4.2.3.2. 算子融合¶
4.2.3.2.1. 为什么要做算子融合¶
简单来说,算子融合既可以加快计算速度,又可以提高量化精度
4.2.3.2.2. 加快计算速度¶
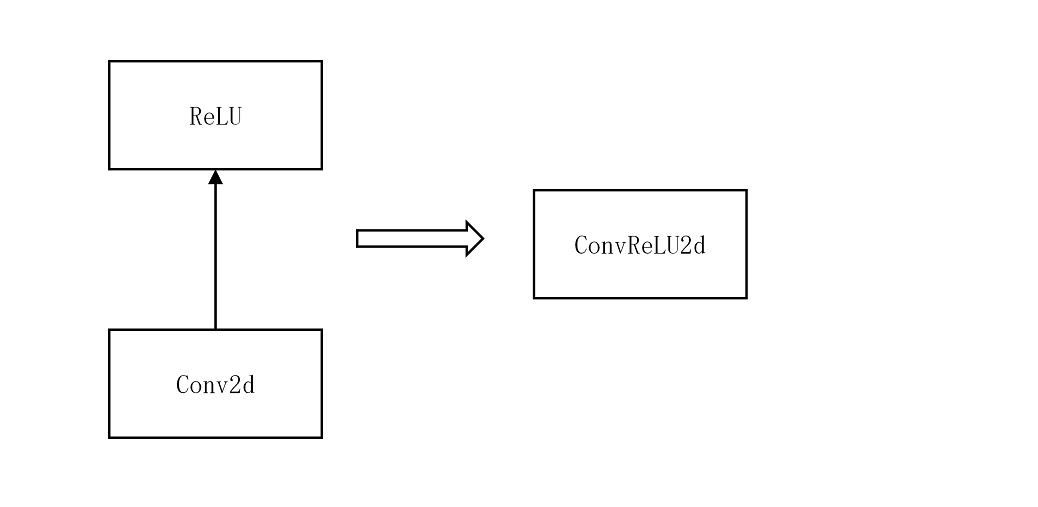
例如,把 Conv,ReLU进行融合成 ConvReLU2d,如下左图,ReLU 读取 Conv 的计算结果,然后进行计算,而右图 ConvReLU2d 直接把 Conv 的结果现场计算,节省了读取数据的过程,因此可以加快计算速度。
这是一个简单的例子,现实中会比这个复杂很多
4.2.3.2.3. 提高量化精度¶
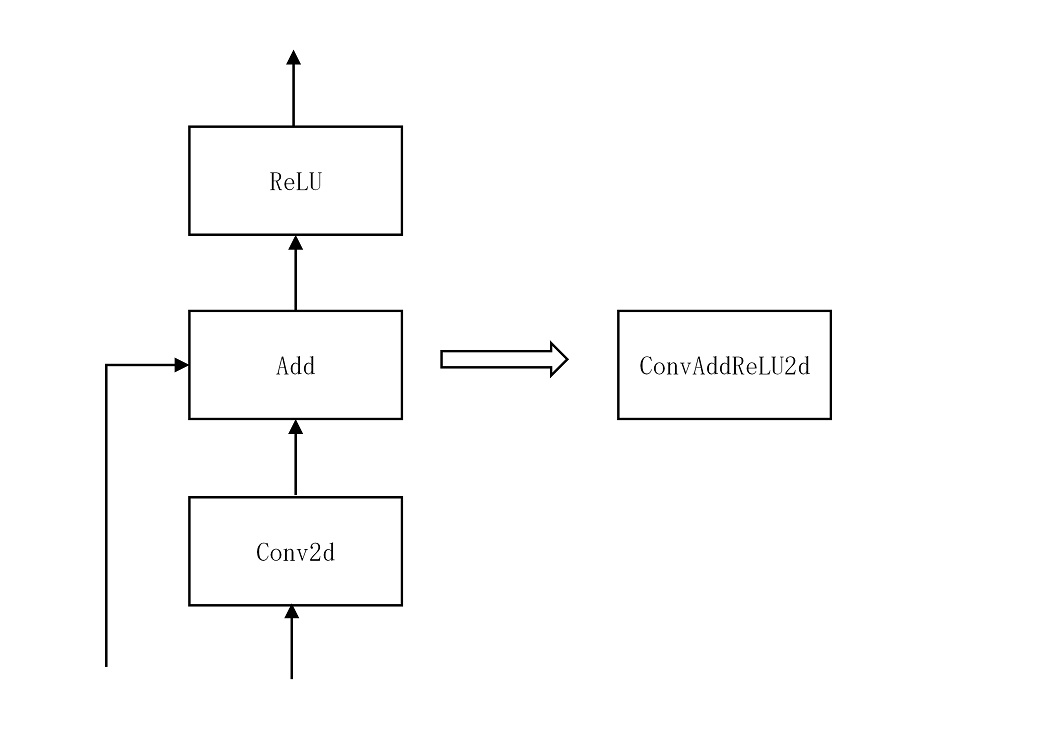
如下图所示,如果各个算子独立计算,那么,每个算子的输出都是 8bit 的数据,而如果是使用算子融合,那么,Conv0 的输出是 32bit 数据。
4.2.3.2.4. 可以融合的算子¶
from torch import nn
import torch.nn.quantized as nnq
# 目前支持以下算子的融合
(nn.Conv2d, nn.BatchNorm2d, nn.ReLU)
(nn.Conv2d, nn.ReLU)
(nn.Conv2d, nn.BatchNorm2d, nnq.FloatFunctional)
(nn.Conv2d, nn.BatchNorm2d, nnq.FloatFunctional, nn.ReLU)
(nn.Conv2d, nnq.FloatFunctional)
(nn.Conv2d, nnq.FloatFunctional, nn.ReLU)
(nn.ConvTranspose2d, nn.ReLU)
(nn.ConvTranspose2d, nnq.FloatFunctional)
(nn.ConvTranspose2d, nnq.FloatFunctional, nn.ReLU)
(nn.ConvTranspose2d, nn.BatchNorm2d)
(nn.ConvTranspose2d, nn.BatchNorm2d, nn.ReLU)
(nn.ConvTranspose2d, nn.BatchNorm2d, nnq.FloatFunctional)
(nn.ConvTranspose2d, nn.BatchNorm2d, nnq.FloatFunctional, nn.ReLU)
(nn.Conv2d, nn.BatchNorm2d, nn.ReLU6)
(nn.Conv2d, nn.ReLU6)
(nn.Conv2d, nn.BatchNorm2d, nnq.FloatFunctional, nn.ReLU6)
(nn.Conv2d, nnq.FloatFunctional, nn.ReLU6)
(nn.ConvTranspose2d, nn.ReLU6)
(nn.ConvTranspose2d, nnq.FloatFunctional, nn.ReLU6)
(nn.ConvTranspose2d, nn.BatchNorm2d, nn.ReLU6)
(nn.ConvTranspose2d, nn.BatchNorm2d, nnq.FloatFunctional, nn.ReLU6)
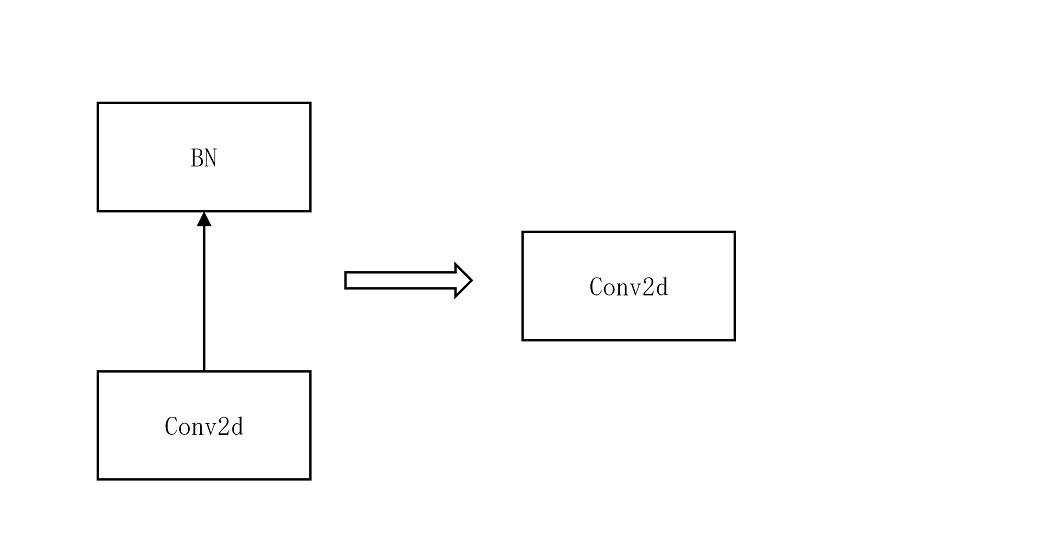
4.2.3.2.5. 吸收 BN 的目的¶
吸收 BN 的目的是为了减少部署模型的计算量。因为 BN 是线性变换过程,因此,当 BN 和 Conv 一起出现的时候,可以把 BN 的变换参数吸收到 Conv 的参数中去,从而,在部署的模型中消除 BN 的计算。
通过吸收 BN,把 ConvBN2d 变换成了 Conv2d 。
4.2.3.2.6. 吸收 BN 的方法¶
目前工具支持 Conv -> BN 的模式吸收 BN。
吸收方法如下:
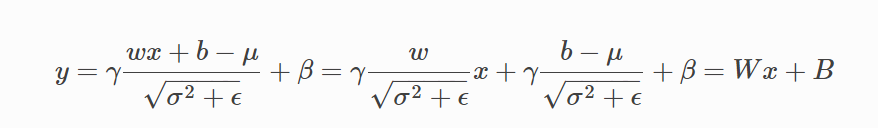
4.2.3.2.7. 算子融合示例¶
示例 1:取算子下标进行融合
import torch
import horizon_plugin_pytorch as horizon
from torch.quantization import DeQuantStub
from horizon_plugin_pytorch.quantization import QuantStub
class ModelForFusion(torch.nn.Sequential):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
dequant_out=False,
):
super(ModelForFusion, self).__init__(
QuantStub(),
nn.Conv2d(
in_channels,
out_channels,
kernel_size,
),
nn.BatchNorm2d(num_features=out_channels),
DeQuantStub() if dequant_out else nn.Identity(),
)
float_net = ModelForFusion(
1,
2,
1,
)
# 由于需要融合的网络是继承自 torch.nn.Sequential 的网络, 取 conv 和 bn 在
# 网络中的下标放入列表中来确定要融合的算子
torch.quantization.fuse_modules(
float_net, ["1", "2"], inplace=True, fuser_func=horizon.quantization.fuse_known_modules
)
示例 2:用算子名放在列表中进行融合
from torch import nn
class ModelForFusion(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(2, 2, 1, bias=None)
self.bn = nn.BatchNorm2d(2)
self.relu = nn.ReLU(inplace=True)
self.quant = QuantStub()
self.dequant = DeQuantStub()
def forward(self, x):
x_i = self.quant(x)
x = self.conv(x_i)
x = self.bn(x)
x = self.relu(x)
x = self.dequant(x)
return x
model = ModelForFusion().train()
# 由于网络是继承自 Module 的网络,网络中的每个算子都有一个变量名,
# 取网络中 conv 和 bn 的变量名放入列表中进行融合
torch.quantization.fuse_modules(
model,
["conv", "bn", "relu"],
inplace=True,
fuser_func=horizon.quantization.fuse_known_modules,
)