6.3.4. 模型量化与编译¶
转换模型阶段会完成浮点模型到地平线混合异构模型的转换,经过这个阶段,您将得到一个可以在地平线计算平台上运行的模型。 在进行转换之前,请确保已经顺利通过了 验证模型 小节的过程。
模型转换期间会完成模型优化和校准量化等重要过程,校准需要依照模型预处理要求准备校准数据, 您可以参考 校准数据准备 章节内容对校准数据进行预先准备。
6.3.4.1. 使用hb_mapper makertbin工具转换模型¶
模型转换过程使用 hb_mapper makertbin 工具完成,工具的使用方法及相关的具体配置、参数请参考 模型编译命令(hb_mapper makertbin) 章节。
6.3.4.2. 转换内部过程解读¶
模型转换完成浮点模型到地平线混合异构模型的转换。 为了使得这个异构模型能快速高效地在嵌入式端运行, 模型转换重点在解决 输入数据处理 和 模型优化编译 两个问题,本节会依次围绕这两个重点问题展开。
输入数据处理 方面地平线的边缘计算平台会为某些特定类型的输入通路提供硬件级的支撑方案,
但是这些方案的输出不一定符合模型输入的要求。
例如视频通路方面就有视频处理子系统,为采集提供图像裁剪、缩放和其他图像质量优化功能,这些子系统的输出往往是yuv420格式图像,
而我们的算法模型往往是基于bgr/rgb等一般常用图像格式训练得到的。
地平线针对此种情况提供的固定解决方案是,每个转换模型都提供两份输入信息描述,
一份用于描述原始浮点模型输入( input_type_train 和 input_layout_train),
另一份则用于描述我们需要对接的边缘平台输入数据( input_type_rt 和 input_layout_rt)。
图像数据的mean/scale也是比较常见的操作,显然yuv420等边缘平台数据格式不再适合做这样的操作, 因此,我们也将这些常见图像前处理固化到了模型中。 经过以上两种处理后,转换产出的异构模型的输入部分将变成如下图状态。

上图中的数据排布就只有NCHW和NHWC两种数据排布格式,N代表数量、C代表channel、H代表高度、W代表宽度, 两种不同的排布体现的是不同的内存访问特性。在TensorFlow模型中,NHWC格式较常用,而Caffe模型中就都使用NCHW格式, 地平线平台不会限制使用的数据排布,但是有两条要求:
input_layout_train必须与原始模型的数据排布一致。需要在边缘平台准备好与
input_layout_rt一致排布的数据,正确的数据排布指定是顺利解析数据的基础。
模型优化编译 方面完成了模型解析、模型优化、模型校准与量化、模型编译几个重要阶段,其内部工作过程如下图所示。
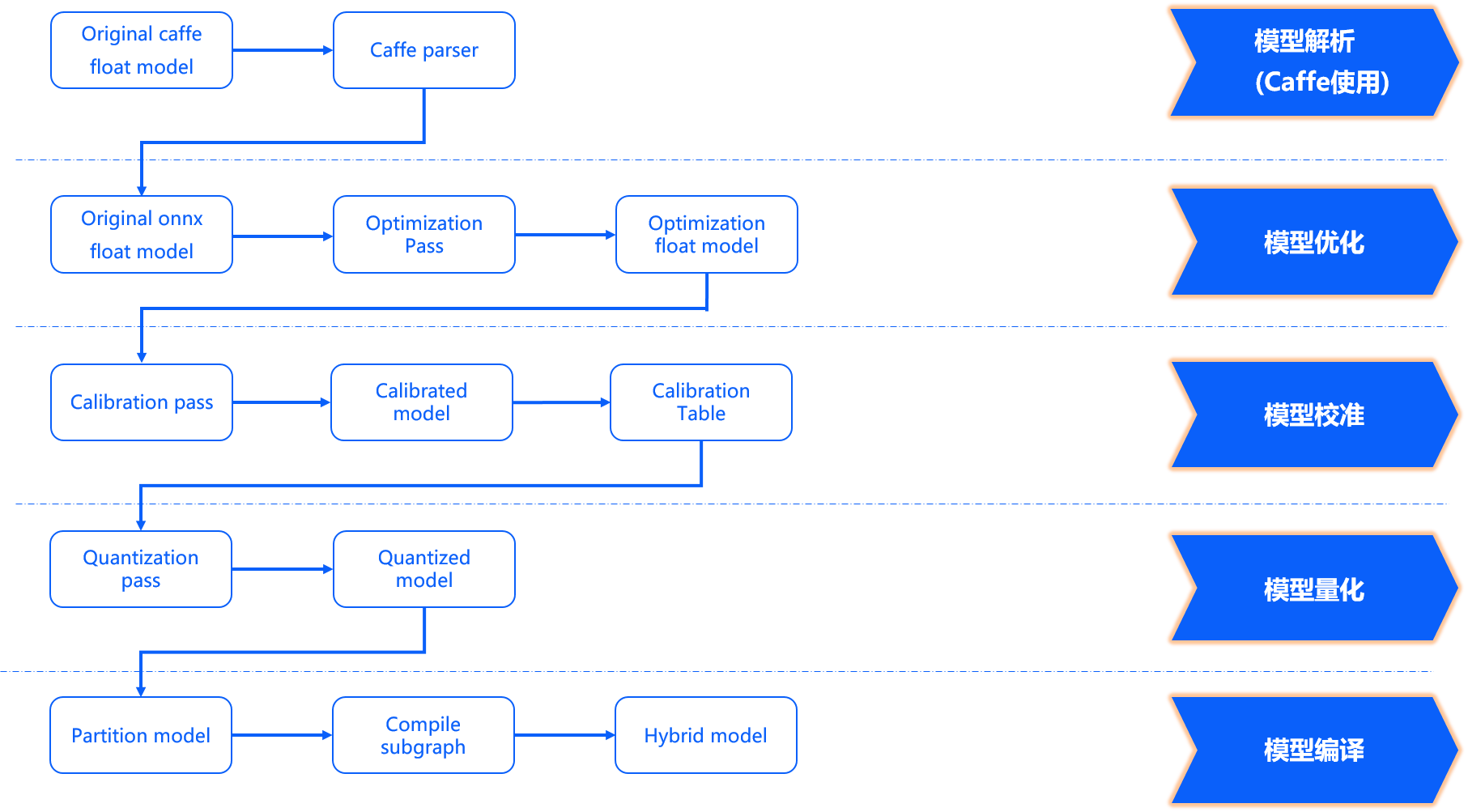
模型解析阶段 对于Caffe浮点模型会完成到ONNX浮点模型的转换。 在原始浮点模型上会根据转换配置中的配置参数决定是否加入数据预处理节点,此阶段产出一个original_float_model.onnx。 这个ONNX模型计算精度仍然是float32,在输入部分加入了一个数据预处理节点。
理想状态下,这个预处理节点应该完成 input_type_rt 到 input_type_train 的完整转换,
实际情况是整个type转换过程会配合地平线处理器硬件完成,ONNX模型里面并没有包含硬件转换的部分。
因此ONNX的真实输入类型会使用一种中间类型,这种中间类型就是硬件对 input_type_rt 的处理结果类型,
数据layout(NCHW/NHWC)会保持原始浮点模型的输入layout一致。
每种 input_type_rt 都有特定的对应中间类型,如下表:
nv12 |
yuv444 |
rgb |
bgr |
gray |
featuremap |
|---|---|---|---|---|---|
yuv444_128 |
yuv444_128 |
RGB_128 |
BGR_128 |
GRAY_128 |
featuremap |
注解
表格中第一行加粗部分是 input_type_rt 指定的数据类型,第二行是特定 input_type_rt 对应的中间类型,
这个中间类型就是original_float_model.onnx的输入类型。其中:
*_128指的是其数据类型减去128的结果,每个数值采用int8表示。
featuremap 是一个张量数据,每个数值采用float32表示。
模型优化阶段 实现模型的一些适用于地平线平台的算子优化策略,例如BN融合到Conv等。 此阶段的产出是一个optimized_float_model.onnx,这个ONNX模型的计算精度仍然是float32,经过优化后不会影响模型的计算结果。 模型的输入数据要求还是与前面的original_float_model一致。
模型校准阶段 会使用您提供的校准数据来计算必要的量化参数,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中,此阶段的产出是calibrated_model.onnx。
模型量化阶段 使用校准得到的参数完成模型量化,此阶段的产出是一个quantized_model.onnx。
这个模型的计算精度已经是int8,使用这个模型可以评估到模型量化带来的精度损失情况。
这个模型要求输入的基本数据格式和layout仍然与 original_float_model 一样,不过取值范围已经发生了变化,
整体较于 original_float_model 输入的变化情况描述为:
当 input_type_rt 的取值为非 featuremap 时,则输入的数据类型均使用INT8, 反之, 当 input_type_rt 取值为 featuremap 时,则输入的数据类型则为float32。
数据排布layout关系为:input_layout_train以及origin.onnx、calibrated_model.onnx、quanti.onnx输入的layout与原模型输入的layout一致。
注意
请注意,如果input_type_rt为nv12,对应quanti.onnx的输入layout都是NHWC。
模型编译阶段 会使用地平线模型编译器,将量化模型转换为地平线平台支持的计算指令和数据, 这个阶段的产出一个*.bin模型,这个bin模型是后续将在地平线边缘嵌入式平台运行的模型,也就是模型转换的最终产出结果。
6.3.4.3. 转换结果解读¶
本节将依次介绍模型转换成功状态的解读、转换不成功的分析方式。
确认模型转换成功,需要您从 makertbin 状态信息、相似度信息和 working_dir 产出三个方面确认。
makertbin 状态信息方面,转换成功将在控制台输出信息尾部给出明确的提示信息如下:
2023-12-06 11:13:08,337 INFO Convert to runtime bin file successfully!
2023-12-06 11:13:08,337 INFO End Model Convert
相似度信息也存在于 makertbin 的控制台输出内容中,在 makertbin 状态信息之前,其内容形式如下:
======================================================================
Node ON Subgraph Type Cosine Similarity Threshold
----------------------------------------------------------------------
... ... ... ... 0.999936 127.000000
... ... ... ... 0.999868 2.557209
... ... ... ... 0.999268 2.133924
... ... ... ... 0.996023 3.251645
... ... ... ... 0.996656 4.495638
上面列举的输出内容中:
Node、ON、Subgraph、Type与
hb_mapper checker工具的解读是一致的,请参考前文 检查结果解读 。Cosine Similarity反映的Node指示的节点中,原始浮点模型与量化模型输出结果的余弦相似度。
Threshold是每个层次的校准阈值,用于异常状态下向地平线技术支持反馈信息,正常状况下不需要关注。
注意
需要您特别注意的是,Cosine Similarity只是指明量化后数据稳定性的一种参考方式,对于模型精度的影响不存在明显的直接关联关系。 一般情况下,输出节点的相似度低于0.8就有了较明显的精度损失,当然由于与精度不存在绝对的直接关联, 完全准确的精度情况还需要您参考 模型精度分析 的介绍。
转换产出存放在转换配置参数 working_dir 指定的路径中,成功完成模型转换后,
您可以在该目录下得到以下文件(*部分是您通过转换配置参数 output_model_file_prefix 指定的内容):
*_original_float_model.onnx
*_optimized_float_model.onnx
*_calibrated_model.onnx
*_quantized_model.onnx
*.bin
转换产出物解读 介绍了每个产出物的用途。 不过在上板运行前,我们强烈建议您完成 模型性能分析 和 模型精度分析 章节介绍的性能&精度评测过程,避免将模型转换问题延伸到后续嵌入式端。
如果以上验证模型转换成功的三个方面中,有任一个出现缺失都说明模型转换出现了错误。
一般情况下, makertbin 工具会在出现错误时将错误信息输出至控制台,
例如我们在Caffe模型转换时不配置 prototxt 和 caffe_model 参数,工具给出如下提示。
2023-12-06 14:45:34,085 ERROR Key 'model_parameters' error:
Missing keys: 'caffe_model', 'prototxt'
2023-12-06 14:45:34,085 ERROR yaml file parse failed. Please double check your input
2023-12-06 14:45:34,085 ERROR exception in command: makertbin
如果以上步骤不能帮助您发现问题,欢迎在 地平线官方技术社区 提出您的问题, 我们将在24小时内给您提供支持。
6.3.4.4. 转换产出物解读¶
上文提到模型成功转换的产出物包括以下部分,本节将介绍每个产出物的用途:
*_original_float_model.onnx
*_optimized_float_model.onnx
*_calibrated_model.onnx
*_quantized_model.onnx
*.bin
*_original_float_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型计算精度与转换输入的原始浮点模型是一模一样的,有个重要的变化就是为了适配地平线平台添加了一些数据预处理计算。 一般情况下,您不需要使用这个模型,在转换结果出现异常时,如果能把这个模型提供给地平线的技术支持,将有助于帮助您快速解决问题。
*_optimized_float_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型经过一些算子级别的优化操作,常见的就是算子融合。 通过与original_float模型的可视化对比,您可以明显看到一些算子结构级别的变化,不过这些都不影响模型的计算精度。 一般情况下,您不需要使用这个模型,在转换结果出现异常时,如果能把这个模型提供给地平线的技术支持,将有助于帮助您快速解决问题。
*_calibrated_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型是模型转换工具链将浮点模型经过结构优化后,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中得到的中间产物。
*_quantized_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型已经完成了校准和量化过程,量化后的精度损失情况可以从这里查看。 这个模型是精度验证过程中必须要使用的模型,具体使用方式请参考 模型精度分析 部分的介绍。
*.bin就是可以用于在地平线计算平台上加载运行的模型, 配合 嵌入式应用开发指导 部分介绍的内容, 您就可以将模型快速在计算平台上部署运行。不过为了确保模型的性能与精度效果是符合您的预期的, 我们强烈建议完成 模型性能分析 和 模型精度分析 介绍的性能和精度分析过程后再进入到应用开发和部署。