6.3.2. 验证模型¶
为了确保模型能顺利在地平线平台高效运行,模型中所使用的算子需要符合平台的算子约束。 算子约束部分给出了我们支持的具体算子,每个算子都给出了具体的参数限制, 具体详细信息请参考 工具链算子支持约束列表 章节的内容。
6.3.2.1. 使用hb_mapper checker工具验证模型¶
考虑到地平线支持的算子较多,为了避免人工逐条校对的麻烦,我们提供了 hb_mapper checker 工具用于验证模型所使用算子的支持情况。
工具使用方法请参考 模型检查命令(hb_mapper checker) 章节。
6.3.2.2. 检查异常处理¶
如果模型检查不通过, hb_mapper checker 工具会报出ERROR。
在当前工作目录下会生成 hb_mapper_checker.log 文件,从文件中可以查看到具体的报错。
例如以下配置中含不可识别算子类型 Accuracy:
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 224 dim: 224 } }
}
layer {
name: "Convolution1"
type: "Convolution"
bottom: "data"
top: "Convolution1"
convolution_param {
num_output: 128
bias_term: false
pad: 0
kernel_size: 1
group: 1
stride: 1
weight_filler {
type: "msra"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "Convolution3"
top: "accuracy"
include {
phase: TEST
}
}
使用 hb_mapper checker 检查这个模型,您会在 hb_mapper_checker.log 中得到如下信息:
ValueError: Not support layer name=accuracy type=Accuracy
6.3.2.3. 检查结果解读¶
如果不存在ERROR,则顺利通过校验。 hb_mapper checker 工具将直接输出如下信息:
==============================================
Node ON Subgraph Type
----------------------------------------------
conv1 BPU id(0) HzSQuantizedConv
conv2_1/dw BPU id(0) HzSQuantizedConv
conv2_1/sep BPU id(0) HzSQuantizedConv
conv2_2/dw BPU id(0) HzSQuantizedConv
conv2_2/sep BPU id(0) HzSQuantizedConv
conv3_1/dw BPU id(0) HzSQuantizedConv
conv3_1/sep BPU id(0) HzSQuantizedConv
...
结果中每行都代表一个模型节点的check情况,每行含Node、ON、Subgraph和Type四列, 分别为节点名称、执行节点计算的硬件、节点所属子图和节点映射到的地平线内部实现名称。 如果模型在非输入和输出部分出现了CPU计算的算子,工具将把这个算子前后连续在BPU计算的部分拆分为两个Subgraph(子图)。
6.3.2.4. 检查结果的调优指导¶
在最理想的情况下,非输入和输出部分都应该在BPU上运行,也就是只有一个子图。
如果出现了CPU算子导致拆分多个子图, hb_mapper checker 工具会给出导致CPU算子出现的具体原因。
例如以下ONNX模型的出现了Mul + Add + Mul的结构,从算子约束列表中我们可以看到,Mul和Add算子在五维上支持BPU运行有约束条件。
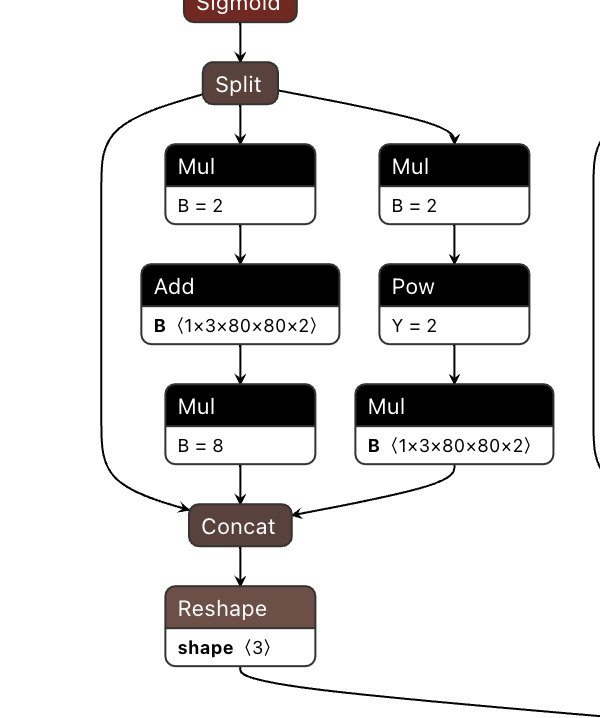
因此模型最终检查结果也会出现分段情况,如下:
====================================================================================
Node ON Subgraph Type
-------------------------------------------------------------------------------------
Reshape_199 BPU id(0) Reshape
Transpose_200 BPU id(0) Transpose
Sigmoid_201 BPU id(0) HzLut
Split_202 BPU id(0) Split
Mul_204 CPU -- Mul
Add_206 CPU -- Add
Mul_208 CPU -- Mul
Mul_210 CPU -- Mul
Pow_211 BPU id(1) HzLut
Mul_213 CPU -- Mul
Concat_214 CPU -- Concat
Reshape_215 CPU -- Reshape
Conv_216 BPU id(0) HzSQuantizedConv
Reshape_217 BPU id(0) Reshape
Transpose_218 BPU id(0) Transpose
Sigmoid_219 BPU id(0) HzLut
Split_220 BPU id(0) Split
Mul_222 CPU -- Mul
Add_224 CPU -- Add
Mul_226 CPU -- Mul
Mul_228 CPU -- Mul
Pow_229 BPU id(2) HzLut
Mul_231 CPU -- Mul
Concat_232 CPU -- Concat
Reshape_233 CPU -- Reshape
Conv_234 BPU id(0) HzSQuantizedConv
Reshape_235 BPU id(0) Reshape
Transpose_236 BPU id(0) Transpose
Sigmoid_237 BPU id(0) HzLut
Split_238 BPU id(0) Split
Mul_240 CPU -- Mul
Add_242 CPU -- Add
Mul_244 CPU -- Mul
Mul_246 CPU -- Mul
Pow_247 BPU id(3) HzLut
Mul_249 CPU -- Mul
Concat_250 CPU -- Concat
Reshape_251 CPU -- Reshape
Concat_252 CPU -- Concat
注意
请注意,这里log结果仅用作示例,在使用过程中,请以您使用的版本实际打印的log情况为准。
根据 hb_mapper checker 给出的提示,一般来说算子运行在BPU上会有更好的性能表现。 当然,多个子图也不会影响整个转换流程,但会较大程度地影响模型性能,建议尽量调整至全BPU执行。