8.2. PTQ模型精度调优¶
8.2.1. 精度调优建议¶
基于前文的精度分析工作,如果确定模型的量化精度不符合预期,则主要可分为以下两种情况进行解决:
1.精度有较明显损失(损失大于4%)。
这种问题往往是由于yaml配置不当,校验数据集不均衡等导致的,可以根据我们接下来提供的建议逐一排查。
2.精度损失较小(1.5%~3%)。
排除1导致的精度问题后,如果仍然出现精度有小幅度损失,往往是由于模型自身的敏感性导致,可以使用我们提供的精度调优工具进行调优。
3.在尝试1和2后,如果精度仍无法满足预期,可以尝试使用我们提供的精度debug工具进行进一步尝试。
整体精度问题解决流程示意如下图:
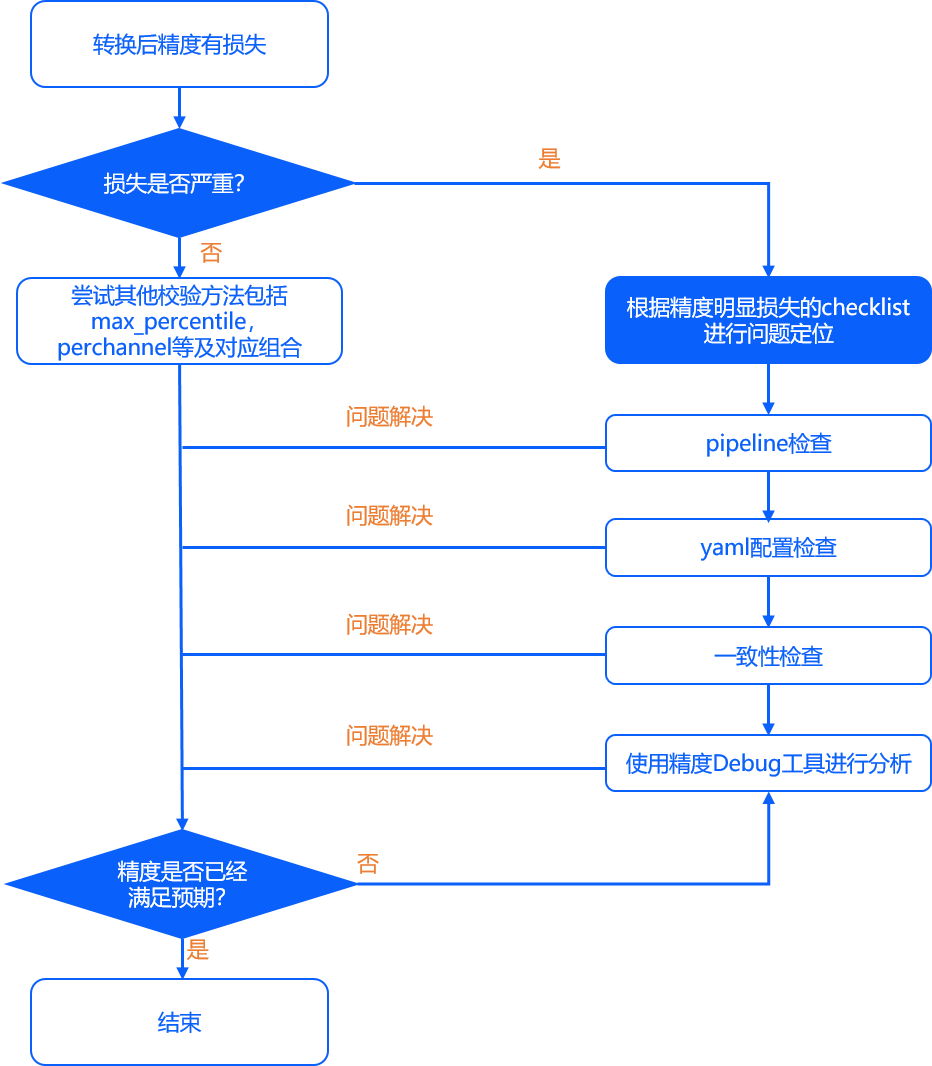
8.2.1.1. 精度有明显损失(4%以上)¶
通常情况下,明显的精度损失往往是由于各种配置不当引起的,我们建议您依次从pipeline、模型转换配置和一致性三个方面检查。
8.2.1.1.1. pipeline检查¶
pipeline是指您完成数据准备、模型推理、后处理、精度评测Metric的全过程。 在以往的实际问题跟进经验中,我们发现这些部分在原始浮点模型训练阶段中有变动,却没有及时更新到模型转换的精度验证过程来是比较常见的情况。
8.2.1.1.2. 模型转换yaml配置检查¶
根据PTQ精度评测及一致性校验推荐流程,如果定位到精度问题发生在original_float.onnx时,建议您重点检查yaml配置文件以及前后处理代码是否有误,其中,yaml配置文件常见误区包括:
input_type_rt和input_type_train该参数用来区分转后混合异构模型与原始浮点模型需要的数据格式,需要认真检查是否符合预期,尤其是BGR和RGB通道顺序是否正确。norm_type、mean_values、scale_values等参数是否配置正确。通过转换配置可以直接在模型中插入mean和scale操作节点, 需要确认是否对校验/测试图片进行了重复的mean和scale操作。重复预处理是错误的易发区。
8.2.1.1.3. 数据处理一致性检查¶
未正确指定read_mode: 示例包内每个示例文件夹下的
02_preprocess.sh脚本中可通过--read_mode参数来指定读图方式,支持opencv及skimage。此外,preprocess.py脚本中是通过imread_mode参数来设定读图方式的,也需要同步做修改。skimage.read和opencv.imread是两种常用图片读取方法,这两种方法在输出的范围和格式上都有所区别。 使用skimage的图片读取,得到的是RGB通道顺序,取值范围为0~1,数值类型为float;而使用opencv,得到的是BGR通道顺序,取值范围为0~255,数据类型为uint8。校准数据集的存储格式设置不正确:在校准数据准备阶段、给应用程序准备应用样本时,我们常使用numpy的tofile序列化数据。这种方式不会保存shape和类型信息, 在加载时都需要手动指定,需要您确保这些文件的序列化和反序列化过程的数据类型、数据尺寸和数据排布等信息都是一致的。
检查数据处理库及transformer实现方式:推荐您在地平线工具链使用过程中,依然使用原始浮点模型训练验证阶段依赖的数据处理库。 对于鲁棒性较差的模型,不同库实现的功能resize、crop等典型功能都可能引起扰动,进而影响模型精度。
而在使用同一数据处理库的情况下,部分预处理操作的实现方式可能也会有所区别,例如ResizeTransformer,采用的是opencv默认插值方式(linear), 若为其他插值方式可直接修改
transformer.py源码(路径为samples/ai_toolchain/horizon_model_convert_sample/01_common/python/data/transformer.py),确保与训练时预处理代码保持一致。校验图片集是否合理设置:校准图片集数量应该在百张左右,同时最好可以覆盖到数据分布的各种场合,例如在多任务或多分类时,校验图片集可以覆盖到各个预测分支或者各个类别。 同时避免偏离数据分布的异常图片(过曝光等)。
使用 *_original_float_model.onnx再验证一遍精度,正常情况下,这个模型的精度应该是与原始浮点模型精度保持小数点后三到五位对齐。 如果验证发现不满足这种对齐程度,则表明您的数据处理需要再仔细检查。
8.2.1.2. 较小精度损失(1.5%-3%)¶
一般情况下,为降低模型精度调优的难度,我们建议您在转换配置中使用的是自动参数搜索功能(将calibration_type配置为default)。
default为自动搜索功能,以第一张校准数据输出节点余弦相似度为依据,从max、max-percentile 0.99995和kl等校准方法中选取最优的方案,最终选取的校准方法可关注转换日志类似 Select kl method. 的提示,
搜索过程中,还会配合是否开启per_channel量化、非对称Asymmetric量化等方案。
如果开启per-channel还会打印:
Perchannel quantization is enabled。如果开启非对称asymmetric量化还会打印:
Asymmetric quantization is enabled。
如果发现自动搜索的精度结果仍与预期有一定的差距,较于原始浮点模型的精度损失在1.5%到3%范围左右。 可以分别尝试使用以下建议提高精度。
8.2.1.2.1. 调整校准方式¶
尝试在配置转换中手动指定
calibration_type,可以先选择mix,如果最终精度仍不符合预期,再尝试kl/max。在
calibration_type设定为max时,同时配置max_percentile为不同的分位数(取值范围是0.5-1之间), 我们推荐您优先尝试0.99999、0.99995、0.9999、0.9995、0.999,通过这几个配置观察模型精度的变化趋势,最终找到一个最佳的分位数。在上方尝试的基础上,选择余弦相似度最高的方案,在配置转换中尝试启用
per_channel。yaml中optimization参数还提供了asymmetric与bias_correction选项用于精度调试,实验发现这两个参数在部分场景中可以提升量化精度,可进行进一步尝试。
8.2.1.2.2. 调整校准数据集¶
尝试适当增加/减少校准数据集数据数量(通常情况下检测场景比分类场景所需校准数据量要少)。
观察模型输出的漏检情况,适当增加对应场景的校准数据。
不要使用纯黑、纯白等异常数据,尽量减少使用无目标的背景图作为校准数据,尽可能全面地覆盖典型任务场景,使用的校准数据集的分布需与训练集近似。
8.2.1.2.3. 将部分尾部算子回退到CPU高精度计算¶
一般我们仅会尝试将模型尾部输出层的1~2个算子回退至CPU,太多的CPU算子会影响模型最终性能, 判断依据可通过观察模型的余弦相似度(若将某些中间节点run_on_cpu,发现精度没有提升,这是正常现象,因为反复重量化可能还会带来更大的精度损失,因此通常只建议将尾部节点回退至cpu)。
指定算子运行在CPU上请通过yaml文件中的
node_info参数。
8.2.1.3. 精度debug工具¶
在尝试了上方提供的方法后,如果您的精度仍无法满足预期,可以尝试使用我们的精度debug工具。 在PTQ模型后量化过程中,造成精度损失的原因主要有两点:敏感节点量化问题、节点量化误差累积问题。 针对这两种情况,为了方便您定位问题,我们提供了精度debug工具用于协助您自主定位模型量化过程中产生的精度问题。 该工具能够协助您对校准模型进行节点粒度的量化误差分析,快速定位出现精度异常的节点。 工具的详细介绍及使用方法您可参考 精度debug工具 章节。
根据以往的实际生产经验,以上策略已经可以应对各种实际问题。 如果经过以上尝试仍然未能解决您的问题,欢迎在 地平线官方技术社区 发帖与我们取得联系, 我们将根据您的具体问题提供更具针对性的指导建议。
小技巧
您也可以通过配置部分op以int16计算来进行尝试精度调优:
在模型转换过程中,大部分op默认会以int8的数据计算,在一些场景下部分op使用int8计算会导致精度损失明显。
新版本模型转换工具链已经提供了指定特定op以int16 bit计算的能力,
详情可参考 模型参数组 中关于 node_info 参数配置的说明。
通过配置量化精度损失敏感op(可以以余弦相似度为参考)以int16 bit计算,一些场景下可以解决精度损失问题。
8.2.2. 使用QAT量化感知训练方案进一步提升模型精度¶
如果通过上述分析,并没有发现任何配置上的问题,但是精度仍不能满足要求,则可能是PTQ本身的限制。 这时候我们可以改用QAT的方式来对模型进行量化。
Horizon Plugin Pytorch参考了PyTorch官方的量化接口和思路,Plugin采用的是Quantization Aware Training(QAT)方案, 因此建议先阅读 PyTorch官方文档 中和QAT相关部分。
更详细的关于Horizon Plugin Pytorch的介绍,您可以参考 量化感知训练(QAT) 章节。