5. 算法模型开发¶
5.1. 算法模型的开发流程¶

根据业务需求和场景设计量化模型。
执行模型检查,如果过不了检查,则模型不能编译,此时需要修改模型以满足 X2/J2 对模型的限制,避免做无效的模型训练。
量化模型训练,训练后如果模型指标不达标,需要重新设计训练模型,以达到要求的指标。可以对超参数进行修改,例如 kernel size 和 stride。
将训练的模型进行转换并导出预测库版本的模型。
编译模型,把导出的预测模型通过 hbdk-cc 编译为可部署的 hbm 文件。
部署模型:把编译产生的 hbm 和运行时库(libhbrt_bernoulli_aarch64.so)放到开发板上,应用程序需要链接运行时库。
Note
如有问题,请联系地平线 HBDK 技术团队。
5.2. 数值量化方法¶
为了提升性能,降低功耗,同时保持网络 Inference 的较高精度,目前的主流 AI 加速器都使用较低的整数精度运算来替代浮点运算。虽然计算过程中数值的精度有损失,但是因为卷积神经网络本身的鲁棒性,经验证明这一精度损失较小。X2/J2 平台采用了移位这一硬件实现最高效的方式来量化网络中的浮点数。因此如果需要将网络 inference 的结果用于后处理,且需要在浮点数表示上做处理时,就需要反量化。
5.2.1. 原生 Inference 输出数据类型¶

在 X2/J2 BPU 计算阵列上,feature map 和 kernel 都是采用 int8 量化,卷积累加结果采用较高精度表示。因此,卷积运算输出时原生类型有两种。
- int8 输出
高精度数被量化后的输出。对应 disable_output_quantization=False,
- int32 输出
高精度卷积累加结果直接输出。对应 disable_output_quantization=True,
对于高精度 int32 输出,每个输出 channel 允许有一个单独的移位值,对应一种定点数转浮点数的方法。我们把这种方式叫 vector_quanti。
与预测库不同,disable_output_quantization=True 后,X2/J2 输出的是 int32 的整数,而 Tensorflow 预测库输出的是浮点数。如果想直接对比 X2/J2 与 Tensorflow 预测库的结果,需要将 X2/J2 的 int32 转换成浮点数,X2/J2 Compilation Tools 已经内置了该转换功能。
5.2.2. Inference 输出数据如何转成浮点数¶
为了方便算法模型开发与测试,我们需要将 X2/J2 输出的定点结果转成浮点数。基于 X2/J2 上的量化方法,将 inference 输出的某个整数 A 转成浮点数,采用公式 ((float)A)/(2^N)。其中,N 是转成浮点时使用的移位值。
对于上述两种不同的输出格式,该移位值的计算方法不同:
对于 int32 高精度输出结果:N = conv_input_feature_shift + conv_kernel_shift,其中:
input_feature_shift:卷积输入 feature map 相对浮点的移位值,该值是训练得到的。
conv_kernel_shift:卷积 kernel 相对于浮点的移位值,该值是训练的到的。
对于 int8 低精度量化输出结果:N = conv_output_shift_history,其中:
conv_output_shift_history:该 int8 数据相对浮点的移位值,该值是训练时得到的。
对于训练好的模型,高精度输出改成低精度输出需要重新训练。低精度输出改成高精度输出不需要重新训练。
5.3. 算法模型的限制¶
5.3.1. 支持的模型¶
目前主要支持的模型结构有:
检测
SSD
YOLOV3
Faster-RCNN
分类
Mobilenet V1
Mobilenet V2
ResNet18
ResNet50
VGG
分割
MobileNet-backbone 分割
Mask-RCNN
UNet
其它模型结构如果满足限制条件也可支持。
5.3.2. 模型网络结构限制¶
硬件原生支持的 layer 包括:
普通卷积(可带 element-wise sum),
depth-wise 卷积,
point-wise 卷积,
全连接层卷积,
pooling,
upcale(RoiResize),
roialign,
channel argmax,
threshold filter + sort + NMS,
channel concat。
除最后一层输出层 convolution 外,其它操作,包括 pooling,RoiResize 的结果都是 8 位有符号数,不能保存高精度结果。
如果卷积的输出结果是 int8 类型,则其输出结果可以是经过 ReLU 处理之后的,也可以不经过 Relu 处理。但如果卷积的输出结果是 int32 类型的,则卷积不能输出经过 Relu 处理之后的结果。
5.3.3. Operator 限制¶
Operator |
限制 |
|
普通卷积(Operator:QuantiConvolution) |
kernel HxW =[1,7]x[1,7] |
pad_h∈[0,Kh/2] pad_w∈[0,Kw/2] stride_H∈{1,2} stride_W∈{1,2} |
kernel数量 (K) |
k∈[1,2048], 模型输出k∈[1,4096] |
|
kernel通道 (C) |
c∈[1,2048], group conv中feature channel数是kernel channel数整数倍,kernel数是group数整数倍(group数=feature channel数/kernel channel数) |
|
kernel大小 (HxWxC) |
普通卷积,size∈[1, 32768]; |
|
全连接卷积(Operator: QuantiConvolution)注意:全连接层通过在卷积层中使用与feature map等大(HxWxC) 的kernel来实现。在模型描述中,使用卷积层表示全连接层。 |
kernel HxW = [1,32)x[1,32) |
pad∈{0} stride∈{1} |
kernel数量 (K) |
中间层FC k∈[1,2048] |
|
输出层FC k∈[1,16384] |
||
kernel通道 (C) |
1x1时c∈[1,16384] |
|
其它c∈[1,2048] |
||
kernel大小 (HxWxC) |
1x1时size∈[1,131072] |
|
其它size∈[1,100352] |
||
Pooling Average(Operator:QuantiPooling) |
kernel HxW = [1,7]x[1,7] |
pad_h∈[0,Kh/2] pad_w∈[0,Kw/2] stride∈{(1,1),(2,2)} |
Pooling Max(Operator: QuantiPooling) |
kernel HxW =2x2 |
pad∈{(0,0), (0,1), (1,0), (1,1)} stride∈{(1,1), (2,2)} |
kernel HxW =3x3 |
pad∈{(0,0), (0,1), (1,0), (1,1)} stride∈{(1,1), (2,2)} |
|
RoiResize(Operator: RoiAlign_X2, feature_map_resize_mode=True) |
H和W方向缩放比例范围可分别为[1/256, 256],缩放比例的精度是1/256 |
|
Channel argmax(Operator: QuantiChannelArgmax) |
C∈[1*num_group,64*num_group]当num_group大于1时,C必须是num_group的整数倍, |
|
Filter+Sort+NMS(三个操作不能单独执行)
(Operator: QuantiGetBBoxFromAnchors) |
Anchor数量∈(1,64)Class数量∈(1,64) Filter之后最多4096个box, 输出格式:128bit, [xmin,ymin,xmax,ymax,score,class,padding] [16bit,16bit,16bit,16bit,8bit,8bit,48bit] |
|
Channel concat/split(Operator: QuantiConcat/QuantiSplit) |
大的channel必须能被split的个数整除, split的输出tensors必须有相同的shape |
Note
上表中,数值取值范围之间有冲突的,以取值范围的交集为准。
5.3.4. 模型输入限制¶
数据来源
图像金字塔中某一层(包括原图)某个 ROI 的 image,
图像金字塔中某一层(包括原图)某个 ROI 经过 resize 之后的 image,
DDR 中的 feature map(需事先按照输入 layer 需要的格式保存到 DDR 中)。
数据大小
image (来自resizer或pyramid) 最大1x4095x4095x3,
输入 (H,W) 最大为 (4096,4096)
resizer 的输入限制:16byte <= width <= 2*dst_width, 16byte <= height <= 2*dst_height,
resize 之后的 image 大小限制详见 其他限制 ,
除模型的输出外,整个模型中所有的 feature map 中,单个 feature map 的 channel 数大小不能超过 2048,模型的输出 feature map 的 channel 数不能超过4096,
确保每个layer的inputs和outputs加起来size(N*H*W*C)不超过DDR的size(1GB)。
Note
实际支持的输入大小还取决于 DDR 空间大小。模型输入数量不超过 16。
5.3.5. 其他限制¶
Resizer 的限制
hbrt_ri_input_info_t.img_stride
hbrt_ri_input_info_t.img_h
hbrt_ri_input_info_t.img_w
hbrt_ri_input_info_t.hbrt_roi_t.coord
hbrt_ri_input_info_t.hbrt_roi_t.size
img_stride、img_h 和 img_w 用于描述原始图像的大小 (1x540x960x3)。其中,
img_w 和 img_h 必须为偶数。resize 之后的图像大小已经在命令行工具 hbdk-cc 的 -s 指定了。
img_w_stride 表示图像 Y 分量在 ddr 中每一行之间的距离(即,图像 Y 分量的相邻两行的起始数据的 ddr 地址的差值),img_w_stride 用于将图像 Y 分量的每一行数据按 ddr 存取的宽度进行对齐。例如:X2/J2 中按 16 对齐。
Coord 指明 ROI 左上角坐标,即抠图的范围。其中,左上坐标值必须为偶数,意味着 coord 的值都必须为偶数。
输入 resizer 的 ROI 的 H_input、W_input 需满足:32 <= H_input; 32 <= W_input,输出的 ROI 的 H_output, W_output 满足: 16 <= H_output; 16 <= W_output。
resizer 并不能无限放大或缩小抠图区域。resizer 宽度缩放范围 (0.5,4] 倍,高度缩放范围 (0.5,4] 倍。
5.4. 算法模型检查¶
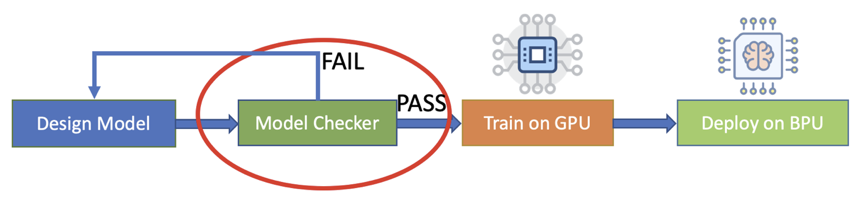
对于算法设计人员,想要知道设计的模型是否能够通过编译,可以直接用编译器编译,但是我们提供了更高效的工具 hbdk-model-check。
通常,此工具使用以下命令行运行:
Tensorflow 模型:
hbdk-model-check -f tf --march bernoulli -s 1x128x128x3 -m xxx.pb -i ddr
其中,
--march bernoulli
指定按照 X2/J2 BPU 的标准去检查,
-f mxnet/tf
指定神经网络模型(mxnet/tf),默认 mxnet,
-s 1x128x128x3
指定输入的形状,
-i ddr
指定模型输入类型,例如,ddr/pyramid/resizer。当模型被检查时,hbdk-model-check 工具需要知道 模型输入来源 的类型,用于检查模型是否满足输入类型的对齐要求。
当模型数据来自DDR时,数据没有对齐要求;
当模型数据来自 pyramid 时,数据的高度要求 2 对齐,宽度要求 16 对齐;
当数据来源于 resizer,请参见 其他限制 中的限制条件。这就意味着,当一个模型在输入数据来源于 DDR 时检查可以通过,不能够保证 数据来源于 pyramid 或 resizer 时可以被检查通过。
-m xxx.json/xxx.pb/xxx.bin
指定待检查的模型(mxnet:*.json; tensorflow:*.pb),
-p xxx.params
指定模型参数文件。若为 tensorflow 模型,则无需指定。当检查 mxnet Faster-RCNN/Mask-RCNN 模型时,必须给出参数文件。对于其他模型,可以省略该参数。
为了方便用户使用 python 开发模型,hbdk-model-check 提供了 python 接口。在工具包中的 python/hbcc/hbcc.py 文件中包含 modelCheck(*) 函数,只要 import hbcc 即可在用户自己的 python 代码中进行模型检查。
Tensorflow 模型
'''
@param symbol: 模型 pb 文件
@param march: 目标 BPU 平台
@param shape: 模型的输入 shape 'NxHxWxC',例如:'1x128x128x3'
@param input_type: 模型的输入类型,例如:'ddr'/'pyramid'/'resizer',默认 pyramid
@pe_num: (仅用于 darwin) PEs数量, 例如:2/4
@independent_pe: (仅用于 darwin) 每个 PE 独立工作,则设为 true
@output_nodes: 指定输出节点名称,用逗号隔开
@return: 检查通过,则返回0,否则,则返回非0
'''
def TensorflowModelCheck(symbol, march, shape, input_type=None, pe_num=0, independent_pe=None, output_nodes=None):
以下为 Tensorflow 模型检查使用示例,依赖于 Tensorflow Horizon 算法包:
#!/usr/bin/env python
import os, sys
import subprocess
# Set python path
p = subprocess.Popen(['hbcc-config'], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
out, err = p.communicate()
curr_path = out.strip().decode()
hbcc_python_path = curr_path + "/..//python/hbcc/"
sys.path.append(hbcc_python_path)
import hbcc
def runtensorflowmodelCheck():
## Step 1: import model protobuf file
f = open('model.pb', 'rb')
symbol = f.read()
f.close()
## Step 2: run hbcc model check
retcode = hbcc.TensorflowModelCheck (symbol, march='bernoulli', shape='1x256x256x3', input_type='pyramid')
if retcode != 0:
sys.exit(1)
if __name__ == '__main__':
runtensorflowmodelCheck()
sys.exit(0)