语音交互
- LLM 模型:Qwen2.5-1.5B
- ASR 模型:SenseVoice
- TTS 与 KWS 模型:Sherpa-onnx
- 语音流处理:https://github.com/D-Robotics/magicbox_audio_io
- 大语言模型:https://github.com/D-Robotics/magicbox_qwen_llm
- 灯光控制库:https://github.com/D-Robotics/magicbox_lighting_control
语音流处理功能说明
-
语音交互功能使用方法参见快速体验语音交互。
-
除了默认的持续对话模式外,还支持持续唤醒模式,即 “一唤醒一对话”。
- 可通过 “你好地瓜” 唤醒后进行一轮对话。
- 也可通过 “你好地瓜+问题内容” 直接进行对话。
-
检测到 “你好地瓜”后,灯光会闪烁。可通过修改
/userdata/magicbox/app/ros_ws/src/magicbox/magicbox_audio_io/launch/audio_io.launch.py中的continuous_wake_mode设置是否开启持续唤醒模式。-
设置方式 :使用脚本启动指令
ros2 launch audio_io audio_io.launch.py continuous_wake_mode:=true
-
-
该功能与
qwen_llm一起使用,所以会堵塞等待qwen_llm启动,若想单独使用可通过/userdata/magicbox/app/ros_ws/src/magicbox/magicbox_audio_io/launch/audio_io.launch.py中的wait_for_llm切换。-
设置方式 :使用脚本启动指令
ros2 launch audio_io audio_io.launch.py wait_for_llm:=false。
-
-
语音 TTS 内容播放完成且接收到
end消息之后重新开启麦克风(灯光常亮),end消息主要用于确认大模型已输出完成。 -
由于语音处理节点的初始化时间较久,该节点在开机后自动启动,按钮仅控制大语言模型节点的开启关闭,但两个节点会互相等待开启再进行工作。
-
更多参数说明以及编译方式请查看代码仓库中的 README 文件。
大语言模型功能说明
-
模型默认路径为
/dev/shm/qwen2.5-1.5b-instruct-q5_k_m.gguf,所以需要将模型先放入内存中,主要为避免按钮启动时初始化时间过久,更换模型路径请修改/userdata/magicbox/app/ros_ws/src/magicbox/magicbox_qwen_llm/launch/qwen_llm.launch.py中llm_model_path。 -
该功能包默认与
audio_io一起使用,所以会阻塞等待audio_io节点开启,若想单独使用可通过/userdata/magicbox/app/ros_ws/src/magicbox/magicbox_qwen_llm/launch/qwen_llm.launch.py中的wait_for_audio切换。-
设置方式:使用脚本启动指令
ros2 launch qwen_llm qwen_llm.launch.py wait_for_audio:=false。
-
-
更多参数说明以及编译方式请查看代码仓库中的 README 文件。
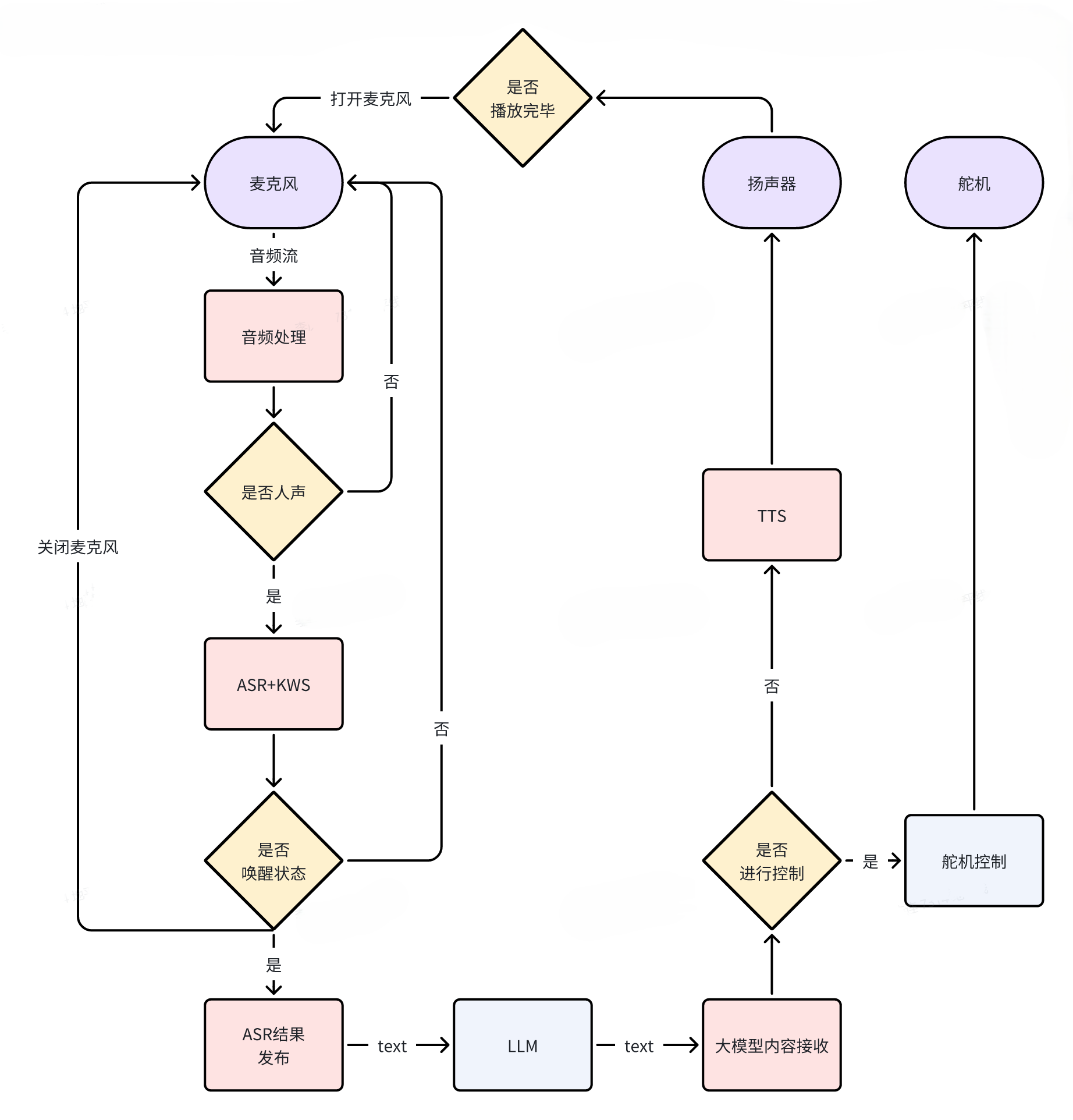
功能结构图
启动步骤
-
使用以下命令启动语音流处理。
#启动语音流处理
cd /userdata/magicbox
source /opt/tros/humble/setup.bash
source app/ros_ws/install/setup.bash
ros2 launch audio_io audio_io.launch.py
-
新建终端,使用以下命令启动大语言模型。
注意请先在
/userdata/magicbox/app/ros_ws/src/magicbox/magicbox_qwen_llm/launch/qwen_llm.launch.py中指定模型路径llm_model_path。#启动大语言模型
cd /userdata/magicbox
source /opt/tros/humble/setup.bash
source app/ros_ws/install/setup.bash
ros2 launch qwen_llm qwen_llm.launch.py