7.4.6. 精度调优工具使用指南¶
由于浮点转定点过程中存在误差,当您在使用量化训练工具时,难免会碰到量化模型精度掉点问题。通常来说,造成掉点的原因有两大类:
原有浮点模型不利于量化,如存在共享 op 或共享结构;
QAT 网络结构或配置异常,如模型中存在没有 fuse 的 pattern,没有设置高精度输出等;
某些算子对量化比较敏感,该算子的量化误差在前向传播过程中逐层累积,最终导致模型输出误差较大。
针对上述情况,量化训练工具提供了精度调优工具来帮助您快速定位并解决精度问题,主要包括如下模块:
模型结构检查:检查模型中是否存在共享 op、没有 fuse 的 pattern 或者不符合预期的量化配置;
QuantAnalysis:自动比对分析两个模型,定位到量化模型中异常算子或者量化敏感 op;
ModelProfiler:获得模型中每一个 op 的数值特征信息,如输入输出的最大最小值等。
7.4.6.1. 快速上手¶
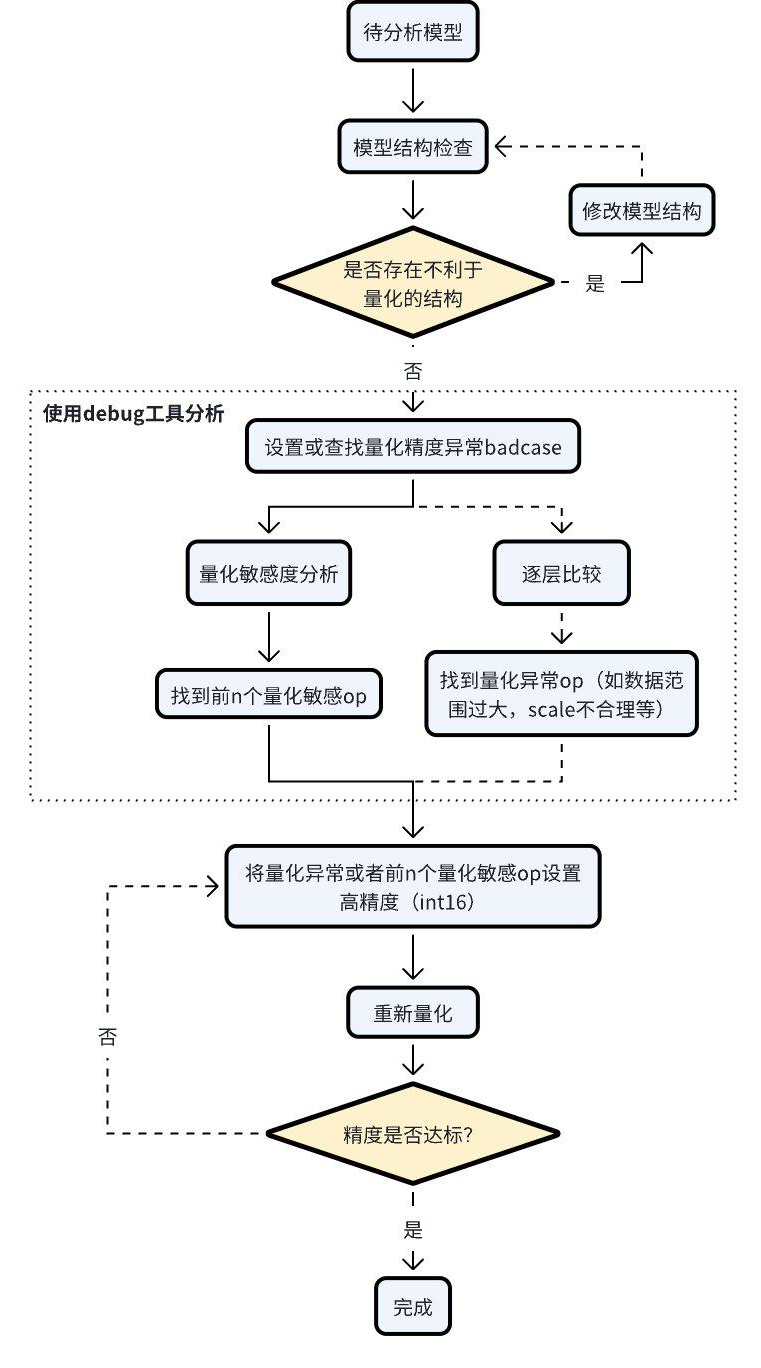
当碰到量化模型精度掉点问题时,我们推荐按照如下的流程使用精度调优工具。
检查模型中是否存在不利于量化的结构或者异常配置;
使用 QuantAnalysis 模块进行分析,具体步骤如下:
找到一个 bad case 作为模型的输入。bad case 是指基准模型和待分析模型输出相差最大的那个输入;
进行量化敏感度分析,目前的经验是 L1 敏感度排序前 n 个通常为量化敏感 op(不同的模型 n 的数值不一样,暂无自动确定的方法,需要手动尝试,如前 10 个,20 个…)。将量化敏感 op 设置高精度量化(如 int16 量化),重新进行量化流程;
或者逐层比较两个模型的输入输出等信息,检查是否存在数据范围过大或者 scale 不合理等量化异常的 op,如某些具有物理含义的 op 应设置固定 scale。
整体的流程图如下:
一个完整的例子如下。
from copy import deepcopy
import torch
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.quantization.qconfig import (
default_qat_8bit_fake_quant_qconfig,
)
from horizon_plugin_pytorch.quantization.quantize_fx import prepare_qat_fx
from horizon_plugin_pytorch.quantization import hbdk4 as hb4
from horizon_plugin_pytorch.utils.check_model import check_qat_model
from horizon_plugin_profiler import QuantAnalysis, ModelProfiler
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Conv2d(3, 3, 1)
self.relu = nn.ReLU()
self.quant = QuantStub()
self.dequant = DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.conv(x)
x = self.relu(x)
x = torch.nn.functional.interpolate(
x, scale_factor=1.3, mode="bilinear", align_corners=False
)
x = self.dequant(x)
return x
data = torch.rand((1, 3, 32, 32))
float_net = Net()
float_net(data)
set_march(March.XXX)
float_net.qconfig = default_qat_8bit_fake_quant_qconfig
qat_net = deepcopy(float_net)
qat_net = prepare_qat_fx(qat_net)
############################### 模型结构检查 ##############################
# 确认提示的异常层是否符合预期
check_qat_model(qat_net, data, save_results=True)
##########################################################################
qat_net(data)
quantized_net = deepcopy(qat_net)
quantized_net = convert_fx(quantized_net)
############################### quant analysis ############################
# 1. 初始化
qa = QuantAnalysis(
baseline_model=float_net,
analysis_model=qat_net,
analysis_model_type="fake_quant",
out_dir="./floatvsqat",
)
# 也支持对比 qat 和 quantized
# qa = QuantAnalysis(
# baseline_model=qat_net,
# analysis_model=quantized_net,
# analysis_model_type="quantized",
# out_dir="./qatvsquantized",
# )
# 2. 设置 badcase 输入。
qa.set_bad_case(data)
# 实际场景下推荐使用 auto_find_bad_case 在整个 dataloader 上搜索 bad case
# 也支持设置 num_steps 参数来控制搜索的范围
# qa.auto_find_bad_case(your_dataloader, num_steps=100)
# 3. 运行两个模型
qa.run()
# 4. 两个模型逐层比较。确认 abnormal_layer_advisor.txt 提示的异常层是否符合预期
# qa.compare_per_layer()
# 5. 计算敏感度节点。可以将 topk 排序的敏感度节点设置高精度来尝试提升量化模型精度
qa.sensitivity()
##########################################################################
7.4.6.2. API Reference¶
7.4.6.2.1. 模型结构检查¶
# from horizon_plugin_pytorch.utils.check_model import check_qat_model
def check_qat_model(
model: torch.nn.Module,
example_inputs: Any,
save_results: bool = False,
out_dir: Optional[str] = None,
):
检查 calibration/qat 模型中是否存在不利于量化的结构以及量化 qconfig 配置是否符合预期。
参数
model: 待检查模型
example_inputs: 模型输入
save_results: 是否将检查结果保存到 txt 文件。默认 False。
out_dir: 结果文件 ‘model_check_result.txt’ 的保存路径。默认空,保存到当前路径下。
输出
屏幕输出:检查出的异常层
model_check_result.txt:在 save_results = True 时生成。主要由5部分组成
未 fuse 的 pattern
每个 module 的调用次数。正常每个 op 仅调用 1 次,0 表示未被调用,超过 1 次则表示被共享了多次;
每个 op 输出的 qconfig 配置;
每个 op weight(如果有的话)的 qconfig 配置;
异常 qconfig 提示(如果有的话)。
Fusable modules are listed below:
name type
------ -----------------------------------------------------
conv <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'>
relu <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'>
Each module called times:
name called times
------- --------------
conv 1
relu 1
quant 1
dequant 1
Each layer out qconfig:
+---------------+-----------------------------------------------------------+---------------+---------------+----------------+-----------------------------+
| Module Name | Module Type | Input dtype | out dtype | ch_axis | observer |
|---------------+-----------------------------------------------------------+---------------+---------------+----------------+-----------------------------|
| quant | <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | torch.float32 | qint8 | -1 | MovingAverageMinMaxObserver |
| conv | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint8 | qint8 | -1 | MovingAverageMinMaxObserver |
| relu | <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'> | qint8 | qint8 | qconfig = None | |
| dequant | <class 'horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub'> | qint8 | torch.float32 | qconfig = None | |
+---------------+-----------------------------------------------------------+---------------+---------------+----------------+-----------------------------+
Weight qconfig:
+---------------+-------------------------------------------------------+----------------+-----------+---------------------------------------+
| Module Name | Module Type | weight dtype | ch_axis | observer |
|---------------+-------------------------------------------------------+----------------+-----------+---------------------------------------|
| conv | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint8 | 0 | MovingAveragePerChannelMinMaxObserver |
+---------------+-------------------------------------------------------+----------------+-----------+---------------------------------------+
注解
prepare_qat/prepare_qat_fx 流程中也已集成该接口,您可以设置 verbose=1 打开该检查功能。我们推荐您在进行 QAT 训练之前,使用此接口进行检查,并根据检查结果对模型做针对性的调整。
7.4.6.2.2. QuantAnalysis 类¶
QuantAnalysis 类可以自动寻找两个模型输出最大的 bad case,并以此作为输入,逐层比较两个模型的输出。此外,QuantAnalysis 类还提供计算敏感度功能,您可以尝试将敏感度排名 topk 的节点设置高精度,如 int16 量化,来提升量化模型精度。
class QuantAnalysis(object):
def __init__(
self,
baseline_model: torch.nn.Module,
analysis_model: torch.nn.Module,
analysis_model_type: str,
out_dir: Optional[str] = None,
)
参数
baseline_model: 基准模型(高精度)
analysis_model:待分析的模型(精度掉点)
analysis_model_type: 待分析的模型类型。支持两种输入
fake_quant:待分析的模型可以是精度掉点的 calibration/qat 模型,此时基准模型可以是原始浮点模型或者一个精度达标的 int8/int16 混合配置的 calibration/qat 模型
quantized:待分析的模型是精度掉点的定点问题,此时基准模型必须是一个精度达标的 calibration/qat 模型
out_dir:指定比较结果的输出目录
该类中各个 method 如下。
7.4.6.2.2.1. auto_find_bad_case¶
def auto_find_bad_case(
self,
data_generator: Iterable,
num_steps: Optional[int] = None,
metric: str = "L1",
device: Optional[Union[torch.device, str, int]] = None,
custom_metric_func: Optional[Callable] = None,
custom_metric_order_seq: Optional[str] = None,
):
自动寻找导致两个模型输出最差的 badcase。
参数
data_generator:dataloader 或者一个自定义的迭代器,每次迭代产生一个数据
num_steps:迭代 steps 次数
metric:指定何种 metric 作为 badcase 的 metric。默认使用 L1 最差的结果。支持 Cosine/MSE/L1/KL/SQNR/custom。若为 custom,表示使用自定义的 metric 计算方法,此时 custom_metric_func 和 custom_metric_order_seq 两个参数必须不为 None
device:指定模型运行 device
custom_metric_func:自定义模型输出比较函数
custom_metric_order_seq:自定义模型输出比较函数的排序规则,仅支持 “ascending”/”descending”,表示升序/降序
7.4.6.2.2.2. set_bad_case¶
def set_bad_case(self, data)
手动设置 badcase。
参数
data: badcase输入
7.4.6.2.2.3. load_bad_case¶
def load_bad_case(self, filename: Optional[str] = None)
从指定的文件中加载 badcase。
参数
filename:指定的文件路径
7.4.6.2.2.4. save_bad_case¶
def save_bad_case(self)
将 badcase 保存到 {self.out_dir}/badcase.pt 文件。
7.4.6.2.2.5. set_model_profiler_dir¶
def set_model_profiler_dir(
self,
baseline_model_profiler_path: str,
analysis_model_profiler_path: str,
):
手动指定 model_profiler 的输出保存路径。
某些情况下,在 QuantAnalysis 初始化之前,ModelProfiler 就已定义并运行,此时可以直接指定已有的 ModelProfiler 路径,跳过 QuantAnalysis 的 run 步骤,直接比较两个模型的输出。
参数
baseline_model_profiler_path:基准模型的 profiler 路径
analysis_model_profiler_path:待分析模型的 profiler 路径
7.4.6.2.2.6. run¶
def run(
self,
device: Optional[Union[torch.device, str, int]] = None,
)
运行两个模型并分别保存模型中每一层的结果。
参数
device:模型运行的 device
7.4.6.2.2.7. compare_per_layer¶
def compare_per_layer(self)
比较两个模型中每一层的结果。
输出
abnormal_layer_advisor.txt: 所有异常层,包括相似度低/数据范围过大/输入没有归一化/输出没有高精度 等情况
profiler.html: 可视化展示所有 metric 指标及模型中每一层的数据范围 diff
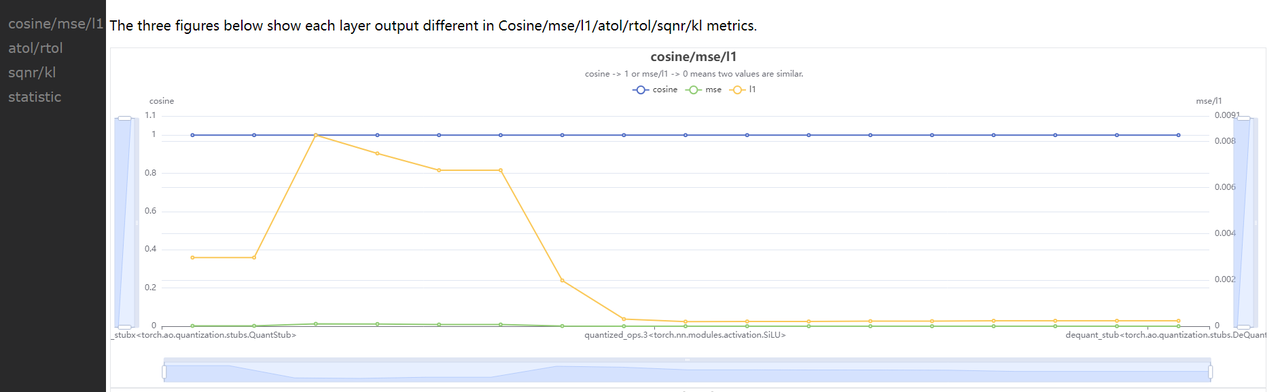
compare_per_layer_out.txt: 以表格的形式展示模型中每层 layer 的具体信息,包括各种指标、数据范围、量化 dtype 等。从左到右每一列分别表示:
Index:op index
mod_name:该 op 名字,若 op 为 module 类型,则显示该 module 在模型中的 prefix name,若为 function 类型,则不显示
base_op_type:基准模型中该 op 的 type,可能是 module 类型或者 function 名称
analy_op_type:待分析模型中该 op 的 type,可能是 module 类型或者 function 名称
Shape:该 op 输出的 shape
quant_dtype:该 op 输出的量化类型
Qscale:该 op 输出的量化 scale
Cosine:该 op 在两个模型中输出的余弦相似度
MSE:该 op 在两个模型中输出的 MSE 距离
L1:该 op 在两个模型中输出的 L1 距离
KL:该 op 在两个模型中输出的 KL 相似度
SQNR:该 op 在两个模型中输出的 SQNR 相似度
Atol:该 op 在两个模型中输出的绝对误差
Rtol:该 op 在两个模型中输出的相对误差
base_model_min:基准模型中该 op 输出的最小值
analy_model_min:待分析模型中该 op 输出的最小值
base_model_max:基准模型中该 op 输出的最大值
analy_model_max:待分析模型中该 op 输出的最大值
base_model_mean:基准模型中该 op 输出的平均值
analy_model_mean:待分析模型中该 op 输出的平均值
base_model_var:基准模型中该 op 输出的方差
analy_model_var:待分析模型中该 op 输出的方差
+----+------------+--------------------------------------------------------------------+--------------------------------------------------------------------+----------------------------+---------------+-----------+-----------+-----------+-----------+-----------+------------+-----------+-------------------------------------------------+------------------+-------------------+------------------+-------------------+-------------------+--------------------+------------------+-------------------+ | | mod_name | base_op_type | analy_op_type | shape | quant_dtype | qscale | Cosine | MSE | L1 | KL | SQNR | Atol | Rtol | base_model_min | analy_model_min | base_model_max | analy_model_max | base_model_mean | analy_model_mean | base_model_var | analy_model_var | |----+------------+--------------------------------------------------------------------+--------------------------------------------------------------------+----------------------------+---------------+-----------+-----------+-----------+-----------+-----------+------------+-----------+-------------------------------------------------+------------------+-------------------+------------------+-------------------+-------------------+--------------------+------------------+-------------------| | 0 | quant | torch.ao.quantization.stubs.QuantStub | horizon_plugin_pytorch.nn.qat.stubs.QuantStub | torch.Size([1, 3, 32, 32]) | qint8 | 0.0078354 | 0.9999924 | 0.0000052 | 0.0019757 | 0.0000006 | 48.1179886 | 0.0039178 | 1.0000000 | 0.0003164 | 0.0000000 | 0.9990171 | 0.9950994 | 0.5015678 | 0.5014852 | 0.0846284 | 0.0846521 | | 1 | conv | torch.nn.modules.conv.Conv2d | horizon_plugin_pytorch.nn.qat.conv2d.Conv2d | torch.Size([1, 3, 32, 32]) | qint8 | 0.0060428 | 0.9999037 | 0.0000085 | 0.0023614 | 0.0000012 | 37.1519432 | 0.0096008 | 48.2379990 | -0.7708085 | -0.7674332 | 0.4674263 | 0.4652941 | -0.0411330 | -0.0412943 | 0.0423415 | 0.0422743 | | 2 | relu | torch.nn.modules.activation.ReLU | horizon_plugin_pytorch.nn.qat.relu.ReLU | torch.Size([1, 3, 32, 32]) | qint8 | 0.0060428 | 0.9998640 | 0.0000037 | 0.0010231 | 0.0000004 | 35.5429153 | 0.0093980 | 48.2379990 | 0.0000000 | 0.0000000 | 0.4674263 | 0.4652941 | 0.0641222 | 0.0639115 | 0.0090316 | 0.0089839 | | 3 | | horizon_plugin_pytorch.nn.interpolate.autocasted_interpolate_outer | horizon_plugin_pytorch.nn.interpolate.autocasted_interpolate_outer | torch.Size([1, 3, 41, 41]) | qint8 | 0.0060428 | 0.9234583 | 0.0012933 | 0.0245362 | 0.0001882 | 8.1621437 | 0.1928777 | 340282346638528859811704183484516925440.0000000 | 0.0000000 | 0.0000000 | 0.3509629 | 0.3504813 | 0.0643483 | 0.0639483 | 0.0043305 | 0.0043366 | | 4 | dequant | torch.ao.quantization.stubs.DeQuantStub | horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub | torch.Size([1, 3, 41, 41]) | torch.float32 | | 0.9234583 | 0.0012933 | 0.0245362 | 0.0001882 | 8.1621437 | 0.1928777 | 340282346638528859811704183484516925440.0000000 | 0.0000000 | 0.0000000 | 0.3509629 | 0.3504813 | 0.0643483 | 0.0639483 | 0.0043305 | 0.0043366 | +----+------------+--------------------------------------------------------------------+--------------------------------------------------------------------+----------------------------+---------------+-----------+-----------+-----------+-----------+-----------+------------+-----------+-------------------------------------------------+------------------+-------------------+------------------+-------------------+-------------------+--------------------+------------------+-------------------+
compare_per_layer_out.csv: 以 csv 的格式展示每层的具体信息。内容和 compare_per_layer_out.txt 完全一致,csv 文件的存储格式方便您通过 excel 等软件打开分析。
7.4.6.2.2.8. sensitivity¶
def sensitivity(
self,
device: Optional[torch.device] = None,
metric: str = "L1",
reserve: bool = False
):
模型中各个节点的敏感度排序。适用于 float 转 calibration/qat 的精度掉点问题。
注意
sensitivity 函数不支持计算 hbir 模型的敏感度。
参数
device:指定模型运行的 device
metric:相似度排序的 metric,默认 L1,支持 Cosine/MSE/L1/KL/SQNR
reserve:是否反序打印敏感度节点,以支持将某些 int16 算子退回 int8 来提升上板性能
输出
sensitive_ops.txt。文件中按照量化敏感度从高到低的顺序排列 op。从左到右每一列分别表示:
op_name:op 名字,
sensitive_type:计算量化敏感的类型,包括三种
activation:仅量化该 op 输出的量化敏感度
weight:仅量化该 op 权重的量化敏感度
both:同时量化该 op 输出和权重的量化敏感度
op_type:op 类型
metric:计算敏感度的指标。按照敏感度从高到低的顺序排序。支持 Cosine/L1/MSE/KL/SQNR 五种指标。默认使用 L1。
L1:取值范围 [0, \(+\infty\)],数值越大则该 op 对量化越敏感(从大到小排序)
Cosine:取值范围 [0,1],越接近 0 则该 op 对量化越敏感(从小到大排序)
MSE:取值范围 [0, \(+\infty\)],数值越大则该 op 对量化越敏感(从大到小排序)
KL:取值范围 [0, \(+\infty\)],数值越大则该 op 对量化越敏感(从大到小排序)
SQNR:取值范围 [0, \(+\infty\)],数值越小则该 op 对量化越敏感(从小到大排序)
sensitive_ops.pt。使用 torch.save 保存的敏感度排序的列表,方便您后续加载使用。列表格式见返回值部分说明。
返回值
敏感度 List,List 中每个元素都是记录一个 op 敏感度信息的子 list。子 List 中从左到右每一项分别为 [op_name, sensitive_type, op_type, metric1, metric2, ...]。
整个 List 示例如下。
[
[op1, "activation", op1_type, L1],
[op2, "activation", op2_type, L1],
[op3, "activation", op3_type, L1],
[op1, "weight", op1_type, L1],
[op2, "both", op2_type, L1],
...
]
您可以将量化敏感度排名前 n 的 op 配置高精度(如int16)来尝试提升量化模型精度。
op_name sensitive_type op_type L1
--------- ---------------- ------------------------------------------------------- ---------
quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 0.0245567
conv activation <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> 0.0245275
conv both <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> 0.0245275
conv weight <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> 0.024501
7.4.6.2.2.9. clean¶
def clean(self)
清除中间结果。仅保留比较结果等文件。
7.4.6.2.3. ModelProfiler 类¶
统计模型 forward 过程中,每一层算子的输入输出等信息。
# from horizon_plugin_profiler import ModelProfiler
class ModelProfiler(object):
def __init__(
self,
model: torch.nn.Module,
out_dir: str,
)
参数
model: 需要统计的模型
out_dir: 相关文件保存的路径
注解
该类仅支持通过 with 语句的方式使用。
with ModelProfiler(net, "./profiler_dir") as p:
net(data)
p.get_info_manager.table()
p.get_info_manager.tensorboard()
该类中其中各个 method 如下。
7.4.6.2.3.1. get_info_manager¶
def get_info_manager(self)
获得管理每个 op 信息的结构体。
返回值
管理存储的每个 op 信息的结构体 OpRunningInfoManager。其中两个重要的接口如下。
7.4.6.2.3.1.1. table¶
class OpRunningInfoManager:
def table(
self,
out_dir: str = None,
prefixes: Tuple[str, ...] = None,
types: Tuple[Type, ...] = None,
with_stack: bool = False,
)
在一个表格中展示单个模型统计量。存储到 statistic.txt 文件中
参数
out_dir:statistic.txt 文件的存储路径,默认 None,存储到 self.out_dir
prefixes:需要统计的模型中 op 的 prefixes 。默认统计所有 op
types:需要统计的模型中 op 的 type。默认统计所有 op
with_stack: 是否显示每个 op 在代码中对应的位置
输出
statistic.txt 文件,从左到右每一列分别为:
Index: op index
Op Name:op type,module 类名或者 function 名
Mod Name:若是 module 类,则显示该 module 在模型中的 prefix name;若是 function 类型,则显示该 function 所在的 module prefix name。
Attr:input/output/weight/bias
Dtype:tensor 的数据类型
Scale:tensor 的 scale
Min:当前 tensor 的最小值
Max:当前 tensor 的最大值
Mean:当前 tensor 的平均值
Var:当前 tensor 中数值的方差
Shape:tensor shape
+---------+--------------------------------------------------------------------+------------+--------+---------------+-----------+------------+-----------+------------+-----------+----------------------------+
| Index | Op Name | Mod Name | Attr | Dtype | Scale | Min | Max | Mean | Var | Shape |
|---------+--------------------------------------------------------------------+------------+--------+---------------+-----------+------------+-----------+------------+-----------+----------------------------|
| 0 | horizon_plugin_pytorch.nn.qat.stubs.QuantStub | quant | input | torch.float32 | | 0.0003164 | 0.9990171 | 0.5015678 | 0.0846284 | torch.Size([1, 3, 32, 32]) |
| 0 | horizon_plugin_pytorch.nn.qat.stubs.QuantStub | quant | output | qint8 | 0.0078354 | 0.0000000 | 0.9950994 | 0.5014852 | 0.0846521 | torch.Size([1, 3, 32, 32]) |
| 1 | horizon_plugin_pytorch.nn.qat.conv2d.Conv2d | conv | input | qint8 | 0.0078354 | 0.0000000 | 0.9950994 | 0.5014852 | 0.0846521 | torch.Size([1, 3, 32, 32]) |
| 1 | horizon_plugin_pytorch.nn.qat.conv2d.Conv2d | conv | weight | torch.float32 | | -0.5315086 | 0.5750652 | 0.0269936 | 0.1615299 | torch.Size([3, 3, 1, 1]) |
| 1 | horizon_plugin_pytorch.nn.qat.conv2d.Conv2d | conv | bias | torch.float32 | | -0.4963555 | 0.4448483 | -0.0851902 | 0.2320642 | torch.Size([3]) |
| 1 | horizon_plugin_pytorch.nn.qat.conv2d.Conv2d | conv | output | qint8 | 0.0060428 | -0.7674332 | 0.4652941 | -0.0412943 | 0.0422743 | torch.Size([1, 3, 32, 32]) |
| 2 | horizon_plugin_pytorch.nn.qat.relu.ReLU | relu | input | qint8 | 0.0060428 | -0.7674332 | 0.4652941 | -0.0412943 | 0.0422743 | torch.Size([1, 3, 32, 32]) |
| 2 | horizon_plugin_pytorch.nn.qat.relu.ReLU | relu | output | qint8 | 0.0060428 | 0.0000000 | 0.4652941 | 0.0639115 | 0.0089839 | torch.Size([1, 3, 32, 32]) |
| 3 | horizon_plugin_pytorch.nn.interpolate.autocasted_interpolate_outer | | input | qint8 | 0.0060428 | 0.0000000 | 0.4652941 | 0.0639115 | 0.0089839 | torch.Size([1, 3, 32, 32]) |
| 3 | horizon_plugin_pytorch.nn.interpolate.autocasted_interpolate_outer | | output | qint8 | 0.0060428 | 0.0000000 | 0.3504813 | 0.0639483 | 0.0043366 | torch.Size([1, 3, 41, 41]) |
| 4 | horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub | dequant | input | qint8 | 0.0060428 | 0.0000000 | 0.3504813 | 0.0639483 | 0.0043366 | torch.Size([1, 3, 41, 41]) |
| 4 | horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub | dequant | output | torch.float32 | | 0.0000000 | 0.3504813 | 0.0639483 | 0.0043366 | torch.Size([1, 3, 41, 41]) |
+---------+--------------------------------------------------------------------+------------+--------+---------------+-----------+------------+-----------+------------+-----------+----------------------------+
7.4.6.2.3.1.2. tensorboard¶
class OpRunningInfoManager:
def tensorboard(
self,
out_dir: str = None,
prefixes: Tuple[str, ...] = None,
types: Tuple[Type, ...] = None,
force_per_channel: bool = False,
):
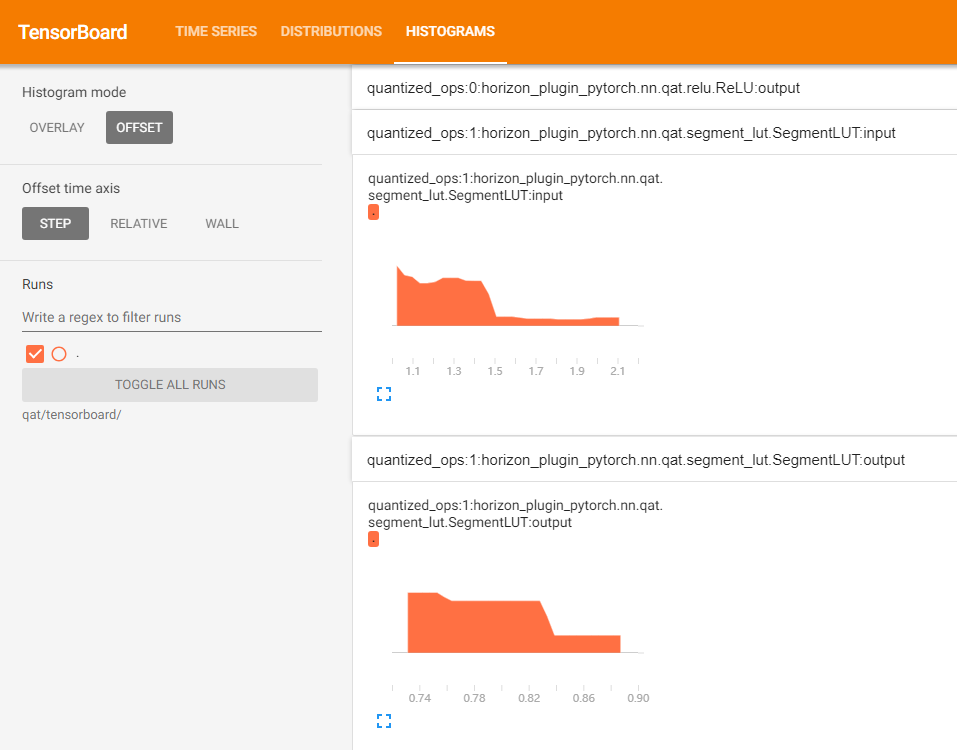
在 tensorboard 中显示每一层输入输出直方图。
参数
out_dir: tensorboard 相关文件保目录。默认保存到 self.out_dir/tensorboard 目录下
prefixes:需要统计的模型中 op 的 prefixes。默认统计所有
types:需要统计的模型中 op 的 type。默认统计所有
force_per_channel:是否以 per_channel 量化的方式展示直方图
输出
tensorboard 文件,打开后截图如下。