrcnn min_max_scale: (600,1000); --annotation_path ANNOTATION_PATH directory for voc annotation. --log_file LOG_FILE log file from embedded application. --trans_difficult_label {True,False} set False when working with tensorflow fasterrrcnn.其中,
type是检测任务的类型,支持ssd,yolo和fasterrcnn;
annotation_path是VOC数据集的Annotations文件夹路径;
log_file是嵌入式端记录的日志文件;
trans_difficult_label默认True,仅在执行tensorflow的fasterrcnn模型时需要将其设置为False。
以yolo模型为例,日志解析命令如下。最后输出值为mAP。
python3 get_detect_accuracy_alone.py --type ssd --annotation_path ../data/VOCdevkit/VOC2007/Annotations --log_file detection.log
instance(maskrcnn)日志解析
使用accuracy_tools/get_instance_accuracy_alone.py可以根据嵌入式日志获取instance精度。
python3 get_instance_accuracy_alone.py -h optional arguments: -h, --help show this help message and exit --anno_file ANNO_FILE specify the ground truth file. default value is ./instances_val2017.json --log_file LOG_FILE specify log_file with model task. --fixed_width FIXED_WIDTH specify width if not working with min_max_scale. --fixed_height FIXED_HEIGHT specify height if not working with min_max_scale. --mask_file MASK_FILE specify mask data file --is_gluon {True,False} set False when working with tensorflow model --ctx CTX specify gpu device if sigmoid with gpu needed其中,
anno_file是mscoco的instances_val2017.json文件;
log_file是嵌入式端记录的日志文件;
--is_gluon默认True,指明是否在使用gluon模型。
--mask_file是嵌入式端生成的mask.data文件,默认在放置在嵌入式eval程序的同级目录下。
其他参数为扩展参数,暂先不要使用。
日志解析命令如下。最后一行输出值为box预测与mask预测精度。
python3 get_instance_accuracy_alone.py --anno_file ../data/mscoco/annotations/instances_val2017.json --log_file maskrcnn.log --mask_file mask.data --is_gluon False
parsing日志解析
使用accuracy_tools/get_parsing_accuracy_alone.py可以根据嵌入式日志获取parsing精度。
python3 get_parsing_accuracy_alone.py -h optional arguments: -h, --help show this help message and exit --gtfine_val_path GTFINE_VAL_PATH specify the val path for cityscapes. --log_file LOG_FILE log file from embedded application.其中,
log_file是嵌入式端记录的日志文件;
gtfine_val_path是cityscapes的gtFine/val所在目录。
日志解析命令如下。最终输出值为iou结果。
python3 get_parsing_accuracy_alone.py --gtfine_val_path ../data/cityscapes/gtFine/val --log_file parsing.log
9.3. 什么是X2_Resizer?¶
本文档用于说明 X2 芯片中图像/特征图缩放的三个主要部件,及其在AI处理流水线中的作用。
9.3.1. X2 芯片架构及其中的硬件缩放加速模块¶
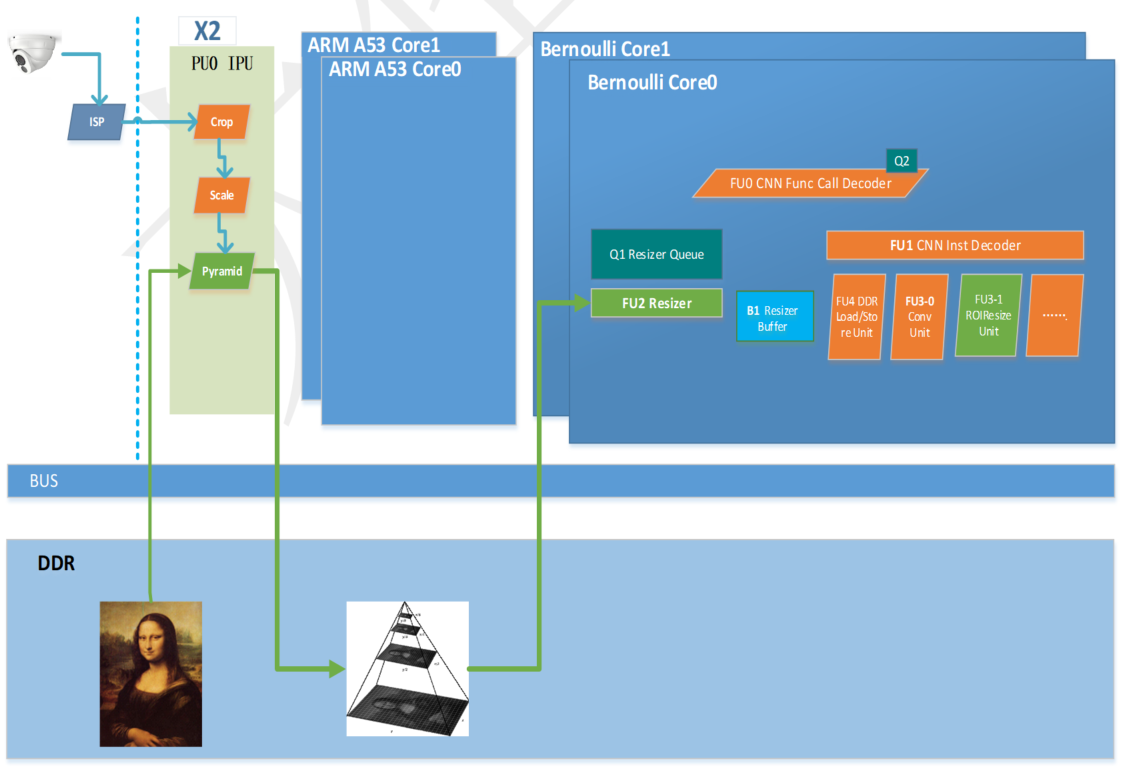
如上,是 X2 芯片中架构框图,被标记为浅绿色的如下三个硬件模块可完成缩放功能:
PU0–IPU:金字塔缩放模块
FU2–Resizer:BPU 中的 resizer 模块
FU3-1–ROIResize Unit:BPU 中的 ROIResize 指令
9.3.1.1. PU0–IPU¶
PU0–IPU 中,主要完成金字塔功能,它的输入图片可以来自 Camera+ISP 或者直接从 DDR 中读入数据。IPU 中对图像处理的流水线包含 Crop、Scale 和 Pyramid 三个硬件处理部分。其中:
Crop 直接对 ISP 输入的底图中截取一个区域,
Scale 模块放大或者缩小到指定尺寸,
Pyramid 模块生成金字塔。
图像的具体输入方式有两种:
当图像经 X2 芯片的 VIO 接口进入时,可通过 Crop–>Scale–>Pyramid 模块实现金字塔缩放功能。
VIO能接受的输入图像的最大尺寸为4096x4096。
当图像已经在 X2 芯片的 DDR 内时,可被 Pyramid 模块读入后,完成金字塔缩放功能。
Pyramid 生成金字塔能接受的图像最大尺寸为2048x2048。
IPU 硬件可以实时的完成 ISP 输入图像在内存中的图像金字塔生成,不占用任何 CPU、BPU 计算资源。Pyramid 金字塔模块采用双线性插值方式实现,通过修改配置,可实现满足一定限制(例如:stride 为16的整数倍,图像起始地址 16Byte 对齐等)的不同分辨率、不同长宽比,不同金字塔层数、不同内存地址排布的输入图像金字塔的生成。Pyramid 的内部实现采用多层金字塔滑动输出的方式。在实际应用场景中,一般只有一次金字塔写入 DDR 操作,没有额外的带宽浪费。一般场景下,因为视觉处理策略确定,因此金字塔的配置是相对固定的。只可对图像数据实现缩放操作。
9.3.1.2. FU2–Resizer¶
FU2 可直接基于指定的 DDR 中的二维图像地址、指定的图像的 ROI 区域,取出 YUV420 NV12 格式的图像子区域,缩放成指定大小的 YUV444 格式的图片,直接送入BPU计算硬件加速模块,做卷积神经网络的前向推理运算。
Resizer 的二维输入图像,可以是 ISP 输出的图像底图或者底图的某块区域,也可以是金字塔的某一层输出图像的某个 ROI 区域。输入可以是彩色图或者灰度图。FU2 支持从缩小为输入图片的1/2,放大为输入图片的8倍。缩放算法为双线性插值。
在 X2 芯片中 FU0 CNN Func Call Decoder 维护一个计算任务队列,用于神经网络前向 Inference 任务队列的维护,并根据网络输入的来源,给 FU2 分发 resizer 执行任务。FU2 维护任务队列,异步的提前执行 resize image 的任务,并将数据保存在 B1–Resize Buffer 中。对于需要 resizer 输出的 YUV444 图像的模型,FU1 CNN Inst Decoder 将从 B1 buffer 中取数据作为输入。
通常情况下,FU2 配合 PU0 可实现对任意大小输入图片的任意感兴趣区域做任意比例的图像缩放,满足诸如人脸检测–>人脸关键点 …… –>人脸识别的全流程。
基于 IPU 生成的 Pyramid 图像金字塔抠取 ROI 区域作为 resizer 的输入,加上 resizer 和 BPU 的异步处理方式,resizer 一般不构成瓶颈。因 resizer 的数据只送给 BPU 使用,因此性能测试无法直观进行。在实际开发中,可以通过不用 resizer 的模型 inference 性能测试,与有 resizer 输入的模型 inference 性能测试的对比,检查 resizer 是否构成性能瓶颈。
9.3.1.3. FU3-1 ROIResize Unit¶
ROIResize 模块目前是作为 BPU 内部的一个硬件加速指令,完成对多 channel 的 3-D 特征图的缩放操作。实现的方式是双线性插值,需要基于 BPU 指令使用该功能。此模块具备 ROIPooling 的功能。
9.3.2. X2 典型场景分析¶
PU0-IPU
一般用于为检测或多任务模型提供输入,用于目标检测,编译模型时来自 IPU 的输入需指定选项 -i pyramid。
FU2-Resizer
一般用于为认知或分类模型提供输入,通常从 IPU 生成的图像金字塔某一层中抠取一个ROI作为模型的输入。编译模型时需指定选项 -i resizer。
通过选取合适的金字塔层,Resizer 目前的缩放比例限制能够满足绝大多数场景的需要。
FU3-1 ROIResize Unit
一般用于模型中有 ROIPooling,ROIAlign 的网络。
关于 PU0-IPU,FU2-Resizer 的详细试用场景,参见 7.2.1.1 模型输入来源。
9.4. 如何恢复开发板坏板?¶
烧写设置错误和意外情况都可能造成开发板坏板(此处指非物理性损坏)。开发板坏板的原因可能但不限于: 烧写过程中烧写失败、烧写设置错误,烧写过程中停电、以太网线/串口线断开连接等。 请参考以下内容恢复开发板。
9.4.1. 设置¶
恢复开发板坏板的唯一方式是通过在 uart 模式下再次成功烧写。请按照以下说明进行设置:
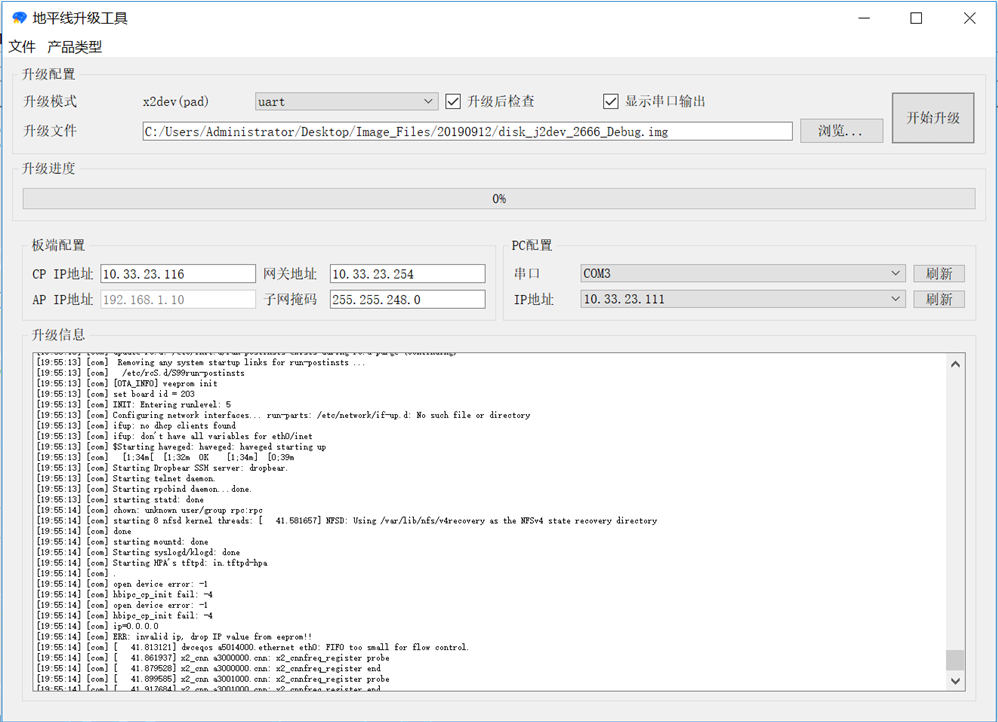
升级配置:配置升级的相关信息。
升级模式:支持3种升级模式,但若开发板不能启动,则只能选择 uart 模式。
模式
要求
支持的升级文件名
说明
uart
板子网络正常
disk*.img
强制在UART下载模式下升级,适用于未烧录过镜像或者不能启动的板子,升级速度比较慢,在单击“开始升级”之后,需要给板子断电,然后按照“升级信息”中的提示给板子上电。 只支持升级disk*.img,也就是整个emmc镜像。
Note
disk*.img 文件名只能使用英文字符加下划线和点号,不能有空格。
产品设置:设置板子端的相关信息。
CP IP地址:
如果选择的板子类型为非 IPC,那么此处填写的是 X2/J2 端的 IP 地址,用于 X2/J2 从 PC 下载镜像。
如果板子类型为 IPC,则此处填写 AP 端的 IP 地址。需要确保电脑可以通过此 IP 地址访问到板子。
Note
不要配置 PC IP 地址为“169.254.”打头。
AP IP地址:
如果选择的板子没有 AP 芯片,则忽略该选项。否则,输入 AP 芯片的 IP 地址。
Note
不要配置 PC IP 地址为“169.254.”打头。
网关地址:
如果选择的板子类型为非 IPC,那么此处填写的是 X2/J2 端的网关地址,对于板子和电脑直连的情况,网关地址可以填写为电脑与板子连接网卡的 IP 地址。
如果板子类型为 IPC,无需填写。
子网掩码:
如果选择的板子类型为非 IPC,那么此处填写的是 X2/J2 端的子网掩码。
如果板子类型为 IPC,无需填写。
PC 配置:
串口:选择 X2/J2 连接电脑后识别到的串口号,后面的 刷新 按钮用于插拔串口线后刷新串口列表。如果升级模式为 ota,则可以选择 N/A,表示不使用串口,所有对板子的操作都通过网络进行。
IP 地址:选择电脑与板子联通的网卡的 IP 地址。后面的 刷新 按钮用于刷新 PC 的 IP 地址列表。
按照如图所示连接以太端口(①)和串口(②):

Note
升级过程中,开发板只能连接一个 BPU 核心板,且该核心板需要放置在右端,否则会导致升级失败。
9.4.2. 烧写开发板¶
请仔细检查以确保以下各项条件已满足:
升级过程中电源线正确连接,
电脑上正确安装串口驱动,
镜像文件升级为正确的版本,
开发板和电脑在同一子网内,可以在 Internet 协议版本4(TCP/IPv4)属性 中修改:
完成所有的配置后,单击 开始升级,并遵循升级工具中出现的提示进行操作。升级进程将在进度条中展示。
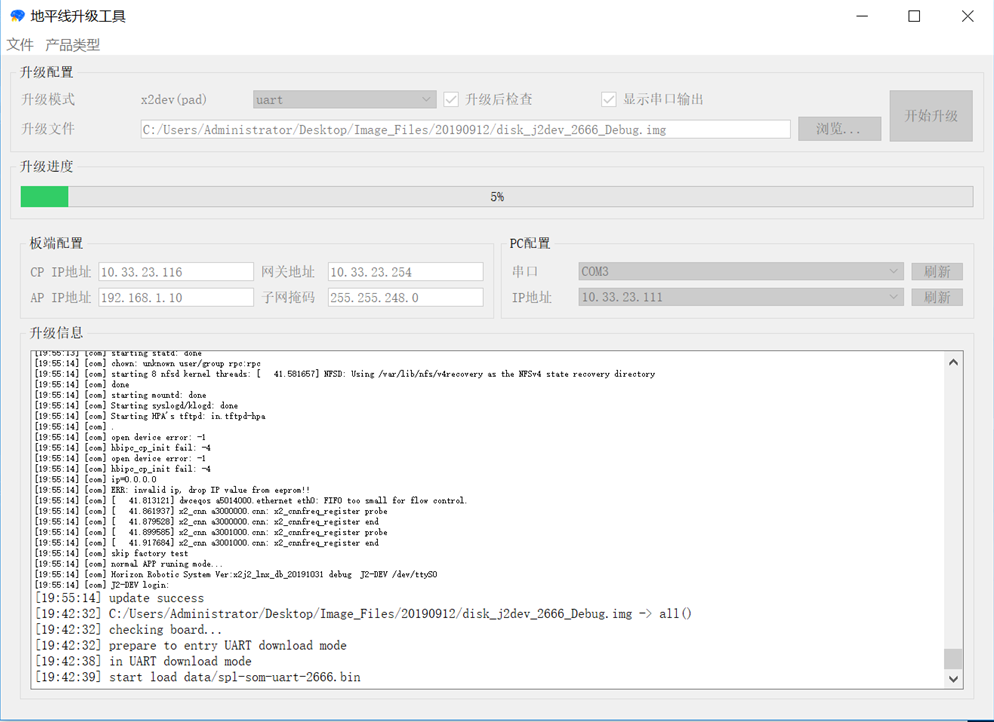
Note
升级时间取决于镜像大小和升级模式。
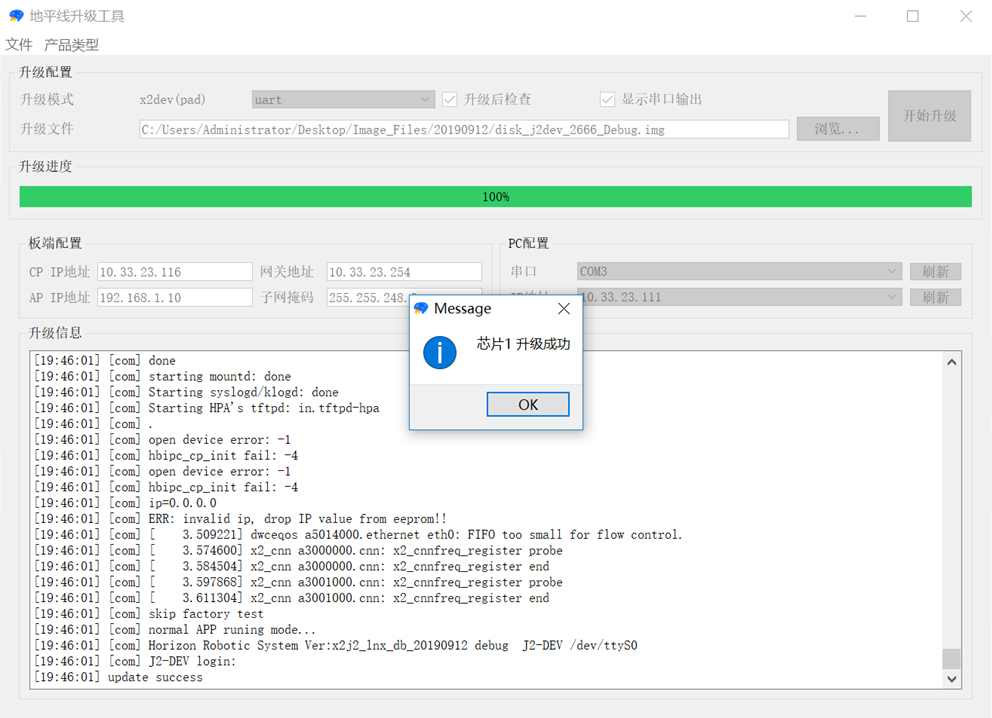
无论升级成功与否都会出现确认框。如果升级失败,请查看升级信息中的输出结果确认升级失败的原因;同时确保满足以上信息,并重新按照以上操作进行设置。 升级成功与否取决于开发板是否能启动 X2/J2 Linux shell。如果升级成功,会出现该弹出框。
成功升级后,执行以下命令修改开发板的IP地址。
hrut_ipfull s ip mask gateway
例如:
hrut_ipfull s 10.33.23.116 255.255.255.248 10.33.23.1
使用 SSH IP 登录开发板检查配置是否生效。
9.4.3. 升级失败示例及原因¶
下图展示烧写失败的情况:
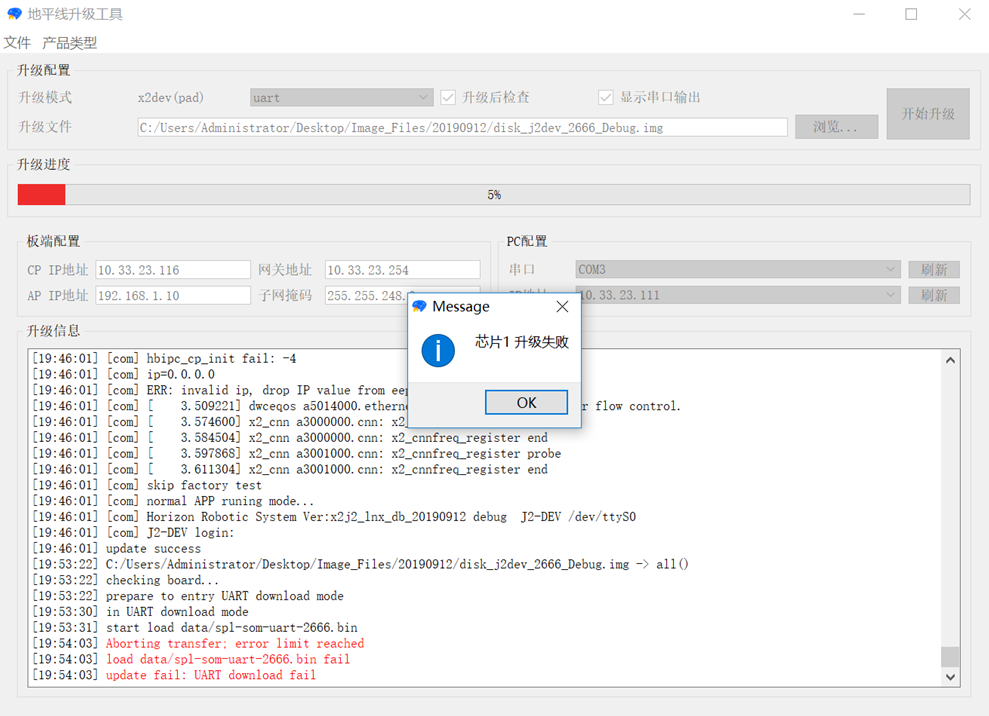
升级过程断电。
如果上次升级失败,若该次选择 U-boot 模式,升级会再次失败。
如果没有按照提示接通/断开电源,升级工具会在该状态卡死。
如果电脑和开发板没有以太网连接,串口升级部分会升级成功,但网口升级部分会升级失败。
Note
如有其他问题,请联系地平线 FAE 工程师。
9.5. 如何比较模型与上板一致性?¶
validate 程序包括两部分:
模型预测脚本部分,以 tensorflow 框架为基础,提供了一个脚本。可以 dump 模型的输入数据,并且执行模型,得到结果的二进制文件。
板上程序部分,通过调用 bpu-predict 接口,用模型 dump 出的输入数据来运行模型,并得到模型输出的二进制文件。
通过比较脚本和板上程序的输出的二进制文件的 md5 值来确定两部分跑的结果是否完全一致。
Note
板上运行的模型一定要用 -i ddr 模式编译。
9.5.1. 模型预测脚本¶
脚本在 /root/example/validate_code/shell/tf-predict-script 目录下,文件名是 inference.py。请按照以下步骤操作。
在使用时需要修改模型的输入图片路径,模型输入的图像大小,包括 img_height, img_width。

执行命令。
python3 inference.py ./ssd.pb
inference.py 脚本执行完成之后,会在当前目录下生成模型 input.dat 文件和输出文件 *.dat。例如:
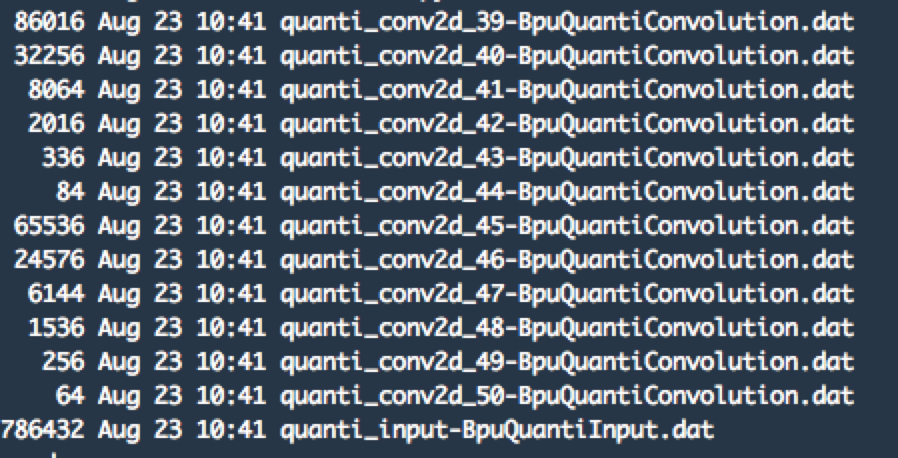
其中,带 BpuQuantiInput 的是模型输入文件,其他的是模型的输出文件。
9.5.2. 板上程序¶
板上程序在 runtime 目录下,执行如下步骤:
编译之后的模型 hbm 文件放到 runtime/lib 目录下,
把嵌入式软件包中 app/lib/ 目录下的 libbpu_predict.so 和 libhbrt_bernoulli_aarch64.so 拷贝到 validate/lib 目录下。因为不同发布版本会不一样,所以这里不在 runtime 包中携带这两个 so,
把预测脚本 dump 出来的 input.dat 文件放到开发板上,
修改 run-validate.sh 脚本,修改 hbm 路径和 input.dat 的路径。

执行脚本。
执行 start_validate.sh 脚本之后,会在当前目录下生成模型的输出文件,如下图所示:
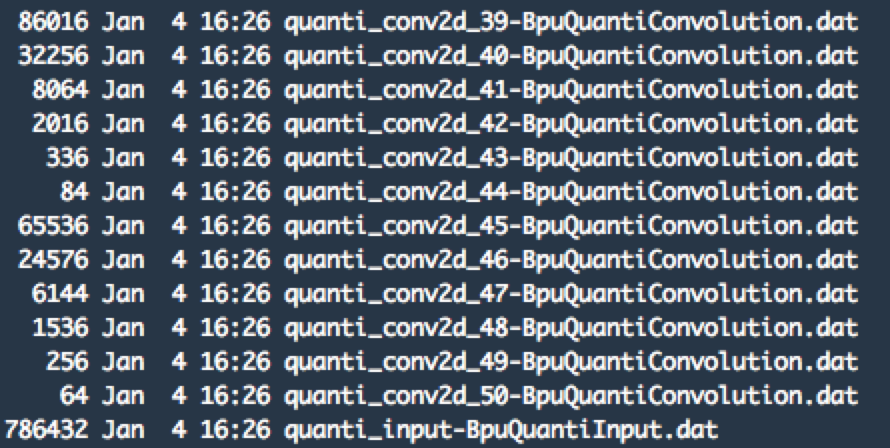
可以看到,这里输出了跟预测脚本跑出的名字一样的 dat 文件。可以使用 md5sum 命令来对比两种方式跑出的二进制文件是否一致。
9.6. 如何进行金字塔模块耗时测试?¶
X2/J2 IPU 模块中包含了图像金字塔。图像金字塔是基于 YUV420sp-NV12 格式,对 Y 和 UV 数据按照配置进行金字塔缩放操作。其中,每层的金字塔缩放系数、每层金字塔在内存中的位置均可灵活配置。IPU 预先将图像金字塔保存在 DDR 中,应用程序通过在金字塔中选择合适的层来获取图像数据,以降低带宽消耗。例如,如果系统需要输入图像 ROI,对 DDR 带宽占用较为友好的处理方式是 Resizer 先从 DDR 中读取图像金字塔的某一层数据,然后再做图像缩放。
金字塔模块实现了对图片做金字塔的功能,即把原始图片,按照一定的缩放比例,缩放出多张图片,该测试程序可用于测试金字塔模块的处理速度。
该示例中提供了两种初始图片大小的缩小耗时测试:720p 和 1080p,对应两个脚本,两个示例图片及两个配置文件。若需要修改金字塔输出层数,可以在使用前先对配置文件 hb_vio_720.json 或者 hb_vio_1080.json 进行修改,如图所示:

ds_layer_en 用于配置 down scale 层数,范围为 4 ~ 23,
修改 down scale 前,需要先知道两个概念基础层和 ROI 层:
基础层:为 4xk(k 取值 0 ~ 5)层,每层缩放倍数为 (1/2) k;
ROI 层:由基础层通过选定 ROI 区域进行缩放得到。
layer 1、2、3 基于 layer 0,
layer 5、6、7 基于 layer 4,
layer 9、10、11 基于 layer 8,
layer 13、14、15 基于 layer 12,
layer 17、18、19 基于 layer 16,
layer 21、22、23 基于 layer 20。
例如,要得到原图的 1/4 大小的金字塔图片,则 (1/2) 2 = 1/4,因此此处应设置 ds_layer_en 为 4x2 = 8。
Note
由于芯片限制,最后输出尺寸最大为 2048x2048,最小为 48x32。且缩放 size 会向下取偶。如得到一个 401x401 的 size,会向下取偶得到 400x400。
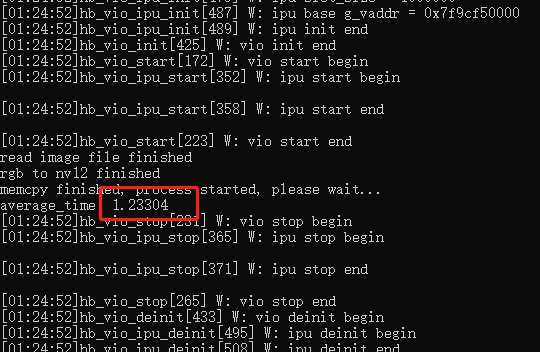
配置完毕后,可以修改启动脚本中的 -n 参数来对执行次数进行修改(默认 10000 次),设置好运行次数后执行该脚本,即可得到平均执行耗时,如图所示,平均耗时为 1.23 ms。
执行命令中添加 -o 选项,即可使程序输出缩放图片结果。结果会在 result 文件夹中进行存放,可下载到电脑端进行结果查看。

9.7. 如何进行 ROIresizer 模块耗时测试?¶
BPU 硬件中有一个 ROIresizer 模块可用于处理任意 tensor,可通过调用 API hbrtBilinearRoiResizeImage 来实现对图片的缩放处理,该示例代码可用于测试此模块缩放图片所需的时间。其中,输入图片的格式必须为 yuv420 NV12 的格式,输出图片格式为 yuv444。
使用时,将启动脚本中:
-l 参数设置为输入图片的大小,
-i 参数设置为输入图片的名称,
-d 参数设置为输出图片的大小,
-c 设置为循环次数(默认为 200 次)。
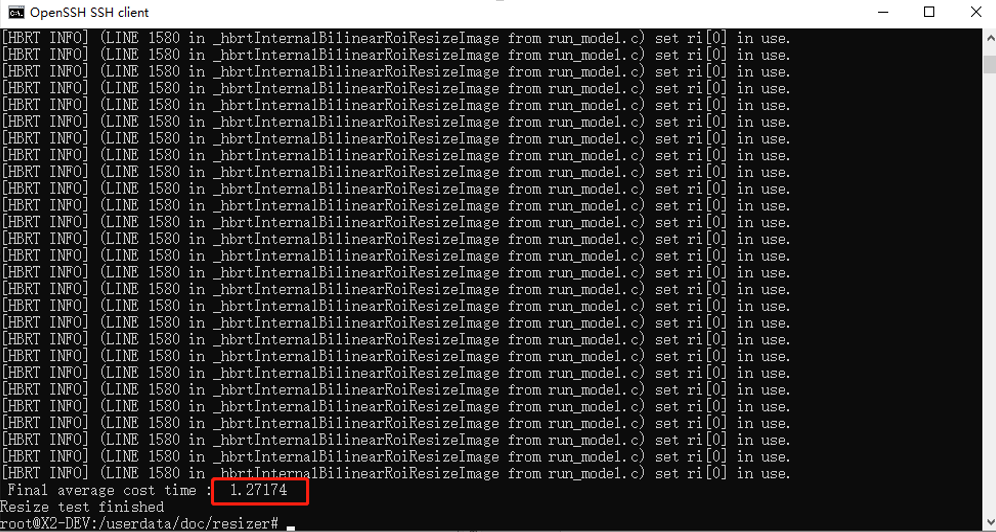
运行后程序会输出平均缩放耗时。如图所示,该平均缩放耗时为 1.27ms。