9.5.2. hrt_model_exec工具介绍¶
9.5.2.1. 工具简介¶
hrt_model_exec 是一个模型执行工具,可直接在开发板上评测模型的推理性能、获取模型信息。
一方面可以让用户拿到模型时实际了解模型真实性能;
另一方面也可以帮助用户了解模型可以做到的速度极限,对于应用调优的目标极限具有指导意义。
hrt_model_exec 工具分别提供了模型推理 infer、模型性能分析 perf 和查看模型信息 model_info 三类功能,如下表:
编号 |
子命令 |
说明 |
|---|---|---|
1 |
|
获取模型信息,如:模型的输入输出信息等。 |
2 |
|
执行模型推理,获取模型推理结果。 |
3 |
|
执行模型性能分析,获取性能分析结果。 |
工具可以通过 -v 或者 --version 命令,查看工具的 dnn 预测库版本号。
hrt_model_exec -v
hrt_model_exec --version
9.5.2.2. 参数描述¶
编号 |
参数 |
类型 |
说明 |
|---|---|---|---|
1 |
|
string |
模型文件路径,多个路径可通过逗号分隔。 |
2 |
|
string |
指定模型中某个模型的名称。 |
3 |
|
int |
指定运行核。0:任意核,1:core0,2:core1;默认为 |
4 |
|
string |
模型输入信息。
图片输入后缀必须为 |
5 |
|
bool |
使能resizer模型推理。若模型存在resizer输入源的输入,需设置为 |
6 |
|
string |
指定推理resizer模型时所需的roi区域,多个roi之间通过英文分号间隔。 如:–roi=”2,4,123,125;6,8,111,113” |
7 |
|
int |
执行模型运行帧数。 |
8 |
|
string |
dump模型每一层输入和输出。
|
9 |
|
bool |
使能dump模型输入和输出,默认为 |
10 |
|
int |
控制txt格式输出float型数据的小数点位数,默认为 |
11 |
|
bool |
对原始输出进行后处理后保存。在 |
12 |
|
string |
dump模型输入和输出的格式。 |
13 |
|
int |
控制txt格式输入输出的换行规则。 |
14 |
|
bool |
使能分类后处理,默认为 |
15 |
|
int |
执行模型运行时间。 |
16 |
|
int |
线程数(并行度),数值可以表示最多有多少个任务在并行处理。 测试延时,数值需要设置为1,没有资源抢占发生,延时测试更准确。 测试吞吐,建议设置>2 (BPU核心个数),调整线程数使BPU利用率尽量高,吞吐测试更准确。 |
17 |
|
string |
统计工具日志产生路径,运行产生profiler.log和profiler.csv,分析op耗时和调度耗时。
一般设置 |
18 |
|
string |
工具dump输出文件路径,enable_dump或dump_intermediate都会产生输出文件,指定路径后 文件将输出在指定路径下,若路径不存在,则工具会自动创建。 |
设置profile_path参数且工具正常运行后会产生profiler.log和profiler.csv文件,文件中包括如下参数:
perf_result:记录perf结果。
参数
说明
FPS
每秒处理的帧数。
average_latency
平均一帧运行所花费的时间。
running_condition:运行环境信息。
参数
说明
core_id
程序运行设置的bpu核。
frame_count
程序运行的总帧数。
model_name
评测模型的名字。
run_time
程序运行时间。
thread_num
程序运行的线程数。
model_latency:模型节点耗时统计。
参数
说明
Preprocess
模型前处理耗时时间:DNN内部对输入数据的处理,包括padding、layout转换等。
BPU_NodeName
BPU节点的耗时信息。注:NodeName为具体的节点名称。
CPUNodeType_NodeName
CPU节点的耗时信息。注:CPUNodeType为具体的节点类型,如Dequantize,NodeName为具体的节点名称。
processor_latency:模型处理器耗时统计。
参数
说明
BPU_inference_time_cost
每帧推理BPU处理器耗时。
CPU_inference_time_cost
每帧推理CPU处理器耗时。
task_latency:模型任务耗时统计。
参数
说明
TaskPendingTime
任务排队耗时。注:提交的任务可能存在排队情况,不会立即运行。
TaskRunningTime
任务实际运行耗时,耗时时间包括DNN框架耗时。
9.5.2.3. 使用说明¶
工具提供三类功能:模型信息获取、单帧推理功能、多帧性能评测。
运行 hrt_model_exec 、 hrt_model_exec -h 或 hrt_model_exec --help 获取工具使用详情。如下图中所示:
9.5.2.3.1. model_info¶
9.5.2.3.1.1. 概述¶
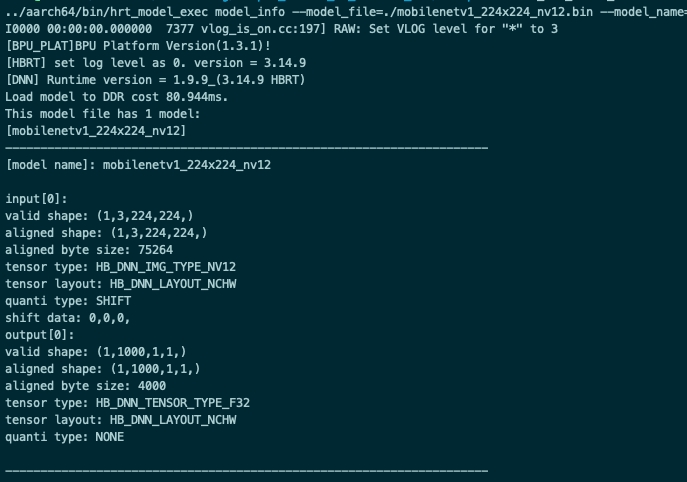
该参数用于获取模型信息,模型支持范围:qat模型,ptq模型。该参数与 model_file 一起使用,用于获取模型的详细信息,
信息包括模型输入输出信息 hbDNNTensorProperties。
不指定 model_name 输出模型中所有模型信息,指定 model_name 则只输出对应模型的信息。
9.5.2.3.1.2. 示例¶
1.单模型
hrt_model_exec model_info --model_file=xxx.bin
2.多模型(输出所有模型信息)
hrt_model_exec model_info --model_file=xxx.bin,xxx.bin
3.多模型–pack模型(输出指定模型信息)
hrt_model_exec model_info --model_file=xxx.bin --model_name=xx
9.5.2.3.2. infer¶
9.5.2.3.2.1. 概述¶
该参数用于模型推理,用户自定义输入图片,推理一帧。
该参数需要与 input_file 一起使用,指定输入图片路径,工具根据模型信息resize图片,整理模型输入信息。
程序单线程运行单帧数据,输出模型运行的时间。
9.5.2.3.2.2. 示例¶
1.单模型
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg
2.多模型
hrt_model_exec infer --model_file=xxx.bin,xxx.bin --model_name=xx --input_file=xxx.jpg

3.resizer模型
模型有三个输入,输入源顺序分别为[ddr, resizer, resizer]。
推理两帧数据,假设第一帧输入为[xx0.bin,xx1.jpg,xx2.jpg],roi为[2,4,123,125;6,8,111,113],第二帧输入为[xx3.bin,xx4.jpg,xx5.jpg],roi为[27,46,143,195;16,28,131,183],则推理命令如下:
hrt_model_exec infer --roi_infer=true --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
注解
多帧输入之间用英文逗号隔离,roi之间使用分号隔离。
9.5.2.3.2.3. 可选参数¶
参数 |
说明 |
|---|---|
|
指定模型推理的核id。 |
|
使能resizer模型推理。 |
|
|
|
设置 |
|
dump模型每一层输入数据和输出数据,默认值 |
|
dump模型输入和输出数据,默认为 |
|
控制txt格式输出float型数据的小数点位数,默认为 |
|
控制txt格式输出float类型数据,若输出为定点数据将其进行反量化处理,目前只支持四维模型。 |
|
dump模型输出文件的类型,可选参数为 |
|
dump模型txt格式输出的换行规则;若输出维度为n,则参数范围为[0, n], 默认为 |
|
使能分类后处理,目前只支持ptq分类模型,默认 |
|
指定dump输出路径,默认当前路径。 |
9.5.2.3.3. perf¶
9.5.2.3.3.1. 概述¶
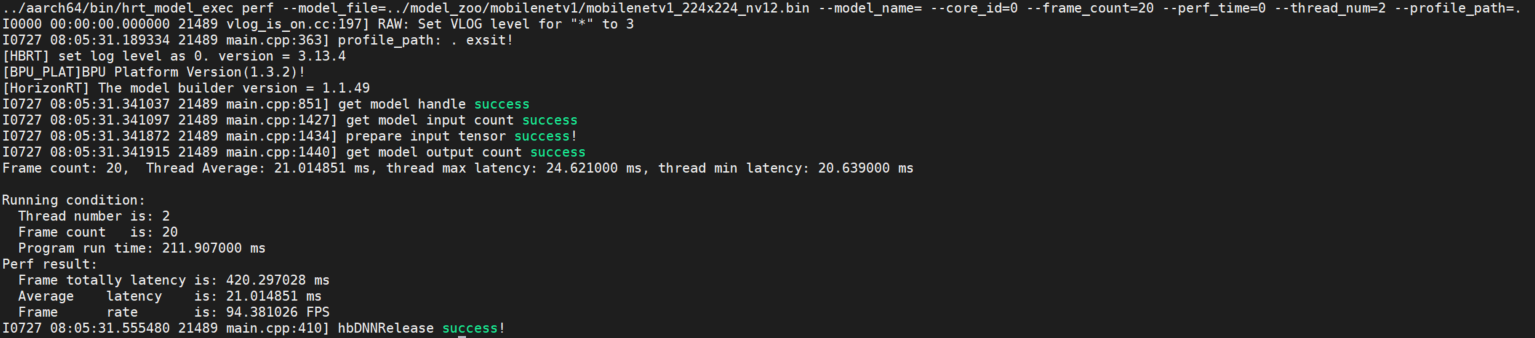
该参数用于测试模型性能。 该模式下,用户无需输入数据,程序根据模型信息自动构造输入tensor,tensor数据为随机数。 程序默认单线程运行200帧数据,当指定perf_time参数时,frame_count参数失效,程序会执行指定时间后退出。 输出模型运行的latency、以及帧率信息。程序每200帧打印一次性能信息: latency的最大、最小、平均值,不足200帧程序运行结束打印一次。
程序最后输出running相关数据, 包括:程序线程数、帧数、模型推理总时间,模型推理平均latency,帧率信息。
9.5.2.3.3.2. 示例¶
1.单模型
hrt_model_exec perf --model_file=xxx.bin
2.多模型
hrt_model_exec perf --model_file=xxx.bin,xxx.bin --model_name=xx
3.resizer模型
模型有三个输入,输入源顺序分别为[ddr, resizer, resizer]。
一次推理两帧数据,假设第一帧输入为[xx0.bin,xx1.jpg,xx2.jpg],roi为[2,4,123,125;6,8,111,113],第二帧输入为[xx3.bin,xx4.jpg,xx5.jpg],roi为[27,46,143,195;16,28,131,183],则perf命令如下:
hrt_model_exec perf --roi_infer=true --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
注解
多帧输入之间用英文逗号隔离,roi之间使用分号隔离。
9.5.2.3.3.3. 可选参数¶
参数 |
说明 |
|---|---|
|
指定模型推理的核id。 |
|
模型输入信息,多个可通过逗号分隔。 |
|
使能resizer模型推理;若模型输入包含resizer源,设置为 |
|
|
|
设置 |
|
设置 |
|
设置程序运行线程数,范围[1, 8], 默认为 |
|
统计工具日志产生路径,运行产生profiler.log和profiler.csv,分析op耗时和调度耗时。 |
9.5.2.3.4. 多线程Latency数据说明¶
多线程的目的是为了充分利用BPU资源,多线程共同处理 frame_count 帧数据或执行perf_time时间,直至数据处理完成/执行时间结束程序结束。
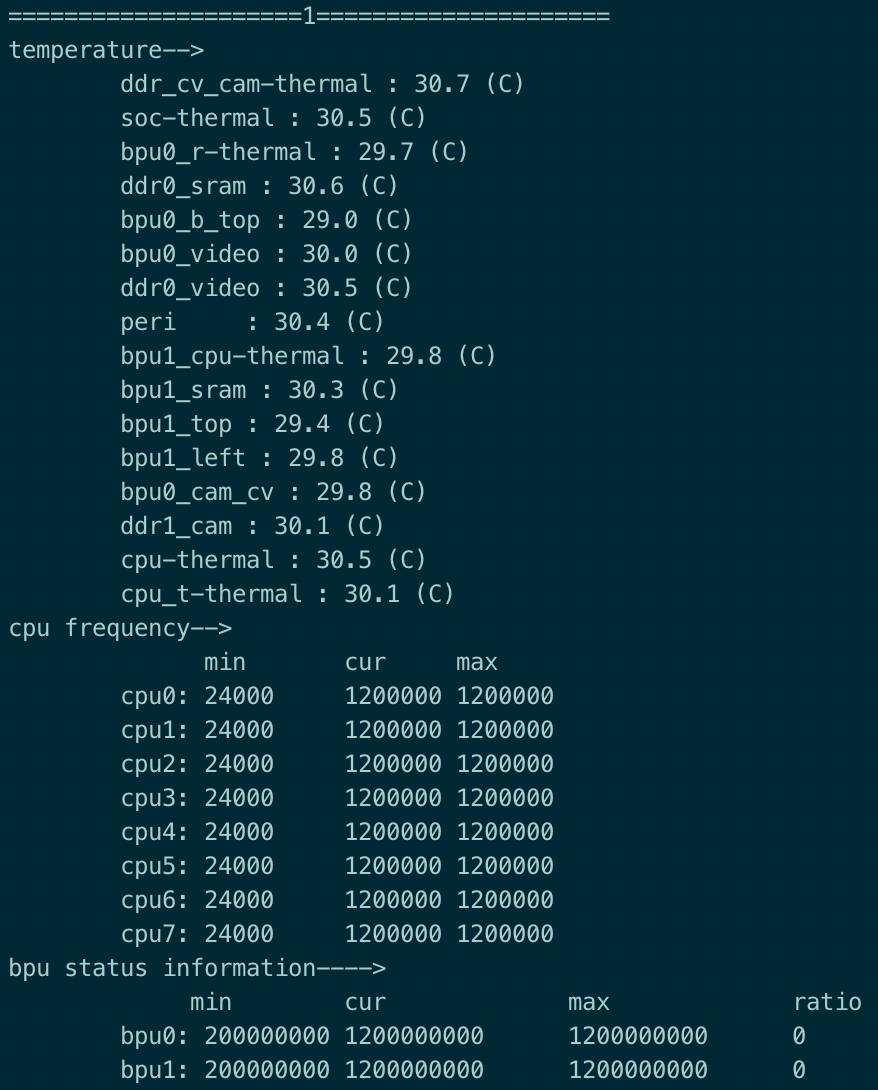
在多线程 perf 过程中可以执行以下命令,实时获取BPU资源占用率情况。
hrut_somstatus -n 10000 -d 1
输出见以下截图:
注解
在 perf 模式下,单线程的latency时间表示模型的实测上板性能,
而多线程的latency数据表示的是每个线程的模型单帧处理时间,
相对于单线程的时间要长,但是多线程的总体处理时间减少,其帧率是提升的。
9.5.2.3.5. 多输入模型说明¶
工具 infer 推理功能支持多输入模型的推理,支持图片输入、二进制文件输入以及文本文件输入,输入数据用逗号隔开。
模型的输入信息可以通过 model_info 进行查看。
示例:
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg,input.txt
9.5.2.4. 常见问题¶
9.5.2.4.1. Latency、FPS数据是如何统计的?¶
Latency是指单流程推理模型所耗费的平均时间,重在表示在资源充足的情况下推理一帧的平均耗时,体现在上板运行是单核单线程统计;统计方法伪代码如下:
// Load model and prepare input and output tensor
...
// Loop run inference and get latency
{
int32_t const loop_num{1000};
start = std::chrono::steady_clock::now();
for(int32_t i = 0; i < loop_num; i++){
hbDNNInferCtrlParam infer_ctrl_param;
HB_DNN_INITIALIZE_INFER_CTRL_PARAM(&infer_ctrl_param);
hbDNNInfer(&task_handle,
&output,
input_tensors.data(),
dnn_handle,
&infer_ctrl_param);
// wait task done
hbDNNWaitTaskDone(task_handle, 0);
// release task handle
hbDNNReleaseTask(task_handle);
task_handle = nullptr;
}
end = std::chrono::steady_clock::now();
latency = (end - start) / loop_num;
}
// release tensor and model
...
FPS是指多流程同时进行模型推理平均一秒推理的帧数,重在表示充分使用资源情况下模型的吞吐,体现在上板运行为单核多线程;统计方法是同时起多个线程进行模型推理,计算平均1s推理的总帧数。
9.5.2.4.2. 通过Latency推算FPS与工具测出的FPS为什么不一致?¶
Latency与FPS的统计情景不同,Latency为单流程(单核单线程)推理,FPS为多流程(单核多线程)推理,因此推算不一致;若统计FPS时将流程(线程)数量设置为 1 ,则通过Latency推算FPS和测出的一致。
9.5.2.4.3. 工具如何评测自定义算子模型?¶
参考basic_sample中custom_identity示例开发自定义算子,将自定义算子编译成动态库,在工具使用之前指定该动态库路径即可。 例如动态库路径为:/userdata/plugins/libplugin.so,工具运行含该自定义算子的模型,仅需指定该动态库所在路径即可。
export HB_DNN_PLUGIN_PATH=/userdata/plugins/