7.5.4. 算子融合¶
训练工具支持的算子融合可分为两大类:1. 吸收 BN;2. 融合 Add、ReLU(6)
7.5.4.1. 吸收 BN¶
吸收 BN 的目的是为了减少模型的计算量。因为 BN 是线性变换过程,因此,当 BN 和 Conv 一起出现的时候,可以把 BN 的参数吸收到 Conv 的参数中,从而在部署的模型中消除 BN 的计算。
吸收的计算过程如下:
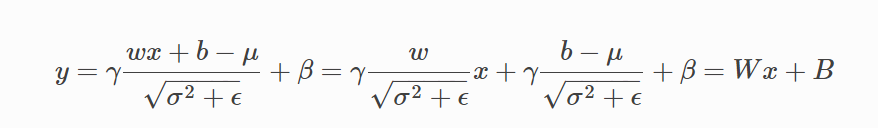
通过吸收 BN ,可以把 Conv2d + BN2d 简化为 Conv2d

7.5.4.2. 融合 Add、ReLU(6)¶
和 CUDA Kernel Fusion 中将 CUDA Kernel 融合以提高计算速度不同,训练工具支持的融合更加偏重量化层面
BPU 硬件针对常见的模型基本结构做了优化,在计算 Conv -> Add -> ReLU 这种算子组合时,可使算子间的数据传递保留高精度的状态,提高模型整体的数值精度。因此在对模型进行量化时,我们可以将 Conv -> Add -> ReLU 视为一个整体
由于训练工具对模型进行量化改造时以 torch.nn.Module 为单位,为了在量化时将 Conv -> Add -> ReLU 视为一个整体,需要将它们合并为一个 Module
算子融合除了可以使中间结果保留高精度状态之外,也可以省去将中间结果转化为低精度表示的过程,因此执行速度和不融合相比也会更快
(由于算子融合既可以提高模型精度,又可以提高模型速度,一般应该对所有可融合的部分进行融合)
7.5.4.3. 实现原理¶
得益于 FX 可以获取计算图的优势,训练工具可以自动化地对模型的计算图进行分析,根据预定义的 fusion pattern 对可融合部分进行匹配,并通过 submodule 替换实现融合的操作。下面举例进行说明
(吸收 BN 和融合 Add、ReLU(6) 可以通过相同的机制完成,因此在融合时不需要进行区分)
import torch
from torch import nn
from torch.quantization import DeQuantStub
from horizon_plugin_pytorch.quantization import QuantStub
from horizon_plugin_pytorch.quantization import fuse_fx
class ModelForFusion(torch.nn.Module):
def __init__(
self,
):
super(ModelForFusion, self).__init__()
self.quantx = QuantStub()
self.quanty = QuantStub()
self.conv = nn.Conv2d(3, 3, 3)
self.bn = nn.BatchNorm2d(3)
self.relu = nn.ReLU()
self.dequant = DeQuantStub()
def forward(self, x, y):
x = self.quantx(x)
y = self.quanty(y)
x = self.conv(x)
x = self.bn(x)
x = x + y
x = self.relu(x)
x = self.dequant(x)
return x
float_model = ModelForFusion()
fused_model = fuse_fx(float_model)
print(fused_model)
"""
ModelForFusion(
(quantx): QuantStub()
(quanty): QuantStub()
(conv): Identity()
(bn): Identity()
(relu): Identity()
(dequant): DeQuantStub()
(_generated_add_0): ConvAddReLU2d(
(conv): Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1))
(relu): ReLU()
)
)
def forward(self, x, y):
quantx = self.quantx(x); x = None
quanty = self.quanty(y); y = None
_generated_add_0 = self._generated_add_0
add_1 = self._generated_add_0(quantx, quanty); quantx = quanty = None
dequant = self.dequant(add_1); add_1 = None
return dequant
"""
可以看到,对模型执行算子融合操作后,BN 被吸收进 Conv 中,且 Conv、Add、ReLU 被融合进一个 Module 中(_generated_add_0)。原本的 submodule 被替换为 Identity,且不在 forward 代码中调用
(FX 自动地将模型中 x = x + y 的加号替换为了名为 _generated_add_0 的 Module 形式,以支持算子融合和量化的相关操作)
7.5.4.4. 可以融合的算子¶
目前支持的可融合的算子组合见以下函数定义
import operator
import torch
from torch import nn
from horizon_plugin_pytorch import nn as horizon_nn
def register_fusion_patterns():
convs = (
nn.Conv2d,
nn.ConvTranspose2d,
nn.Conv3d,
nn.Linear,
)
bns = (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d, nn.SyncBatchNorm)
adds = (
nn.quantized.FloatFunctional.add,
horizon_nn.quantized.FloatFunctional.add,
torch.add,
operator.add, # 即代码中使用的加号
)
relus = (nn.ReLU, nn.ReLU6, nn.functional.relu, nn.functional.relu6)
for conv in convs:
for bn in bns:
for add in adds:
for relu in relus:
# conv bn
register_fusion_pattern((bn, conv))(ConvBNAddReLUFusion)
# conv relu
register_fusion_pattern((relu, conv))(ConvBNAddReLUFusion)
# conv add
register_fusion_pattern((add, conv, MatchAllNode))(
ConvBNAddReLUFusion
) # conv 的输出作为 add 的第一个输入
register_fusion_pattern((add, MatchAllNode, conv))(
ConvBNAddedReLUFusion
) # conv 的输出作为 add 的第二个输入
# conv bn relu
register_fusion_pattern((relu, (bn, conv)))(
ConvBNAddReLUFusion
)
# conv bn add
register_fusion_pattern((add, (bn, conv), MatchAllNode))(
ConvBNAddReLUFusion
)
register_fusion_pattern((add, MatchAllNode, (bn, conv)))(
ConvBNAddedReLUFusion
)
# conv add relu
register_fusion_pattern((relu, (add, conv, MatchAllNode)))(
ConvBNAddReLUFusion
)
register_fusion_pattern((relu, (add, MatchAllNode, conv)))(
ConvBNAddedReLUFusion
)
# conv bn add relu
register_fusion_pattern(
(relu, (add, (bn, conv), MatchAllNode))
)(ConvBNAddReLUFusion)
register_fusion_pattern(
(relu, (add, MatchAllNode, (bn, conv)))
)(ConvBNAddedReLUFusion)