4.1.2.11. 精度debug工具¶
模型转换工具链会基于您提供的校准样本对模型进行校准量化并保障模型高效的部署在地平线计算平台上。 而在模型转换的过程中,难免会因为浮点到定点的量化过程而引入精度损失,通常情况下造成精度损失的主要原因可能有以下几点:
1.模型中的一部分节点对量化比较敏感会引入较大误差,即敏感节点量化问题。
2.模型中各个节点的误差累积导致模型整体出现较大的校准误差,主要包含:权重量化导致的误差累积、激活量化导致的误差累积以及全量量化导致的误差累积。
针对该情况,地平线提供了精度debug工具用以协助您自主定位模型量化过程中产生的精度问题。 该工具能够协助您对校准模型进行节点粒度的量化误差分析,最终帮助您快速定位出现精度异常的节点。
精度debug工具提供多种分析功能供您使用,例如:
获取节点量化敏感度。
获取模型累积误差曲线。
获取指定节点的数据分布。
获取指定节点输入数据通道间数据分布箱线图等。
4.1.2.11.1. 快速上手¶
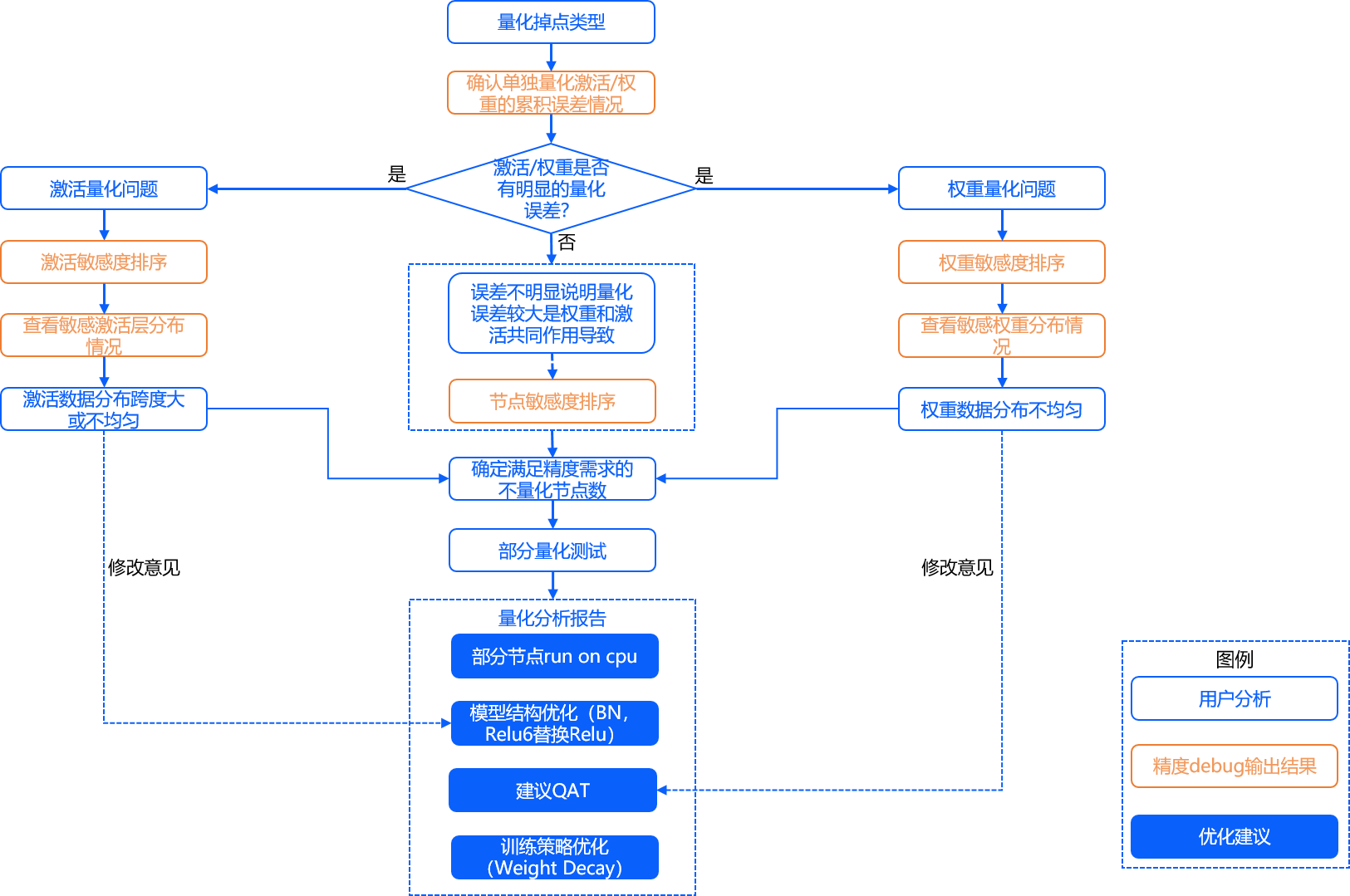
使用精度debug工具主要有以下几个步骤:
1.在yaml中的 模型参数组(model_parameters) 配置参数 debug_mode="dump_calibration_data" ,保存校准数据。
2.导入debug模块,加载校准模型和数据。
3.通过精度debug工具提供的API,对精度损失明显的模型进行分析。
整体流程如下图所示:
4.1.2.11.1.1. 校准模型与数据的保存¶
首先需要在yaml文件中配置 debug_mode="dump_calibration_data" ,以开启精度debug功能,
并保存校准数据(calibration_data),对应的校准模型(calibrated_model.onnx)为常态化保存。其中:
校准数据(calibration_data):在校准阶段,模型通过对这些数据进行前向推理来获取每个被量化节点的量化参数,包括:缩放因子(scale)和阈值(threshold)。
校准模型(calibrated_model.onnx):将在校准阶段计算得到的每个被量化节点的量化参数保存在校准节点中,从而得到校准模型。
注解
此处保存的校准数据与02_preprocess.sh生成的校准数据的区别?
02_preprocess.sh 得到的校准数据是bgr颜色空间的数据,在工具链内部会将数据从bgr转换到yuv444/gray等模型实际输入的格式。
而此处保存的校准数据则是经过颜色空间转换以及预处理之后保存的.npy格式的数据,该数据可以通过np.load()直接送入模型进行推理。
注解
校准模型(calibrated_model.onnx)解读
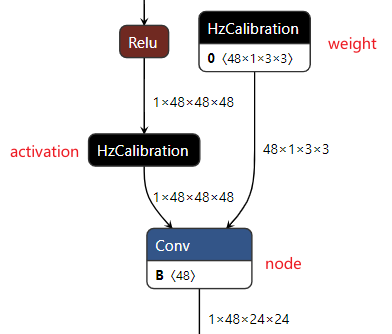
校准模型是模型转换工具链将浮点模型经过结构优化后,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中得到的中间产物。 校准模型的主要特点是模型中包含校准节点,校准节点的节点类型为HzCalibration。 这些校准节点主要分为两类: 激活(activation)校准节点 和 权重(weight)校准节点 。
激活校准节点 的输入是当前节点的上一个节点的输出,并基于当前激活校准节点中保存的量化参数(scales和thresholds)对输入数据进行量化及反量化后输出。
权重校准节点 的输入为模型的原始浮点权重,基于当前权重校准节点中保存的量化参数(scales和thresholds)对输入的原始浮点权重进行量化及反量化后输出。
除却上述的校准节点,校准模型中的其他节点,精度debug工具将其称为 普通节点(node) 。 普通节点 的类型包括:Conv、Mul、Add等。
calibration_data的文件夹结构如下:
|--calibration_data :校准数据
|----input.1 :文件夹名为模型的输入节点并保存对应的输入数据
|--------0.npy
|--------1.npy
|-------- ...
|----input.2 :对于多输入模型将保存多个文件夹
|--------0.npy
|--------1.npy
|-------- ...
4.1.2.11.1.2. 精度debug模块导入与API使用¶
接下来需要在代码中导入debug模块,并通过 get_sensitivity_of_nodes 接口获取节点量化敏感度(默认使用模型输出的余弦相似度)。
get_sensitivity_of_nodes 的详细参数说明可见 get_sensitivity_of_nodes 章节。
# 导入debug模块
import horizon_nn.debug as dbg
# 导入log日志模块
import logging
# 若verbose=True时,需要先设置log level为INFO
logging.getLogger().setLevel(logging.INFO)
# 获取节点量化敏感度
node_message = dbg.get_sensitivity_of_nodes(
model_or_file='./calibrated_model.onnx',
metrics=['cosine-similarity', 'mse'],
calibrated_data='./calibration_data/',
output_node=None,
node_type='node',
data_num=None,
verbose=True,
interested_nodes=None)
4.1.2.11.1.3. 分析结果展示¶
下方为 verbose=True 时的打印结果:
==========================node==========================
Node cosine-similarity mse
--------------------------------------------------------
Conv_3 0.999009567957658 0.027825591154396534
MaxPool_2 0.9993462241612948 0.017706592209064044
Conv_6 0.9998359175828787 0.004541242333988731
MaxPool_5 0.9998616805443397 0.0038416787014844325
Conv_0 0.9999297948984 0.0019312848587735342
Gemm_19 0.9999609772975628 0.0010773885699633795
Conv_8 0.9999629625907311 0.0010301886404004807
Gemm_15 0.9999847687207736 0.00041888411550854263
MaxPool_12 0.9999853235024673 0.0004039733791544747
Conv_10 0.999985763659844 0.0004040437432614943
Gemm_17 0.9999913985912616 0.0002379088904350423
除此之外,该API会以字典(Dict)的形式将节点量化敏感度信息返回给您以供后续使用分析。
Out:
{'Conv_3': {'cosine-similarity': '0.999009567957658', 'mse': '0.027825591154396534'},
'MaxPool_2': {'cosine-similarity': '0.9993462241612948', 'mse': '0.017706592209064044'},
'Conv_6': {'cosine-similarity': '0.9998359175828787', 'mse': '0.004541242333988731'},
'MaxPool_5': {'cosine-similarity': '0.9998616805443397', 'mse': '0.0038416787014844325'},
'Conv_0': {'cosine-similarity': '0.9999297948984', 'mse': '0.0019312848587735342'},
'Gemm_19': {'cosine-similarity': '0.9999609772975628', 'mse': '0.0010773885699633795'},
'Conv_8': {'cosine-similarity': '0.9999629625907311', 'mse': '0.0010301886404004807'},
'Gemm_15': {'cosine-similarity': '0.9999847687207736', 'mse': '0.00041888411550854263'},
'MaxPool_12': {'cosine-similarity': '0.9999853235024673', 'mse': '0.0004039733791544747'},
'Conv_10': {'cosine-similarity': '0.999985763659844', 'mse': '0.0004040437432614943'},
'Gemm_17': {'cosine-similarity': '0.9999913985912616', 'mse': '0.0002379088904350423'}}
更多功能详见 API说明文档 章节。
4.1.2.11.2. API说明文档¶
4.1.2.11.2.1. get_sensitivity_of_nodes¶
功能:获取节点量化敏感度。
API参数组:
编 号 |
参数名称 |
参数配置说明 |
可选/ 必选 |
|---|---|---|---|
1 |
|
参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 |
必选 |
2 |
|
参数作用:节点量化敏感度的度量方式。 取值范围: 默认配置: 参数说明:指定节点量化敏感度的计算方式,该参数可以为列表(List), 即以多种方式计算量化敏感度, 但是输出结果仅以列表中第一位的计算方式进行排序, 排名越靠前说明量化该节点引入的误差越大。 |
可选 |
3 |
|
参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析所需要的校准数据。 |
必选 |
4 |
|
参数作用:指定输出节点。 取值范围:校准模型中的具有对应校准节点的普通节点。 默认配置:None。 参数说明:此参数支持您指定中间节点作为输出并计算节点量化敏感度。 若保持默认参数None,则精度debug工具会获取模型的最终输出 并在此基础上计算节点的量化敏感度。 |
可选 |
5 |
|
参数作用:节点类型。 取值范围: 默认配置: 参数说明:需要计算量化敏感度的节点类型,包括:node(普通节点)、 weight(权重校准节点)、activation(激活校准节点)。 |
可选 |
6 |
|
参数作用:计算量化敏感度需要的数据数量。 取值范围:大于0,小于等于calibration_data中数据的总数。 默认配置:None 参数说明:设置计算节点量化敏感度时所需要的数据数量。 默认为None,此时默认使用calibration_data中的所有数据进行计算。 最小设置为1,最大为 calibration_data中的数据数量。 |
可选 |
7 |
|
参数作用:选择是否将信息打印在终端上。 取值范围: 默认配置: 参数说明:若为True,则将量化敏感度信息打印在终端上。 若metrics包含多种度量方式,则按照第一位进行排序。 |
可选 |
8 |
|
参数作用:设置感兴趣节点。 取值范围:校准模型中的所有节点。 默认配置:None。 参数说明:若指定则只获取该节点的量化敏感度,其余节点不获取。 同时,若该参数被指定,将忽视node_type指定的节点类型, 也就是说该参数的优先级要高于node_type。 若保持默认参数None,则计算模型中所有可被量化节点的量化敏感度。 |
可选 |
# 导入debug模块
import horizon_nn.debug as dbg
# 导入log日志模块
import logging
# 若verbose=True时,需要先设置log level为INFO
logging.getLogger().setLevel(logging.INFO)
# 获取节点量化敏感度
node_message = dbg.get_sensitivity_of_nodes(
model_or_file='./calibrated_model.onnx',
metrics=['cosine-similarity', 'mse'],
calibrated_data='./calibration_data/',
output_node=None,
node_type='node',
data_num=None,
verbose=True,
interested_nodes=None)
API分析结果展示:
描述:首先您通过node_type设置需要计算敏感度的节点类型,然后工具获取校准模型中所有符合node_type的节点,并获取这些节点的量化敏感度。 当verbose设置为True时,工具会将节点量化敏感度进行排序后打印在终端,排序越靠前,说明该节点量化引入的量化误差越大。
verbose=True时,打印结果如下:
==========================node==========================
Node cosine-similarity mse
--------------------------------------------------------
Conv_3 0.999009567957658 0.027825591154396534
MaxPool_2 0.9993462241612948 0.017706592209064044
Conv_6 0.9998359175828787 0.004541242333988731
MaxPool_5 0.9998616805443397 0.0038416787014844325
Conv_0 0.9999297948984 0.0019312848587735342
Gemm_19 0.9999609772975628 0.0010773885699633795
Conv_8 0.9999629625907311 0.0010301886404004807
Gemm_15 0.9999847687207736 0.00041888411550854263
MaxPool_12 0.9999853235024673 0.0004039733791544747
Conv_10 0.999985763659844 0.0004040437432614943
Gemm_17 0.9999913985912616 0.0002379088904350423
函数返回值:
函数返回值为以字典格式(Key为节点名称,Value为节点的量化敏感度信息)保存的量化敏感度,格式如下:
Out:
{'Conv_3': {'cosine-similarity': '0.999009567957658', 'mse': '0.027825591154396534'},
'MaxPool_2': {'cosine-similarity': '0.9993462241612948', 'mse': '0.017706592209064044'},
'Conv_6': {'cosine-similarity': '0.9998359175828787', 'mse': '0.004541242333988731'},
'MaxPool_5': {'cosine-similarity': '0.9998616805443397', 'mse': '0.0038416787014844325'},
'Conv_0': {'cosine-similarity': '0.9999297948984', 'mse': '0.0019312848587735342'},
'Gemm_19': {'cosine-similarity': '0.9999609772975628', 'mse': '0.0010773885699633795'},
'Conv_8': {'cosine-similarity': '0.9999629625907311', 'mse': '0.0010301886404004807'},
'Gemm_15': {'cosine-similarity': '0.9999847687207736', 'mse': '0.00041888411550854263'},
'MaxPool_12': {'cosine-similarity': '0.9999853235024673', 'mse': '0.0004039733791544747'},
'Conv_10': {'cosine-similarity': '0.999985763659844', 'mse': '0.0004040437432614943'},
'Gemm_17': {'cosine-similarity': '0.9999913985912616', 'mse': '0.0002379088904350423'}} ...}
4.1.2.11.2.2. plot_acc_error¶
功能:只量化浮点模型中的某一个节点,并依次计算该模型与浮点模型中节点输出的误差,获得累积误差曲线。
API参数组:
编 号 |
参数名称 |
参数配置说明 |
可选/ 必选 |
|---|---|---|---|
1 |
|
参数作用:保存路径。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析结果的保存路径。 |
必选 |
2 |
|
参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准数据。 |
必选 |
3 |
|
参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 |
必选 |
4 |
|
参数作用:只量化模型中指定的节点,查看误差累积曲线。 取值范围:校准模型中的所有节点。 默认配置:None。 参数说明:可选参数。指定模型中需要量化的节点,同时保证其余节点均不量化。 通过判断该参数是否为嵌套列表进而决定是单节点量化还是部分量化。 例如:
注:quantize_node和non_quantize_node不可同时为None,必须指定其一。 |
可选 |
5 |
|
参数作用:指定累积误差的类型。 取值范围:校准模型中的所有节点。 默认配置:None。 参数说明:可选参数。指定模型中不量化的节点,同时保证其余节点全都量化。 通过判断该参数是否为嵌套列表进而决定是单节点不量化还是部分量化。 例如:
注:quantize_node和non_quantize_node不可同时为None,必须指定其一。 |
可选 |
6 |
|
参数作用:误差度量方式。 取值范围: 默认配置: 参数说明:设置计算模型误差的计算方式。 |
可选 |
7 |
|
参数作用:指定累积误差曲线的输出模式。 取值范围: 默认配置: 参数说明:默认为False。若为True,那么获取累积误差的平均值作为结果。 |
可选 |
# 导入debug模块
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir: str,
calibrated_data: str or CalibrationDataSet,
model_or_file: ModelProto or str,
quantize_node: List or str,
non_quantize_node: List or str,
metric: str = 'cosine-similarity',
average_mode: bool = False)
API分析结果展示
1.指定节点量化累积误差测试
指定单节点量化
配置方式:quantize_node=[‘Conv_2’, ‘Conv_90’],quantize_node为单列表。
# 导入debug模块
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
quantize_node=['Conv_2', 'Conv_90'],
metric='cosine-similarity',
average_mode=False)
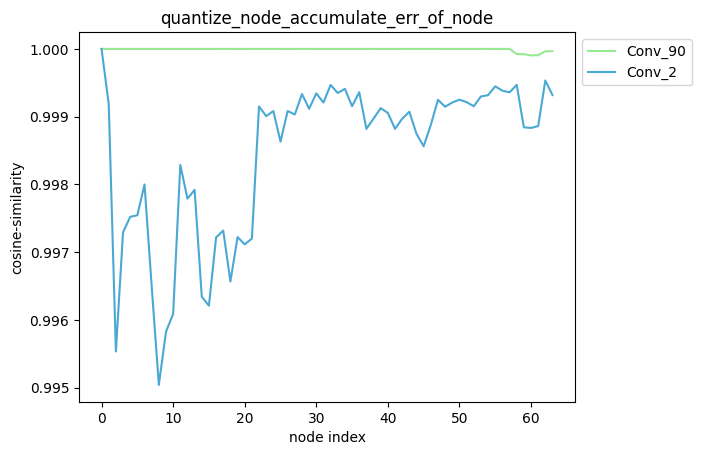
描述:当quantize_node为单列表时,针对您设置的quantize_node, 分别单独量化quantize_node中的节点并保持模型中其他节点不量化,得到对应的模型后, 对该模型中每个节点的输出计算其与浮点模型中对应节点输出的之间的误差,并得到对应的累积误差曲线。
average_mode = False时:
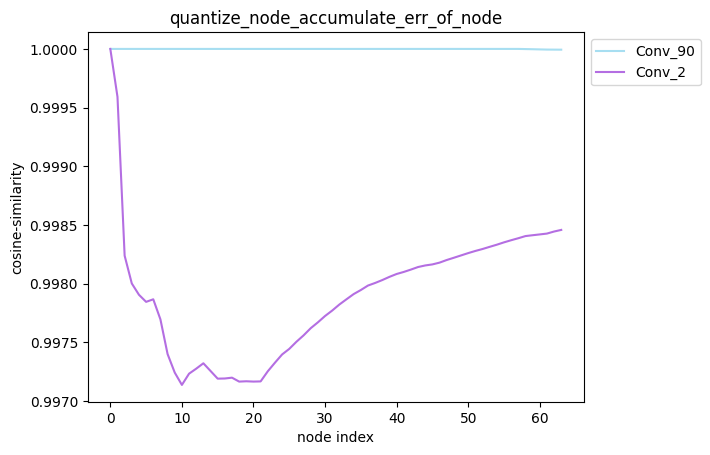
average_mode = True时:
注解
average_mode
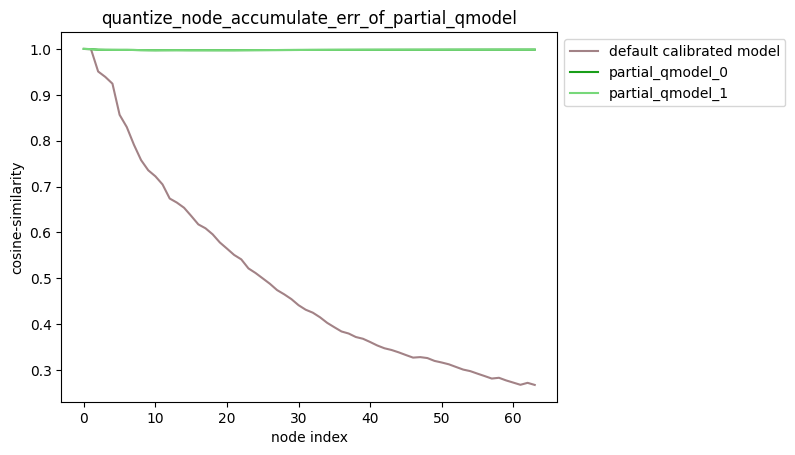
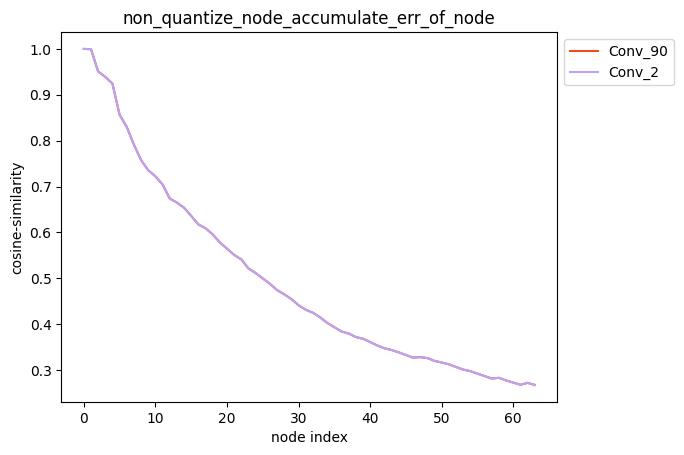
average_mode默认为False。对于一些模型,此时无法通过累积误差曲线判断哪种量化策略更加有效, 因此需要将average_mode设置为True,此时会对前n个节点的累积误差求均值作为第n个节点的累积误差。
具体计算方式如下,例如:
average_mode=False时,accumulate_error=[1.0, 0.9, 0.9, 0.8]。
而将average_mode=True后,accumulate_error=[1.0, 0.95, 0.933, 0.9]。
指定多个节点量化
配置方式:quantize_node=[[‘Conv_2’], [‘Conv_2’, ‘Conv_90’]],quantize_node为嵌套列表
# 导入debug模块
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
quantize_node=[['Conv_2'], ['Conv_2', 'Conv_90']],
metric='cosine-similarity',
average_mode=False)
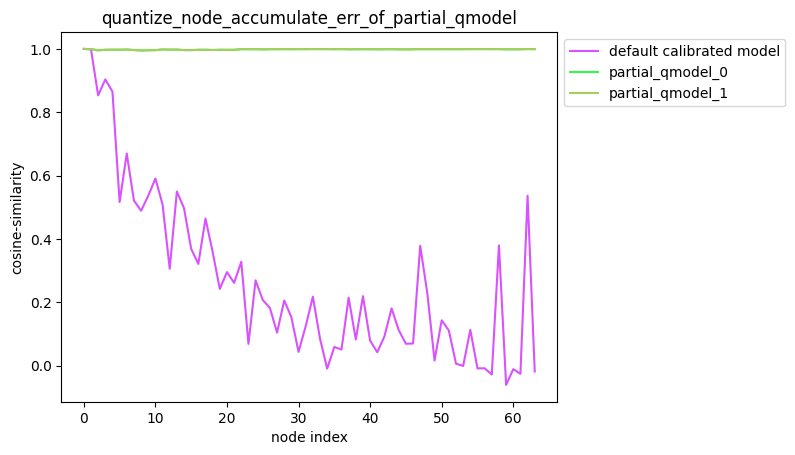
描述:当quantize_node为嵌套列表时,针对您设置的quantize_node,分别量化quantize_node中的 每个单列表指定的节点并保持模型中其他节点不量化,得到对应的模型后,对该模型中每个节点的输出计算 其与浮点模型中对应节点输出的之间的误差,并得到对应的累积误差曲线。
partial_qmodel_0:只量化Conv_2节点,其余节点不量化;
partial_qmodel_1:只量化Conv_2和Conv_90节点,其余节点不量化。
average_mode=False时:
average_mode=True时:
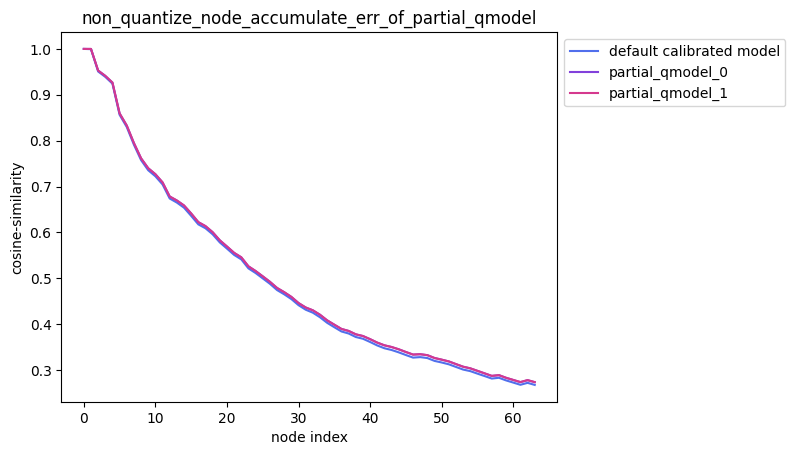
2.解除模型部分节点量化后累积误差测试
指定单节点不量化
配置方式:non_quantize_node=[‘Conv_2’, ‘Conv_90’],non_quantize_node为单列表。
# 导入debug模块
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
non_quantize_node=['Conv_2', 'Conv_90'],
metric='cosine-similarity',
average_mode=True)
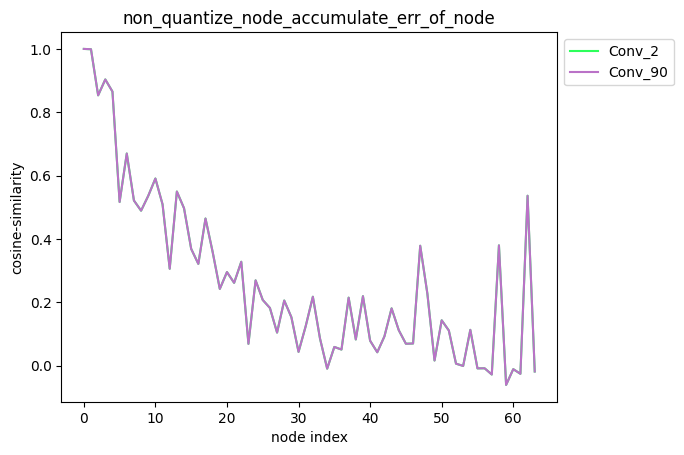
描述:当non_quantize_node为单列表时,针对您设置的non_quantize_node, 分别解除non_quantize_node中各个节点的量化同时保持其他节点全部量化,得到对应的模型后, 对该模型中每个节点的输出计算其与浮点模型中对应节点输出的之间的误差,并得到对应的累积误差曲线。
average_mode = False时:
average_mode = True时:
指定多个节点不量化
配置方式:non_quantize_node=[[‘Conv_2’], [‘Conv_2’, ‘Conv_90’]],non_quantize_node为嵌套列表。
# 导入debug模块
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
non_quantize_node=[['Conv_2'], ['Conv_2', 'Conv_90']],
metric='cosine-similarity',
average_mode=False)
描述:当non_quantize_node为嵌套列表时,针对您设置的non_quantize_node, 分别不量化non_quantize_node中的每个单列表指定的节点并保持模型中其他节点均量化, 得到对应的模型后,对该模型中每个节点的输出计算其与浮点模型中对应节点输出的之间的误差, 并得到对应的累积误差曲线。
partial_qmodel_0:不量化Conv_2节点,其余节点量化;
partial_qmodel_1:不量化Conv_2和Conv_90节点,其余节点量化。
average_mode = False时:
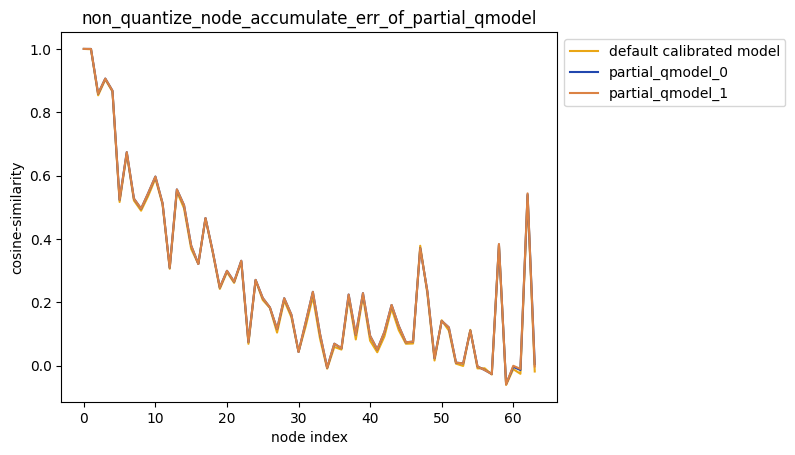
average_mode = True时:
测试技巧:
测试部分量化精度时,您可能会按照量化敏感度排序进行多组量化策略的精度对比,此时可以参考以下用法:
# 导入debug模块
import horizon_nn.debug as dbg
# 首先使用量化敏感度排序函数获取模型中节点的量化敏感度排序
node_message = dbg.get_sensitivity_of_nodes(
model_or_file='./calibrated_model.onnx',
metrics='cosine-similarity',
calibrated_data='./calibration_data/',
output_node=None,
node_type='node',
verbose=False,
interested_nodes=None)
# node_message为字典类型,其key值为节点名称
nodes = list(node_message.keys())
# 通过nodes来指定不量化节点,可以方便使用
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
non_quantize_node=[nodes[:1], nodes[:2]],
metric='cosine-similarity',
average_mode=True)
3.激活权重分别量化
配置方式:quantize_node=[‘weight’,’activation’]。
import horizon_nn.debug as dbg
dbg.plot_acc_error(
save_dir='./',
calibrated_data='./calibration_data/',
model_or_file='./calibrated_model.onnx',
quantize_node=['weight', 'activation'],
metric='cosine-similarity',
average_mode=False)
描述:quantize_node也可直接指定’weight’或者’activation’。当:
quantize_node = [‘weight’]:只量化权重,不量化激活。
quantize_node = [‘activation’]:只量化激活,不量化权重。
quantize_node = [‘weight’, ‘activation’]:权重和激活分别量化。
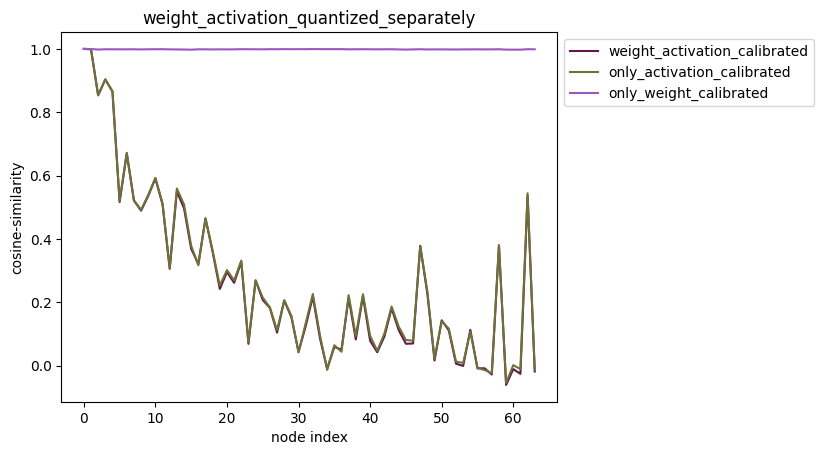
4.1.2.11.2.3. plot_distribution¶
功能:选取节点,分别获取该节点在浮点模型和校准模型中的输出,得到输出数据分布。另外,将两个输出结果做差,获取两个输出之间的误差分布。
API参数组:
编 号 |
参数名称 |
参数配置说明 |
可选/ 必选 |
|---|---|---|---|
1 |
|
参数作用:保存路径。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析结果的保存路径。 |
必选 |
2 |
|
参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 |
必选 |
3 |
|
参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析所需要的校准数据。 |
必选 |
4 |
|
参数作用:指定需要分析的节点。 取值范围:校准模型中的所有节点。 默认配置:无。 参数说明:必选,指定需要分析的节点。若nodes_list中的节点类型为:
注:nodes_list为 list 类型,可指定一系列节点,并且上述三种类型节点 可同时指定。 |
必选 |
# 导入debug模块
import horizon_nn.debug as dbg
dbg.plot_distribution(
save_dir: str,
model_or_file: ModelProto or str,
calibrated_data: str or CalibrationDataSet,
nodes_list: List[str] or str)
API分析结果展示:
# 导入debug模块
import horizon_nn.debug as dbg
dbg.plot_distribution(
save_dir='./',
model_or_file='./calibrated_model.onnx',
calibrated_data='./calibration_data',
nodes_list=['317_HzCalibration', # 激活节点
'471_HzCalibration', # 权重节点
'Conv_2']) # 普通节点
node_output:
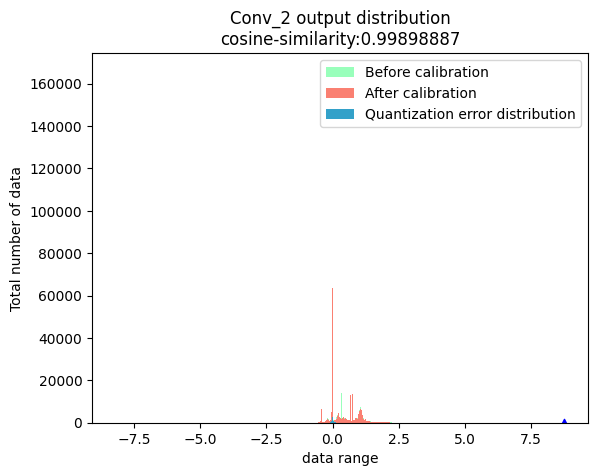
weight:
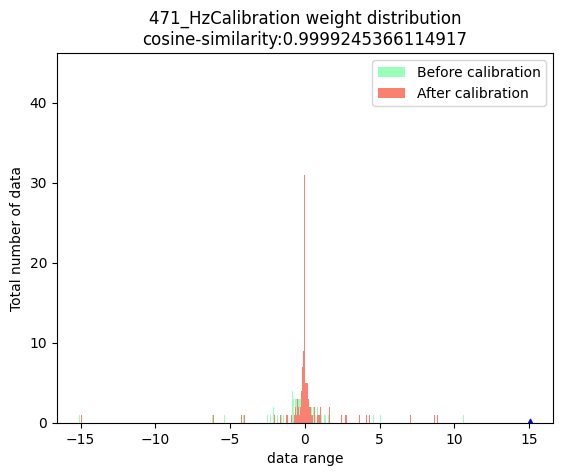
activation:
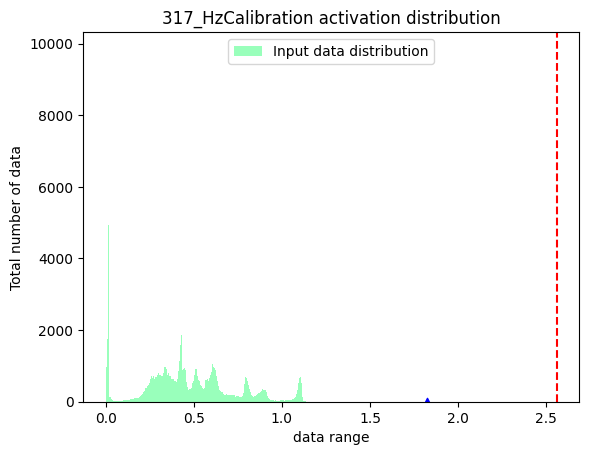
注解
上方三幅图中,蓝色三角表示:数据绝对值的最大值。红色虚线表示:最小的校准阈值。
4.1.2.11.2.4. get_channelwise_data_distribution¶
功能:绘制指定校准节点输入数据通道间数据分布的箱线图。
API参数组:
编 号 |
参数名称 |
参数配置说明 |
可选/ 必选 |
|---|---|---|---|
1 |
|
参数作用:保存路径。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析结果的保存路径。 |
必选 |
2 |
|
参数作用:指定校准模型。 取值范围:无。 默认配置:无。 参数说明:必选,指定需要分析的校准模型。 |
必选 |
3 |
|
参数作用:指定校准数据。 取值范围:无。 默认配置:无。 参数说明:必选,指定分析所需要的校准数据。 |
必选 |
4 |
|
参数作用:指定校准节点。 取值范围:校准模型中的所有权重校准节点和激活校准节点。 默认配置:无。 参数说明:必选,指定校准节点。 |
必选 |
5 |
|
参数作用:指定channel所在的维度。 取值范围:小于节点输入数据的维度。 默认配置:None。 参数说明:channel信息所在shape中的位置。 参数默认为None,此时对于激活校准节点, 默认认为节点输入数据的第二个维度表示channel信息,即axis=1; 对于权重校准节点,会读取该节点属性中的axis参数作为channel信息。 |
可选 |
# 导入debug模块
import horizon_nn.debug as dbg
dbg.get_channelwise_data_distribution(
save_dir: str,
model_or_file: ModelProto or str,
calibrated_data: str or CalibrationDataSet,
nodes_list: List[str],
axis: int = None)
API分析结果展示:
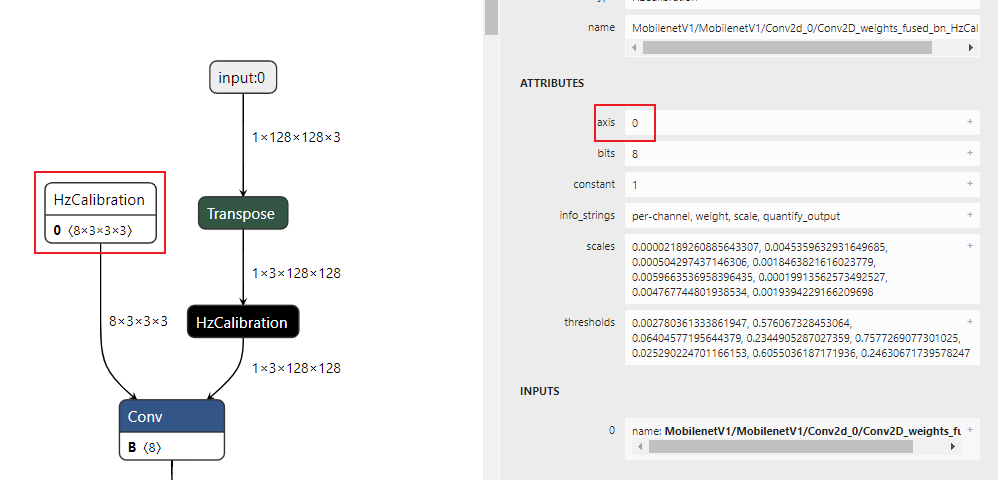
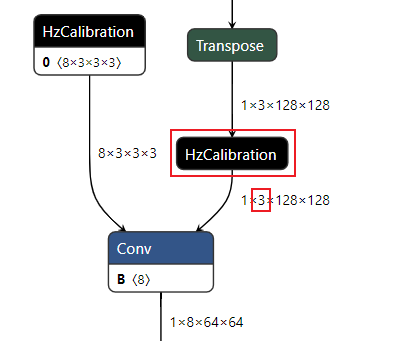
描述:针对用户设置的校准节点列表node_list,从参数axis中获取channel所在的维度,获取节点输入数据通道间的数据分布。 其中axis默认为None,此时若节点为权重校准节点,则channel所在的维度默认为0;若节点为激活校准节点,则channel所在的维度默认为1。
权重校准节点:
激活校准节点:
输出结果如下图所示:

图中:
横坐标表示节点输入数据的通道数,图例中输入数据有96个通道。
纵坐标表示每个channel的数据分布范围,其中红色实线表示该channel数据的中位数,蓝色虚线表示均值。