6.3.5. 模型性能分析¶
本节介绍了如何使用地平线提供的工具评估模型性能。 如果此阶段发现评估结果不符合预期,强烈建议您尽量在此阶段参考 模型性能调优 章节的内容尝试调优,解决性能问题, 不建议将模型的问题延伸到应用开发阶段。
6.3.5.1. 使用 hb_perf 工具估计性能¶
地平线提供的 hb_perf 以模型转换得到的 *.bin为输入,可以直接得到模型预期上板性能(不含CPU部分的计算评估),工具使用方式如下:
hb_perf ***.bin
注解
如果分析的是 pack 后模型,需要加上一个 -p 参数,命令为 hb_perf -p ***.bin。
关于模型 pack,请查看 hb_pack 工具 部分的介绍。
命令中的 *.bin就是模型转换产出的bin模型,命令执行完成后,
在当前工作目录下会得到一个 hb_perf_result 目录,分析结果以html形式提供。
以下是我们分析一个MobileNet的示例结果,其中mobilenetv1_224x224_nv12.html就是查看分析结果的主页面。
hb_perf_result/
└── mobilenetv1_224x224_nv12
├── MOBILENET_subgraph_0.html
├── MOBILENET_subgraph_0.json
├── mobilenetv1_224x224_nv12
├── mobilenetv1_224x224_nv12.html
├── mobilenetv1_224x224_nv12.png
└── temp.hbm
通过浏览器打开结果主页面,其内容如下图:
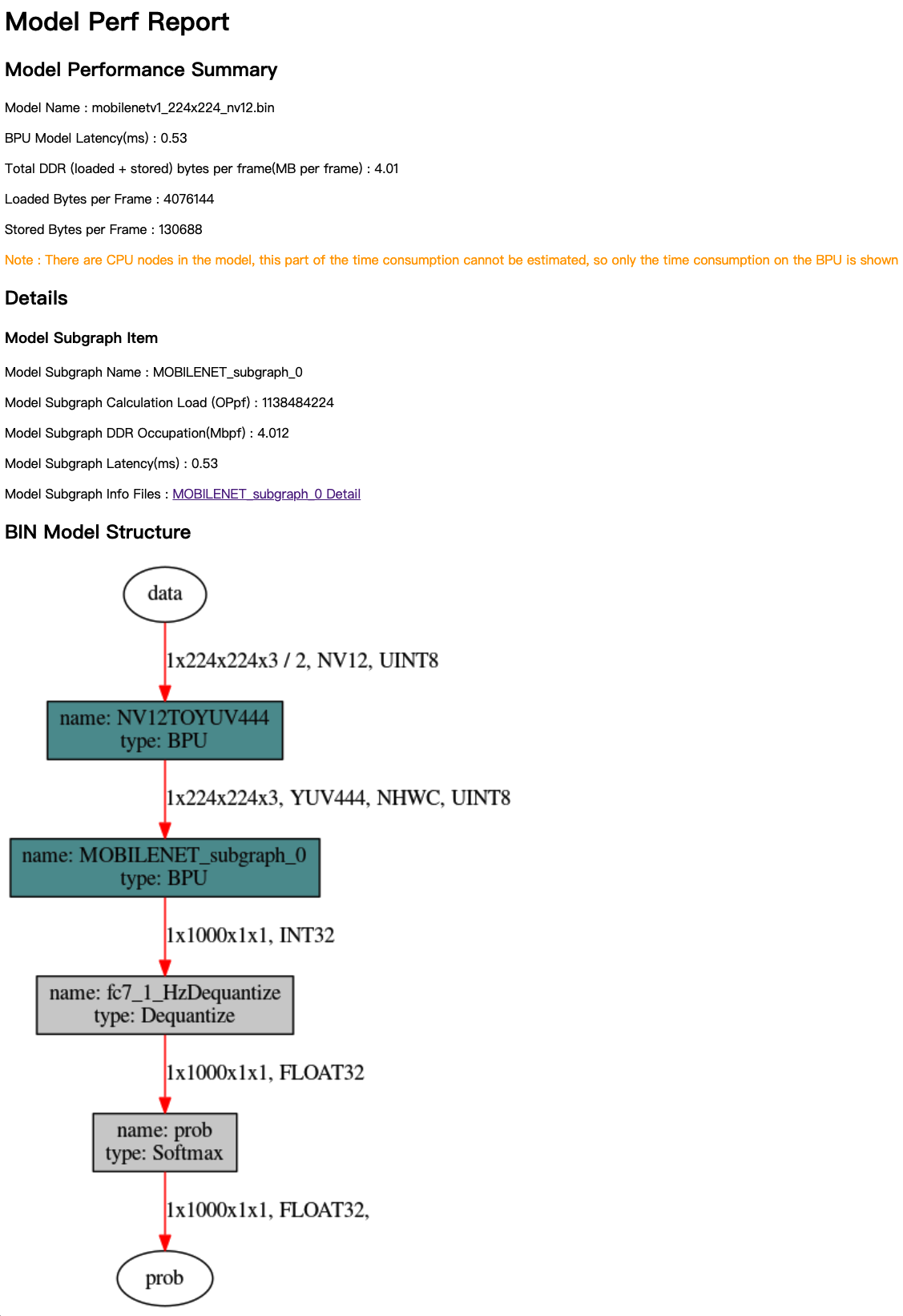
分析结果主要由Model Performance Summary、Details和BIN Model Structure三个部分组成。 Model Performance Summary是整个bin模型的整体性能评估结果,其中各项指标为:
Model Name:模型名称。
BPU Model Latency(ms):模型整体单帧计算耗时(单位为ms)。
Total DDR (loaded+stored) bytes per frame(MB per frame):模型整体BPU部分数据加载和存储所占用的DDR总量(单位为MB/frame)。
Loaded Bytes per Frame:模型运行每帧读取数据量。
Stored Bytes per Frame:模型运行每帧存储数据量。
在了解Details和BIN Model Structure前,您需要了解子图(subgraph)的概念。 如果模型在非输入和输出部分出现了CPU计算的算子,模型转换工具将把这个算子前后连续在BPU计算的部分拆分为两个独立的子图(subgraph)。 具体可以参考 验证模型 部分的介绍。
Details是每份模型BPU子图的具体信息,在主页面中,每个子图提供的指标解读如下:
Model Subgraph Name:子图名称。
Model Subgraph Calculation Load (OPpf):子图的单帧计算量。
Model Subgraph DDR Occupation(Mbpf):子图的单帧读写数据量(单位为MB)。
Model Subgraph Latency(ms):子图的单帧计算耗时(单位为ms)。
每份子图结果提供了一个明细入口,以上指标都是明细页面提取到的,进入到明细页面可以给您更加细致的参考信息。
注意
需要特别注意的是,明细页面会根据您是否启用调试参数( debug )而有所区别,
下方的Layer Details仅当在配置文件中设置 debug 参数为 True 时才可以拿到,
这个 debug 参数配置方法请参考 编译参数组 内对该参数的介绍。
BIN Model Structure部分提供的是bin模型的子图级可视化结果,图中深色节点表示运行在BPU上的节点,灰色节点表示在CPU上计算的节点。
Layer Details提供到了具体算子级别的分析,在调试分析阶段也是比较不错的参考, 如果是某些BPU算子导致性能低,可以帮助您定位到这个具体算子。

其中,每项指标解读如下:
layer:layer名。
ops:计算量。
original output shape:原始算子输出shape。
aligned output shape:对齐后的算子输出shape。
computing cost (no DDR):计算耗时。
load/store cost:数据搬运耗时。
active period of time:编译后layer活跃时间段(不代表该layer执行时间,通常为多个layer交替/并行执行)。
使用 hb_perf 的意义在于了解bin模型子图结构,对于BPU上计算部分,该工具也能提供较全面的静态分析指标。
不过 hb_perf 不含CPU部分的计算评估,如果CPU计算仅限于模型输入或输出部分的常规性处理,不含计算密集型计算节点,这个影响不大。
否则,您就一定需要利用开发板工具实测性能。
6.3.5.2. 开发板实测性能¶
开发板上实测模型性能使用的是开发板上 hrt_model_exec perf 工具,
hrt _model_exec 是一个模型执行工具,可直接在开发板上评测模型的推理性能、获取模型信息。
一方面可以让您在拿到模型时实际了解模型真实性能,另一方面也可以帮助您了解模型可以做到的速度极限,对于应用调优的目标极限具有指导意义。
使用 hrt_model_exec perf 工具前,有两个准备工作。
确保您已经参考 环境部署 介绍完成了开发板上工具安装。
第二是需要将Ubuntu开发机上得到的bin模型拷贝到开发板上(建议放在/userdata目录), 开发板上是一个Linux系统,可以通过
scp等Linux系统常用方式完成这个拷贝过程。
注解
此时使用的模型不需要打开debug,debug打开会影响模型在开发板的测试结果。
使用 hrt_model_exec perf 实测性能的参考命令如下(注意是在开发板上执行):
./hrt_model_exec perf --model_file mobilenetv1_224x224_nv12.bin \
--model_name="" \
--core_id=0 \
--frame_count=200 \
--perf_time=0 \
--thread_num=1 \
--profile_path="."
其中,各参数含义如下:
参数 |
说明 |
|---|---|
model_file |
需要分析性能的bin模型名称。 |
model_name |
需要分析性能的bin模型名字。若 |
core_id |
默认值 |
frame_count |
默认值 |
perf_time |
默认值 |
thread_num |
默认值 |
profile_path |
默认关闭,统计工具日志产生路径。该参数引入的分析结果会存放在指定目录下的profiler.log和profiler.csv文件中。 |
命令执行完成后,您将在控制台得到如下结果。
最终的评估结果就是 Average latency 和 Frame rate,分别表示平均单帧推理延时和模型极限帧率。
如果想获得模型在板子上运行的极限帧率,需将 thread_num 设置得足够大。
Running condition:
Thread number is: 4
Frame count is: 1000
Program run time: 279.004000 ms
Perf result:
Frame totally latency is: 1084.040527 ms
Average latency is: 1.084041 ms
Frame rate is: 3584.178005 FPS
控制台得到的信息只有整体情况,通过 profile_path 控制产生的 profiler.log 和 profiler.csv 文件记录了更加丰富的信息如下:
{
"perf_result": {
"FPS": 3718.384436330103,
"average_latency": 1.0366870164871216
},
"running_condition": {
"core_id": 0,
"frame_count": 1000,
"model_name": "mobilenetv1_224x224_nv12",
"run_time": 268.934,
"thread_num": 4
}
}
***
{
"processor_latency": {
"BPU_inference_time_cost": {
"avg_time": 0.8493590000000001,
"max_time": 1.328,
"min_time": 0.766
},
"CPU_inference_time_cost": {
"avg_time": 0.074976,
"max_time": 0.382,
"min_time": 0.066
}
},
"model_latency": {
"BPU_MOBILENET_subgraph_0": {
"avg_time": 0.8493590000000001,
"max_time": 1.328,
"min_time": 0.766
},
"Dequantize_fc7_1_HzDequantize": {
"avg_time": 0.029727,
"max_time": 0.124,
"min_time": 0.028
},
"MOBILENET_subgraph_0_output_layout_convert": {
"avg_time": 0.011379,
"max_time": 0.077,
"min_time": 0.008
},
"Preprocess": {
"avg_time": 0.005363000000000001,
"max_time": 0.039,
"min_time": 0.003
},
"Softmax_prob": {
"avg_time": 0.028507,
"max_time": 0.142,
"min_time": 0.027
}
},
"task_latency": {
"TaskPendingTime": {
"avg_time": 0.021235,
"max_time": 0.336,
"min_time": 0.002
},
"TaskRunningTime": {
"avg_time": 0.983558,
"max_time": 2.208,
"min_time": 0.904
}
}
}
这里的内容会对应到 使用hb_perf工具估计性能 中的BIN Model Structure部分介绍的bin可视化图中, 图中每个节点都有一个对应节点在profiler.log文件中,
可以通过 name 对应起来。 profiler.log 文件中记录了每个节点的执行时间,对优化节点有重要的参考意义。
由于模型中的BPU节点对输入输出有特殊要求,如特殊的layout和padding对齐要求,因此需要对BPU节点的输入、输出数据进行处理:
Preprocess:表示对模型输入数据进行padding和layout转换操作,其耗时统计在Preprocess中。xxxx_input_layout_convert: 表示对BPU节点的输入数据进行padding和layout转换的操作,其耗时统计在xxxx_input_layout_convert中。xxxx_output_layout_convert: 表示对BPU节点输出数据进行去掉padding和layout转换的操作,其耗时统计在xxxx_output_layout_convert中。
profiler 分析是经常使用的操作,前文 检查结果解读 部分提到检查阶段不用过于关注CPU算子, 此阶段就能看到CPU算子的具体耗时情况了,如果根据这里的评估认为CPU耗时太长,那就值得优化了。