XStream高级特性¶
本文主要介绍了一下XStream Framework内部一些高级特性:多路输入,多路输出,Workflow线程调度,Workflow流向控制,Workflow嵌套,Workflow Profiling。
多路输入¶
XStreamSDK::Predict接口支持通过指定InputData中source_id_字段来标示输入源,进而支持多路视频输入,source_id_默认值为0,代表第一路。同时计算结果OutputData中source_id_字段与输入数据对应相同;
Workflow配置文件中通过字段”source_number”表示输入来源数目,默认为1。注意source_id_的范围需要在[0, source_number-1]内。
多路输入示例配置文件:
{
"source_number": 5,
"inputs": ["face_head_box"],
"outputs": ["face_head_box_filter"],
"workflow": [
{
"thread_count": 3,
"method_type": "BBoxFilter",
"unique_name": "BBoxFilter_1",
"inputs": [
"face_head_box"
],
"outputs": [
"face_head_box_filter"
],
"method_config_file": "null"
}
]
}
多路输出¶
XStream Frameowork中每个Node在计算过程中都会产生一些中间结果,这些中间结果可以作为其他Node计算节点的输入,或作为最后输出,或成为无效数据被清理。当这些中间输出作为最终workflow输出时,每一次计算这些中间结果都需要等到所有输出数据都ready以后再批量输出,如果Workflow中部分Node计算复杂度较大会导致前面部分输出被延迟。
多路输出功能,为缩短一些output数据的返回等待时间。通过该机制可以将输出数据分为多路输出,对于每一路数据达到Ready状态时,即可通过回调函数返回结果。
多路输出一般配合XStream SDK的异步调用方式使用,通过SetCallback接口设置回调函数,每路的输出通过该回调函数返回给调用者。若用户在配置多路输出workflow的同时采取同步调用的方式,需要注意需要配合使用SyncPredict2的同步调用接口获取输出结果。
多路输出的workflow配置文件可参考下面示例,与一般配置的差别仅在于需要在”outputs”字段将输出数据分组,并添加”output_type”字段表明该路输出的名称。
多路输出workflow配置文件:
{
"inputs": ["face_head_box"],
"outputs": [
{
"output_type": "out1",
"outputs":["face_head_box_filter"]
},
{
"output_type": "out2",
"outputs":["face_head_box_filter2"]
}
],
"workflow": [
{
"thread_count": 3,
"method_type": "BBoxFilter",
"unique_name": "BBoxFilter_1",
"inputs": [
"face_head_box"
],
"outputs": [
"face_head_box_filter"
],
"method_config_file": "null"
},
{
"thread_count": 3,
"method_type": "BBoxFilter",
"unique_name": "BBoxFilter_2",
"inputs": [
"face_head_box_filter"
],
"outputs": [
"face_head_box_filter2"
],
"method_config_file": "null"
}
]
}
Workflow线程调度¶
XStream内部通过多线程的方式来提高调度和执行并发度,其中涉及线程包括以下两大类:
两个框架调度线程:包括Workflow调度线程
sched_upper和Node调度线程sched_down。Node计算线程池:在Workflow构建中,我们可以配置每个Node的计算副本数,通过线程池来提高Node计算并发度,降低计算延迟。
对于这两类线程,除了在Workflow构建中设置Node计算副本数以外,XStream还支持设置线程调度策略,调整线程优先级以及对线程进行绑定。
1. 调度策略与优先级¶
支持设置线程调度策略包括:
SCHED_OTHER or SCHED_NORMAL: 默认调度优先级,不支持优先级设置,优先级恒为0。Ready的线程在等待队列等待时间越长,优先级越高;
SCHED_FIFO:一种实时调用策略,可设置线程优先级范围1~99,值越大优先级越高;当SCHED_FIFO的线程状态为runable时,会立即抢占SCHED_OTHER的线程;如果一个SCHED_FIFO线程被一个更高优先级的线程抢占,该线程会放在相同优先级线程的队首;当一个SCHED_FIFO的线程状态变成runnable时,该线程放在相同优先级线程的队尾;
SCHED_RR:一种实时调度策略,可设置线程优先级范围1~99,值越大优先级越高;SCHED_RR调度策略本身是SCHED_FIFO的简单增强版,区别在于对于相同优先级的线程,SCHED_RR对于相同优先级的线程也是采用时间片轮转的方式,一个线程做完自己的时间片之后就放在该优先级线程的队尾,反之SCHED_FIFO不会主动让出线程;
SCHED_BATCH:为批处理任务设计的优先级调度策略,SCHED_IDLE的线程优先级特别低;跟SCHED_OTHER调度策略一样,优先级恒为0,不能设置;
关于线程调度策略详细参考:http://man7.org/linux/man-pages/man7/sched.7.html
针对XStream内部两类线程,都支持设置它的调度策略和调度优先级,实例如下:
{
"inputs": ["face_head_box"],
"outputs": ["face_head_box_filter2"],
"optional":
{
"sched_upper":
{
"policy": "SCHED_FIFO",
"priority": 30
},
"sched_down":
{
"policy": "SCHED_FIFO",
"priority": 30
}
},
"workflow": [
{
"thread_list": [0],
"thread_priority":
{
"policy": "SCHED_FIFO",
"priority": 10
},
"method_type": "BBoxFilter",
"unique_name": "BBoxFilter_1",
"inputs": [
"face_head_box"
],
"outputs": [
"face_head_box_filter"
],
"method_config_file": "sched_fifo0.json"
},
{
"thread_list": [1, 2],
"thread_priority":
{
"policy": "SCHED_FIFO",
"priority": 20
},
"method_type": "BBoxFilter",
"unique_name": "BBoxFilter_2",
"inputs": [
"face_head_box_filter"
],
"outputs": [
"face_head_box_filter2"
],
"method_config_file": "sched_fifo1.json"
}
]
}
注意:关于优先级,建议upper和down两个调度线程的的优先级高于每个method node的线程优先级。同时Node中多个线程只能配置为相同的优先级,如果多个method node共享同一个线程,在拓扑靠后(workflow本身即是按拓扑有序排列的,所以就是workflow每个node的排序靠后的)的method node设置的优先级有效;
2. Node计算线程绑定¶
通过提高Node的计算副本数thread_count来增加计算并发度同时,本身也增加来任务计算线程数,进而因线程抢占而影响计算效率。
因此框架也支持指定了node执行线程index的数组,基于thread_list可以实现多个node之间共享执行线程。通过该方法既满足计算并发度,又避免因为小的计算任务导致线程膨胀。
实例参考上述thread_list设置方式。
Workflow流向控制¶
在Workflow正常运行过程中,可能会因为一些需求需要对单次计算选择临时跳过一些Node计算节点。例如, 通过外部传入人脸照片,提取特征时,创建底库时, 需要运行人脸检测,特征提取计算, 但不需要再进行人脸mot跟踪, mot method的计算节点就可以关闭。针对这个需求,XStream提供了几种方式:
Invalid模式: 将Node输出设置为无效状态,默认节点输出数据状态
state=4,跳过Node节点计算。UsePreDefine模式: 直接定义关闭节点的输出数据。试用于模拟, 测试等场景。
PassThrough模式: 直接将关闭节点的输入数据当做输出数据,前提是输入数据和输出相等。
BestEffortPassThrough模式: PassThrough模式升级版本,如果关闭节点的输入数据多于或等于输出数据,则按顺序将输入数据拷贝到输出数据;如果输入数据少于输出数据, 则多余的输出为Invalid的BaseData。
1. Invalid Mode¶
下面workflow输入数据是face_head_box, 最终输出数据是face_head_box_filter_3,face_head_box_filter_5。
{
"max_running_count": 10000,
"inputs": ["face_head_box"],
"outputs": ["face_head_box_filter_2", "face_head_box_filter_3"],
"workflow": [
{
"thread_count": 3,
"method_type": "BBoxFilter",
"unique_name": "BBoxFilter_1",
"inputs": [
"face_head_box"
],
"outputs": [
"face_head_box_filter_1"
],
"method_config_file": "null"
},
{
"thread_count": 3,
"method_type": "BBoxFilter",
"unique_name": "BBoxFilter_2",
"inputs": [
"face_head_box_filter_1"
],
"outputs": [
"face_head_box_filter_2"
],
"method_config_file": "null"
},
{
"thread_count": 3,
"method_type": "BBoxFilter",
"unique_name": "BBoxFilter_3",
"inputs": [
"face_head_box_filter_2"
],
"outputs": [
"face_head_box_filter_3"
],
"method_config_file": "null"
}
]
}
此时希望暂时停止BBoxFilter_3的运行,
InputDataPtr inputdata(new InputData());
BaseDataVector *data(new BaseDataVector);
HobotXStream::BBox *bbox1(new HobotXStream::BBox(hobot::vision::BBox(0, 0, 40, 40)));
bbox1->type_ = "BBox";
data->name_ = "face_head_box";
data->datas_.push_back(BaseDataPtr(bbox1));
inputdata->datas_.push_back(BaseDataPtr(data));
HobotXStream::InputParamPtr invalidFilter3(new HobotXStream::DisableParam("BBoxFilter_3", Mode::Invalid));
inputdata->params_.push_back(invalidFilter3);
out = flow->SyncPredict(inputdata);
callback.OnCallback(out);
对应的Workflow结构图如下所示:
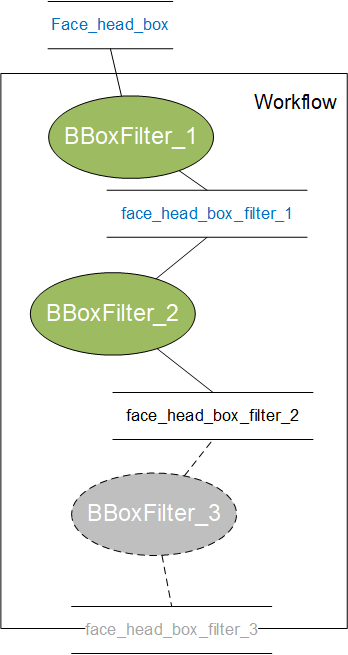
此时”BBoxFilter_3”节点输出数据被标记为INVALID,即data状态设置为state=4。
============Output Call Back============
—seq: 1
—output_type: __NODE_WHOLE_OUTPUT__
—error_code: 0
—error_detail_:
—datas_ size: 2
——output data face_head_box_filter_2 state:0
——data type:BaseDataVector name:face_head_box_filter_2
——output data face_head_box_filter_3 state:4
——data type:BaseData name:face_head_box_filter_3
============Output Call Back End============
注意:将一个Node节点设置为INVALID,需要保证该节点输出不被其他Node节点所依赖,否则会造成计算失败。
比如,在上面实例中,如果仅仅”BBoxFilter_2”,而”BBoxFilter_2”输出被”BBoxFilter_3”依赖,将会导致error_code:-2002 HOBOTXSTREAM_ERROR_OUTPUT_NOT_READY的计算错误。
2. Use Predefined Mode¶
Use Predefined模型与Invalid模型类似,它是通过人工指定相关Node的输出字段内容,而跳过Node节点计算。
InputDataPtr inputdata(new InputData());
BaseDataVector *data(new BaseDataVector);
HobotXStream::BBox *bbox1(new HobotXStream::BBox(
hobot::vision::BBox(0, 0, 60, 60)));
bbox1->type_ = "BBox";
data->name_ = "face_head_box";
data->datas_.push_back(BaseDataPtr(bbox1));
inputdata->datas_.push_back(BaseDataPtr(data)
HobotXStream::DisableParamPtr
pre_define(
new HobotXStream::DisableParam(
"BBoxFilter_1",
HobotXStream::DisableParam::Mode::UsePreDefine));
BaseDataVector *pre_data(new BaseDataVector);
HobotXStream::BBox *pre_bbox1(new HobotXStream::BBox(
hobot::vision::BBox(0, 0, 20, 20)));
pre_bbox1->type_ = "BBox";
pre_data->name_ = "face_head_box";
pre_data->datas_.push_back(BaseDataPtr(pre_bbox1));
pre_define->pre_datas_.emplace_back(BaseDataPtr(pre_data));
inputdata->params_.push_back(pre_define);
auto out = flow->SyncPredict(inputdata);
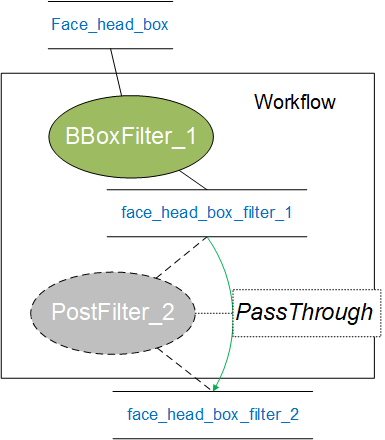
3. PassThrough Mode¶
PassThrough Mode模式是直接将输入数据写为输出数据,从而跳过节点计算。PassThrough模式要求Node节点的输入数据和输出数据个数(InputData.data_.size())是一致的。
对于该Workflow,我们尝试用PassThrough方式关闭PostBoxFilter_2节点。
InputDataPtr inputdata(new InputData());
BaseDataVector *data(new BaseDataVector);
HobotXStream::BBox *bbox1(new HobotXStream::BBox(
hobot::vision::BBox(0, 0, 60, 60)));
bbox1->type_ = "BBox";
data->name_ = "face_head_box";
data->datas_.push_back(BaseDataPtr(bbox1));
inputdata->datas_.push_back(BaseDataPtr(data)
HobotXStream::InputParamPtr
pass_through(new HobotXStream::DisableParam("PostBoxFilter_2", HobotXStream::DisableParam::Mode::PassThrough));
inputdata->params_.push_back(pass_through);
out = flow->AsyncPredict(inputdata);
此时实际运行时,Workflow结构如下:
4. Best Effort PassThrough Mode¶
PassThrough Mode模式将输入直接透传到输出,但是要求输入数据和输出数据字段数目一致。但是实际场景下,输入数据和输出数据并不匹配。
Best Effort PassThrough Mode模式支持在输入数据字段多于输出字段数目时,只透传前面的数据字段。如果输入数据字段少于输出字段数目时,则多余的输出字段写为Invalid。
BestEffortPassThrough是PassThrough的改进版本,多数情况下更推荐使用estEffortPassThrough模式。使用方式如下:
InputDataPtr inputdata(new InputData());
BaseDataVector *data(new BaseDataVector);
HobotXStream::BBox *bbox1(new HobotXStream::BBox(
hobot::vision::BBox(0, 0, 60, 60)));
bbox1->type_ = "BBox";
data->name_ = "face_head_box";
data->datas_.push_back(BaseDataPtr(bbox1));
inputdata->datas_.push_back(BaseDataPtr(data)
inputdata->params_.clear();
HobotXStream::InputParamPtr
b_effort_pass_through(
new HobotXStream::DisableParam(
"BBoxFilter_1",
HobotXStream::DisableParam::Mode::BestEffortPassThrough));
inputdata->params_.push_back(b_effort_pass_through);
out = flow->AsyncPredict(inputdata);
Workflow嵌套¶
Workflow骨干架构中,Workflow内容可以是Node类型节点,也可以是一个子Workflow。通过子Workflow可以实现一个更高粒度的复用,提供workflow复用价值。
{
"name": "xxx", // workflow名称,需唯一化
"type": "workflow", // 表示Workflow对象
"inputs": [], // 输入slots名称
"outputs": [], // 输出slots名称
"workflow": [ // Workflow内容,包括Node或Workflow对象(子workflow)
]
}
子Workflow的引入,是参考了编程语言中函数的设计思想:
子workflow是个配置文件,它组装了多个功能Method,该文件可以被多个父Workflow引用。
子Workflow被引用过程中,也支持参数化,类似传统编程语言中函数和函数参数。
下面一个使用子workflow配置实例:
{
"name":"main",
"type":"workflow",
"inputs":[
"image"
],
"outputs":[
"face_box",
"vehicle_box"
],
"workflow":[
{
"type":"node",
"unique_name":"fasterrcnndet",
"method_type":"FasterRCNNMethod",
"inputs":[
"image"
],
"outputs":[
"face_box"
]
},
{
"type":"template_ref",
"template_name":"cnn.tpl",
"parameters":{
"name":"vehicle_cnn",
"pre_method":"VehiclePreProcess",
"post_method":"VehiclePostProcess",
"input":"image",
"output":"vehicle_box"
}
}
]
}
父workflow命名为main,它包含一个Node类型的Method算子和一个template_ref类型的子workflow。
子workflow为
cnn.tpl,它是一个与父workflow文件同目录的文件。parameters为一个对象,其中每一个字段都将为参数值传递给子workflow。
cnn.tpl子workflow配置定义如下:
{
"type":"template",
"template_name":"cnn.tpl",
"parameters":[
"name",
"pre_method",
"post_method",
"inputs",
"outputs"
],
"template":{
"name":"${name}",
"type":"workflow",
"inputs":[
"${inputs}"
],
"outputs":[
"${outputs}"
],
"workflow":[
{
"type":"node",
"method_type":"${pre_method}",
"unique_name":"pre",
"inputs":[
"inputs"
],
"outputs":[
"pre_out0",
"pre_out1"
]
},
{
"type":"node",
"method_type":"CNNMethod",
"unique_name":"cnn",
"inputs":[
"pre_out0",
"pre_out1"
],
"outputs":[
"cnn_out0"
]
},
{
"type":"node",
"method_type":"${post_method}",
"unique_name":"post",
"inputs":[
"cnn_out0"
],
"outputs":[
"outputs"
]
}
]
}
}
type=template代表当前文件一个模版配置,可以被当着子workflow进行交换template_name为子workflow文件名称。parameters定义了一下参数名称,在后面复用该Workflow时,需要提供这些参数的值。template定义一个子workflow内容,在该workflow定义内部,可以使用${parameter}进行参数引用,其他与标准workflow使用方式
Profiling¶
XStream Frameworkf提供了性能统计功能,统计数据包括FPS和平均&最大&最小耗时。
对外接口提供如下。
SetConfig("profiler", "on");
第一个参数”profiler”固定;第二个参数”on”表示打开性能统计功能,其他表示关闭性能统计功能。
默认使用std::cout向控制台打印输出性能统计结果,也可以调用如下接口设置Log文件,文件名称自行设置。
SetConfig("profiler_file", "./profiler.txt");
第一个参数”profiler_file”固定;第二个参数”profiler.txt”表示性能统计数据的输出文件。
框架内对耗时的统计结果输出受到处理帧数的限制,默认处理帧数大于10时才输出对应的耗时数据;同时对帧数的统计结果受到处理时长的限制,默认处理时长超过3s才输出对应的帧数统计数据。若用户希望得到不同粒度的统计结果,可以通过接口对处理最小帧数和最小时长进行修改。
SetConfig("profiler_frame_interval", "8"); // 修改最小帧数为8帧
SetConfig("profiler_time_interval", "100"); // 修改最短时长为100ms