10.2. DSP Development Documentation¶
10.2.1. DSP Introduction¶
The Horizon J5 computing platform contains two DSP cores clocked at 648MHz and uses the Cadence’s Tensilica Vision P6 DSP IP. The Vision P6 DSP is dedicated to supporting algorithms such as computer vision or image processing. Very Long Instruction Word (VLIW) and Single Instruction Multiple Data Stream (SIMD) can greatly increase the speed of computation. Vision P6 DSP adopts 5-way VLIW architecture. Each instruction can contain two 64-byte loads or one 64-byte load and one 64-byte store at most. SIMD supports 512bit operations, such as 64-way 8-bit integer, 32-way 16-bit integer, etc. For more information about the Vision P6 DSP, see Cadence’s Vision P6 User Guide.
DSP boasts powerful computing power, and when used properly, deploying some computations that cannot be accelerated with BPU and are inefficient with ARM to DSP can greatly improve the inference performance of the model.
10.2.2. Linux Development Environment Installation¶
10.2.2.1. Development Tool Introduction¶
Xtensa Xplorer is an integrated development environment provided by Cadence for customers to develop software for their DSPs, which provides such functions as software development, compilation, debugging, simulation, profiling, hardware trace, etc. This section introduces only the installation of the Linux development environment. The installation and use of the Windows development environment can be found in the official documentation provided by Cadence.
10.2.2.2. Install DSP Toolchain And Configure Core¶
You can get the DSP development package from Horizon Robotics, which contains the Xplorer-9.0.17-linux-x64-installer.bin and the vdsp_vp6_RI4_linux.tgz installer.
Install Xtensa Develop Tools
By default, install Xtensa Develop Tools in the /opt/xtensa directory, but you can specify another directory as required. If you install it in the /opt/xtensa directory, a root permission is required. Execute the following command:
chmod 777 Xplorer-9.0.17-linux-x64-installer.bin
./Xplorer-9.0.17-linux-x64-installer.bin \
--mode unattended \
--prefix /opt/xtensa
Install VP6 Core Configuration
Unzip and extract the vdsp_vp6_RI4_linux.tgz installation package, put it in the specified location under the Xtensa Develop Tools installation directory (e.g., /opt/xtensa/XtDevTools/install/builds/RI-2021.7-linux/ ), and then install it. You need to execute the following command:
tar -zxvf vdsp_builds/vdsp_vp6_RI4_linux.tgz \
&& mv RI-2021.7-linux/vdsp_vp6_RI4/ /opt/xtensa/XtDevTools/install/builds/RI-2021.7-linux/ \
&& rm -rf RI-2021.7-linux
/opt/xtensa/XtDevTools/install/builds/RI-2021.7-linux/vdsp_vp6_RI4/install \
--xtensa-tools /opt/xtensa/XtDevTools/install/tools/RI-2021.7-linux/XtensaTools/
Configure environment variables
In order to ensure that Xtensa Develop Tools can be used properly, you need to set the following environment variables:
# set license server
export LM_LICENSE_FILE=port@serverip
# set default core
export XTENSA_CORE=vdsp_vp6_RI4
export XTENSA_ROOT=/opt/xtensa/XtDevTools/install/tools/RI-2021.7-linux/XtensaTools/
export PATH=$PATH:$XTENSA_ROOT/bin
Note
The license should be set correctly before you use Xtensa Develop Tools, please contact your Horizon project contact person for application and configuration.
Xtensa Develop Tools testing
Execute the following two commands. If these two commands can be executed normally, the linux development environment is successfully installed.
xt-clang --help # cross compiler
xt-run --help # simulator
10.2.2.3. DSP Development Reference Materials¶
For better DSP development, we recommend that you refer to the following documents,
After the compiler has been installed successfully, the core development documents can be found in the paths XtDevTools/downloads/RI-2021.7/docs and XtDevTools/install/builds/RI-2021.7-linux/vdsp_vp6_RI4/html/ISA, some supporting examples and libraries need to be downloaded through an XPG (Xtensa Processor Generator) account:
NO. |
Document Name and Description |
Document catalog |
|---|---|---|
1 |
VP6 DSP introduction document |
visionp6_ug.pdf |
2 |
Dev Toolkit introduction document |
sw_dev_toolkit_ug.pdf |
3 |
Compiler introduction document |
xtensa_xt_clang_compiler_ug.pdf |
4 |
Profiler document |
gnu_profiler_ug.pdf |
5 |
SwP_VisionP6_5.1.0 example description document |
SW_Package_VisionP6_UserGuide.pdf(XPG Download) |
6 |
Xi Library document, located in the XI_Library_7.14.2.xws project Doc directory |
XI_Library_UserGuide.pdf(XPG Download) |
7 |
TileManager document |
TileManager.pdf(XPG Download) |
8 |
VP6 DSP instruction |
NewISAhtml/index.html |
9 |
Horizon DSP Runtime API Manual |
10.2.3. Development Process¶
Some of the cv and nn operators have been packaged in the current sample library, and the list of operators can be found at here . In the Softmax operator example provided by Horizon Robotics, it is shown how to implement the DSP custom operator by scheduling the RPC framework and interface. RPC carries out the communication between ARM and DSP through rpmsg, and there is communication delay in RPC, refer to RPC mode .
You can get the sample source code at ddk/samples/vdsp_rpc_sample/ in the OE package for reading and understanding.
10.2.3.1. Overall Framework¶
The framework diagram of the model infer on the DSP is shown in the following figure:
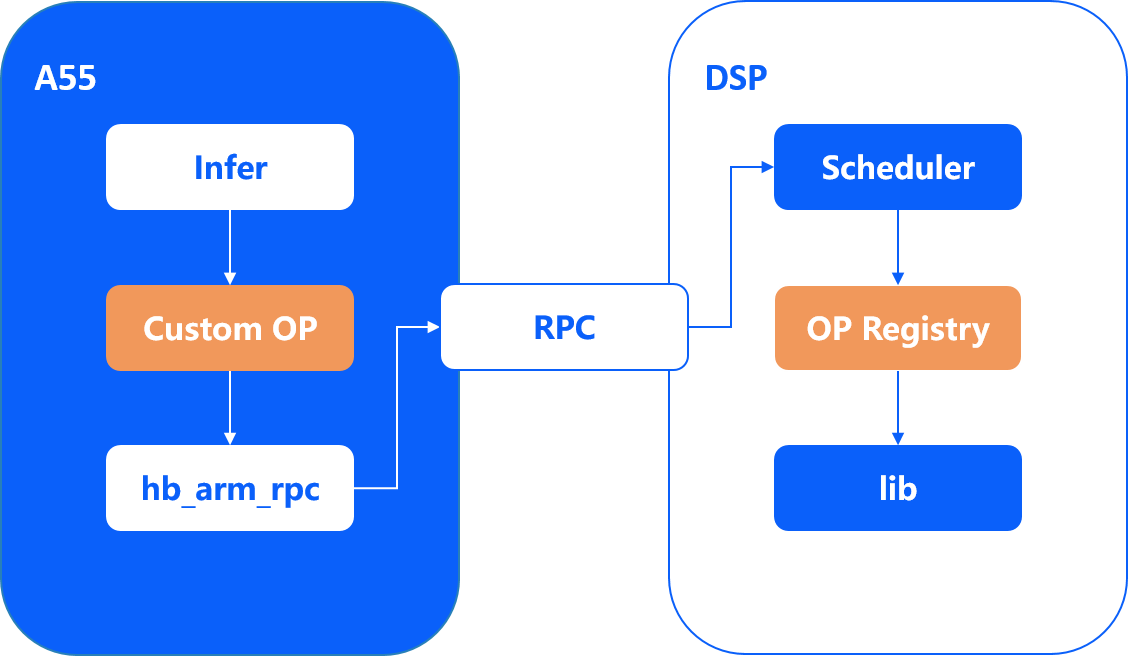
DSP and ARM are two relatively independent systems, and the two interact via RPC. To simplify the use of RPC, Horizon Robotics provides you with the corresponding interface. For more details, please read DSP Runtime API Manual .
The ARM side is mainly responsible for the allocation of computational resources and the initiation and recovery of DSP tasks. The DSP side is mainly responsible for executing the calculation logic, completing the calculation tasks assigned by the ARM side one by one according to the scheduling logic, and returning the calculation results. The execution process is as follows:
1.Implementing a custom operator on the DSP side, registering the op and starting the DSP mirror;
2.Implementation of the inference class for the user-defined operator on the ARM side;
3.Initialization of inference resources on the ARM side in preparation for model inference;
4.Preparation of the resources needed for DSP scheduling on the ARM side, and encapsulate the parameters that need to be passed to DSP, then initiation of RPC call tasks via user-defined operators;
5.DSP schedule receives the RPC message and executes the registered DSP op for operation according to the scheduling priority order;
6.After the DSP calculation, the results are returned to the ARM side via RPC;
7.The ARM side receives the op result returned by the DSP and continues to execute the subsequent logic according to the return value.
In the whole process, the user needs to ensure the correctness of the ARM-side operator call interface and DSP-side operator execution. This architecture and process only show the overall framework and execution logic of the operator, please refer to the subsequent paragraphs of Softmax operator development for specific implementation details.
10.2.3.2. ARM Softmax Operator Development¶
This section shows how to implement the ARM-side development of the custom operator Softmax, it corresponds to the vdsp_rpc_sample/arm/nn/src/custom_dsp_softmax.cc section in the horizon dsp sample.
DSP calls during model inference are implemented by implementing the DSPSoftmax inference class, where the Forward function implements the function of calling the RPC API to submit tasks to the DSP and obtaining the return value of the DSP.
In the sample, we customize the DSP Softmax operator and re-register it so that the model calls the customized operator when reasoning about the Softmax operator.
DSPSoftmax::Forward implements the following commands:
typedef struct {
int data_size; // input data size
uint64_t input; // input data physical address
// other parameters
} hbDSPSoftmaxParam;
int32_t DSPSoftmax::Forward(const std::vector<NDArray *> &bottomBlobs,
std::vector<NDArray *> &topBlobs,
const hbDNNInferCtrlParam *inferCtrlParam) {
const NDArray *data = bottomBlobs[0];
NDArray *out = topBlobs[0];
const uint32_t axis = data->CanonicalAxis(axis_);
uint32_t N = 1U;
for (uint32_t index = 0U; index < axis; ++index) {
N *= data->Shape()[index];
}
uint32_t D = data->Size() / N;
TShape s2 = TShape{N, D};
auto data_tmp = data->Reshape(s2);
auto out_tmp = out->Reshape(s2);
hbSysMem input_mem, output_mem, hb_in_mem;
int data_size = D * sizeof(float);
int ret = hbSysAllocMem(&input_mem, data_size);
if (ret != 0) {
std::cout << "hbSysAllocMem input fail\n";
return -1;
}
ret = hbSysAllocMem(&output_mem, data_size);
if (ret != 0) {
std::cout << "hbSysAllocMem output fail\n";
return -1;
}
ret = hbSysAllocMem(&hb_in_mem, sizeof(hbDSPSoftmaxParam));
if (ret != 0) {
std::cout << "hbSysAllocMem hb_in_mem fail\n";
return -1;
}
hbDSPRpcCtrlParam param;
param.rpcCmd = HB_DSP_RPC_CMD_NN_SOFTMAX;
param.priority = 0;
param.dspCoreId = 0;
for (uint32_t i = 0U; i < out_tmp.Shape()[0U]; ++i) {
memcpy(input_mem.virAddr, data_tmp[i].RawData(), data_size);
hbDSPSoftmaxParam *ptr = (hbDSPSoftmaxParam *)(hb_in_mem.virAddr);
ptr->data_size = data_size;
ptr->input = input_mem.phyAddr;
hbDSPTask_t task;
ret = hbDSPRpc(&task, &hb_in_mem, &output_mem, ¶m);
if (ret != 0) {
std::cout << "hbDSPRpc fail: " << ret << "\n";
return -1;
}
ret = hbDSPWaitTaskDone(task, 0);
if (ret != 0) {
std::cout << "hbDSPWaitTaskDone fail: " << ret << "\n";
return -1;
}
ret = hbDSPReleaseTask(task);
if (ret != 0) {
std::cout << "hbDSPReleaseTask fail: " << ret << "\n";
return -1;
}
memcpy(out_tmp[i].RawData(), output_mem.virAddr, data_size);
hbSysFreeMem(&input_mem);
hbSysFreeMem(&output_mem);
hbSysFreeMem(&hb_in_mem);
}
return 0;
}
In hbDSPRpcCtrlParam.rpcCmd = HB_DSP_RPC_CMD_NN_SOFTMAX, HB_DSP_RPC_CMD_NN_SOFTMAX is the number of the Softmax operator on the
DSP ( For more details on the registration process of the DSP Softmax operator numbers,
refer to Horizon Toolchain Actually Tests DSP Performance ).
Note
After designing the DSP Softmax customized operator, use the hbDNNRegisterLayerCreator interface to register and replace the original Softmax operator.
Due to the limitation of the hbDSPRpc interface parameters (only the input and output data address parameters are transmitted), to directly call the hbDSPRpc interface to access the custom DSP operator, it is necessary to encapsulate the DSP operator (input and output) parameters and pass them to the DSP end. For example: softmax needs the input and output data address and data size, so the input data address and data size are packaged as hbDSPSoftmaxParam and passed to the hbDSPRpc interface.
10.2.3.3. DSP Softmax Operator Development¶
This section introduces the process of DSP operator development by taking the DSP Softmax operator development as an example,
it corresponds to the vdsp_rpc_sample/dsp/src/softmax_ivp.cc part of the horizon dsp sample.
10.2.3.3.1. Softmax Analysis¶
The Softmax operator can be split into the following four base calculations:
1.Calculate the maximum value in the input element: max.
2.Calculate and update each element of the input: input = exp(input - max) ;
3.Calculate the sum of the updated inputs: sum.
4.Calculate output = input / sum .
10.2.3.3.2. DSP Softmax Implementation¶
This section will introduce how to implement the four basic operations mentioned in the previous section and thus implement the DSP Softmax operator.
Cadence implements some basic math operations to facilitate user development. You can get the source code from Cadence’s basic examples, or you can get the compiled dependency library dsp_math directly from Horizon Robotics.
In order to take full advantage of hardware performance,, so developers need to understand DSP features and use them effectively (VLIW, SIMD). When developing, you can refer to Cadence’s own implementation of the basic operations.
Step 1: Implement the vecmaxf command as follows:
/**
* DSP find max value
* @param[in] x: input
* @param[in] N: length
* @return maximum value
*/
float32_t vecmaxf(const float32_t *x, int N) {
const xb_vecN_2xf32 *restrict px;
valign al_px;
xb_vecN_2xf32 vecmax0, vecmax1, vecx0, vecx1;
vboolN_2 b_max0, b_max1;
int n, N_tail, Nb_tail;
float32_t max;
// ASSERT( x );
if (N <= 0) return 0.f;
px = (const xb_vecN_2xf32 *)x;
al_px = IVP_LAN_2XF32_PP(px);
vecmax0 = vecmax1 = minus_inff_.f;
/* Main loop: process by 2*IVP_N_2 values per iteration */
for (n = 0; n<N>> (4 + 1); n++) {
IVP_LAN_2XF32_IP(vecx0, al_px, px);
IVP_LAN_2XF32_IP(vecx1, al_px, px);
vecmax0 = IVP_MAXN_2XF32(vecx0, vecmax0);
vecmax1 = IVP_MAXN_2XF32(vecx1, vecmax1);
}
/* Process last N%(2*IVP_N_2) values */
N_tail = N & (2 * IVP_N_2 - 1);
Nb_tail = N_tail * sizeof(float32_t);
b_max0 = IVP_LTRSN_2(N_tail);
b_max1 = IVP_LTRSN_2(N_tail - IVP_N_2);
IVP_LAVN_2XF32_XP(vecx0, al_px, px, Nb_tail);
IVP_LAVN_2XF32_XP(vecx1, al_px, px, Nb_tail - IVP_N_2 * sizeof(float32_t));
IVP_MAXN_2XF32T(vecmax0, vecx0, vecmax0, b_max0);
IVP_MAXN_2XF32T(vecmax1, vecx1, vecmax1, b_max1);
/* Reduce maximium values from vectors to the scalar one */
vecmax0 = IVP_MAXN_2XF32(vecmax0, vecmax1);
vecmax1 = IVP_SELN_2XF32I(vecmax0, vecmax0, IVP_SELI_32B_ROTATE_RIGHT_8);
vecmax0 = IVP_MAXN_2XF32(vecmax0, vecmax1);
vecmax1 = IVP_SELN_2XF32I(vecmax0, vecmax0, IVP_SELI_32B_ROTATE_RIGHT_4);
vecmax0 = IVP_MAXN_2XF32(vecmax0, vecmax1);
vecmax1 = IVP_SELN_2XF32I(vecmax0, vecmax0, IVP_SELI_32B_ROTATE_RIGHT_2);
vecmax0 = IVP_MAXN_2XF32(vecmax0, vecmax1);
vecmax1 = IVP_SELN_2XF32I(vecmax0, vecmax0, IVP_SELI_32B_ROTATE_RIGHT_1);
vecmax0 = IVP_MAXN_2XF32(vecmax0, vecmax1);
max = IVP_MOVF32_FROMN_2XF32(vecmax0);
return max;
} /* vecmaxf() */
Step 2: Implement the vecexpf_max command as follows:
/**
* DSP Vectorized Floating-Point Exponential
* The exponential (or anti-logarithm) function computes the exponential
* value e to the power of input vector x[N], and stores the result to output
* vector z[N].
* @param[out] z: output
* @param[in] x: input
* @param[in] N: length
* @param[in] max_value: max_value
* @return maximum value
*/
void vecexpf_max(float32_t *z, const float32_t *x, int N, float32_t max_value) {
const xb_vecN_2xf32 *restrict pX = (const xb_vecN_2xf32 *)x;
xb_vecN_2xf32 *restrict pZ = (xb_vecN_2xf32 *)z;
xtfloat *restrict ptbl = (xtfloat *)expftblf;
// check correct
xb_vecN_2xf32 xmax = max_value;
xb_vecN_2xf32 xin, xin2, txin, zout;
xb_vecN_2xf32 p0, p1, p2, p3, p4, p5, p6;
xb_vecN_2xf32 scl1, scl2;
xb_vecN_2x32v t, exp_fract, exp_int, e1, e2;
xb_vecN_2x64w W;
xb_vecNx16 invln2;
valign xa, za;
vboolN_2 b_nan, b_max, b_inf;
#if EXPF_ERRH != 0
vboolN_2 b_edom, b_erange;
xb_int32v SCF; /* Floating-point Status and Control Register values. */
#endif
int n;
/* common argument checks */
// NASSERT(x);
// NASSERT(z);
if (N <= 0) return;
/* load 1/ln(2) constant in Q30 */
invln2 = IVP_MOVNX16_FROMN_2X32(IVP_LSN_2X32_I((const int *)&invln2_Q30, 0));
za = IVP_ZALIGN();
xa = IVP_LAN_2XF32_PP(pX);
for (n = 0; n<(N + IVP_N_2 - 1)>> 4; n++) {
IVP_LAVN_2XF32_XP(xin, xa, pX, (uint8_t *)x + N * 4 - (uint8_t *)pX);
txin = xin;
/* Check input for values that are out of domain/range */
b_nan = IVP_UNN_2XF32(xin, xin); /* x==NaN */
b_max = IVP_ULEN_2XF32(expfminmax[1].f, xin); /* x>=88.72284 or x==NaN */
b_inf = IVP_UEQN_2XF32(xin, plus_inff.f); /* x==+Inf or x==NaN */
/* Limit input values to [-128;+127] and replace NaNs *
* with some numbers to avoid unnecessary exceptions */
xin = IVP_SUBN_2XF32(xin, xmax);
xin = IVP_MOVN_2XF32T(127.0f, xin, b_max);
xin = IVP_MAXN_2XF32(xin, -128.0f);
/* Convert the input to Q24 and scale to 1/ln(2) */
t = IVP_TRUNCN_2XF32(xin, 24);
W = IVP_MULN_2X16X32_0(invln2, t);
IVP_MULAHN_2X16X32_1(W, invln2, t); /* Q24*Q30->Q54 */
/* Separate input to positive fractional part and integer part */
exp_fract = IVP_PACKVRNRN_2X64W(W, 22); /* Q54->Q32 */
exp_fract = IVP_SRLIN_2X32U(exp_fract, 1); /* Q32->Q31 */
exp_int = IVP_PACKHN_2X64W(W); /* Q54->Q22 */
exp_int = IVP_SRLIN_2X32(exp_int, 22); /* Q22->Q0 */
/* compute 2^fract in floating-point format */
xin =
IVP_FLOATN_2X32(exp_fract, 31); /* scale fraction part by 2^-31 with */
/* conversion from int32 to float */
/* Pass input to the output if x==+INF or x==NaN */
xin = IVP_MOVN_2XF32T(txin, xin, b_inf);
/* load polynomial coefficients */
IVP_LSRN_2XF32_IP(p0, ptbl, sizeof(float32_t));
IVP_LSRN_2XF32_IP(p1, ptbl, sizeof(float32_t));
IVP_LSRN_2XF32_IP(p2, ptbl, sizeof(float32_t));
IVP_LSRN_2XF32_IP(p3, ptbl, sizeof(float32_t));
IVP_LSRN_2XF32_IP(p4, ptbl, sizeof(float32_t));
IVP_LSRN_2XF32_IP(p5, ptbl, sizeof(float32_t));
IVP_LSRN_2XF32_XP(p6, ptbl, -6 * (int)sizeof(float32_t));
/* compute polynomial using combination *
* of Estrin`s and Horner schemes */
xin2 = IVP_MULN_2XF32(xin, xin);
IVP_MULAN_2XF32(p1, xin, p0);
IVP_MULAN_2XF32(p3, xin, p2);
IVP_MULAN_2XF32(p5, xin, p4);
IVP_MULAN_2XF32(p3, xin2, p1);
IVP_MULAN_2XF32(p5, xin2, p3);
IVP_MULAN_2XF32(p6, xin, p5);
/* Apply integer exponential part to the result */
exp_int = IVP_ADDN_2X32(exp_int, 254);
e1 = IVP_SRLIN_2X32(exp_int, 1);
e2 = IVP_SUBN_2X32(exp_int, e1);
e1 = IVP_SLLIN_2X32(e1, 23);
e2 = IVP_SLLIN_2X32(e2, 23);
scl1 = IVP_MOVN_2XF32_FROMN_2X32(e1);
scl2 = IVP_MOVN_2XF32_FROMN_2X32(e2);
zout = IVP_MULN_2XF32(p6, scl1);
zout = IVP_MULN_2XF32(zout, scl2);
IVP_SAVN_2XF32_XP(zout, za, pZ, (uint8_t *)z + N * 4 - (uint8_t *)pZ);
}
IVP_SAPOSN_2XF32_FP(za, pZ);
} /* vecexpf() */
Step 3: Implement the vecsum command as follows:
/**
* DSP Vectorized sum value
* @param[in] x: input
* @param[in] N: length
* @return sum of x[N] value
*/
static float32_t vecsum(const float32_t *x, int N) {
const xb_vecN_2xf32 *restrict px;
valign al_px;
xb_vecN_2xf32 vecsum0, vecsum1, vecx0, vecx1;
vboolN_2 b_sum0, b_sum1;
int n, N_tail, Nb_tail;
float32_t sum;
// ASSERT(x);
if (N <= 0) return 0.f;
px = (const xb_vecN_2xf32 *)x;
al_px = IVP_LAN_2XF32_PP(px);
vecsum0 = vecsum1 = 0.f;
for (n = 0; n<N>> 5; n++) {
IVP_LAN_2XF32_IP(vecx0, al_px, px);
IVP_LAN_2XF32_IP(vecx1, al_px, px);
vecsum0 = IVP_ADDN_2XF32(vecx0, vecsum0);
vecsum1 = IVP_ADDN_2XF32(vecx1, vecsum1);
}
N_tail = N & (2 * IVP_N_2 - 1);
Nb_tail = N_tail * sizeof(float32_t);
b_sum0 = IVP_LTRSN_2(N_tail);
b_sum1 = IVP_LTRSN_2(N_tail - IVP_N_2);
IVP_LAVN_2XF32_XP(vecx0, al_px, px, Nb_tail);
IVP_LAVN_2XF32_XP(vecx1, al_px, px, Nb_tail - IVP_N_2 * sizeof(float32_t));
IVP_ADDN_2XF32T(vecsum0, vecx0, vecsum0, b_sum0);
IVP_ADDN_2XF32T(vecsum1, vecx1, vecsum1, b_sum1);
vecsum0 = IVP_ADDN_2XF32(vecsum0, vecsum1);
sum = IVP_RADDN_2XF32(vecsum0);
return sum;
}
Step 4: The division operation can be changed into multiplication operation, and it is easier to implement multiplication operation with better performance. The vecmul instruction is implemented as follows:
/**
* DSP Vectorized sum value
* @param[in] x: input
* @param[in] N: length
* @return sum of x[N] value
*/
static float32_t vecsum(const float32_t *x, int N) {
const xb_vecN_2xf32 *restrict px;
valign al_px;
xb_vecN_2xf32 vecsum0, vecsum1, vecx0, vecx1;
vboolN_2 b_sum0, b_sum1;
int n, N_tail, Nb_tail;
float32_t sum;
// ASSERT(x);
if (N <= 0) return 0.f;
px = (const xb_vecN_2xf32 *)x;
al_px = IVP_LAN_2XF32_PP(px);
vecsum0 = vecsum1 = 0.f;
for (n = 0; n<N>> 5; n++) {
IVP_LAN_2XF32_IP(vecx0, al_px, px);
IVP_LAN_2XF32_IP(vecx1, al_px, px);
vecsum0 = IVP_ADDN_2XF32(vecx0, vecsum0);
vecsum1 = IVP_ADDN_2XF32(vecx1, vecsum1);
}
N_tail = N & (2 * IVP_N_2 - 1);
Nb_tail = N_tail * sizeof(float32_t);
b_sum0 = IVP_LTRSN_2(N_tail);
b_sum1 = IVP_LTRSN_2(N_tail - IVP_N_2);
IVP_LAVN_2XF32_XP(vecx0, al_px, px, Nb_tail);
IVP_LAVN_2XF32_XP(vecx1, al_px, px, Nb_tail - IVP_N_2 * sizeof(float32_t));
IVP_ADDN_2XF32T(vecsum0, vecx0, vecsum0, b_sum0);
IVP_ADDN_2XF32T(vecsum1, vecx1, vecsum1, b_sum1);
vecsum0 = IVP_ADDN_2XF32(vecsum0, vecsum1);
sum = IVP_RADDN_2XF32(vecsum0);
return sum;
}
So far, the DSP Softmax operator hb_dsp_softmax can be implemented.
10.2.3.3.3. DSP Operator Performance Analysis and Optimization¶
Before performing DSP operator performance analysis and optimization, you need to clearly know the following points:
1.The two DRAMs of DSP (DRAM0 and DRAM1) are TCM memory. The data stored in TCM can be read faster, therefore, the operators-related data and codes should be stored in TCM for calculation.
2.The input and output memory of the operator is on DDR, and the data can be carried between DDR and TCM through DMA, and DMA requires time for transferring, therefore, PINGPONG DMA is commonly used to reduce the waiting time due to data carrying.
3.LSP: Link Support Package. The memory address of each segment can be seen in the memmap.xmm file, and the location of code and data in memory can be changed either by changing the LSP or by resetting the segment information for dependent libraries and target files. For more information, see the Xtensa Linker Support Packages (LSPs) Reference Manual (lsp_rm.pdf).
4.Printf will be very time-consuming, so please put the printf in the right place when calculating performance.
DSP operator performance can be analyzed and optimized in three parts:
1.DSP SIM: The DSP toolchain provides a simulation function to obtain the clock cycles of the operator running and thus estimate the actual running time. Developers can prioritize the SIM information to see if the operator performance meets the requirements and if further optimization of the operator is needed.
2.Use the Horizon DSP toolchain on board to realistically test the performance.
3.Use PINGPONG DMA to complete the big data handling.
10.2.3.3.4. DSP SIM¶
In the <xtensa/tie/xt_timer.h> header file, we provide the XT_RSR_CCOUNT() function to get the current cycle count, so that the difference can be used to get the clock cycle for the running of the operator. The clock period cycle*1.5 gives an estimate of the time (ns) that the operator needs to run.
The sample code is as follows:
#define HB_ALIGN(x) __attribute__((aligned(x)))
#define HB_ALIGN64 HB_ALIGN(64)
#define _HB_LOCAL_DRAM0_ __attribute__((section(".dram0.data")))
#define _HB_LOCAL_DRAM1_ __attribute__((section(".dram1.data")))
#define _HB_LOCAL_IRAM_ __attribute__((section(".iram0.text")))
#define HB_DSP_TIME_STAMP(cyc_cnt) (cyc_cnt) = XT_RSR_CCOUNT()
#define KB(n) (n << 10)
#define INPUT_N KB(8)
float HB_ALIGN64 data_ivp[INPUT_N] _HB_LOCAL_DRAM0_;
float HB_ALIGN64 output_ivp[INPUT_N] _HB_LOCAL_DRAM0_;
static int dsp_softmax(float *input, int length, float *output) {
float max_value = vecmaxf(input, length);
vecexpf_max(output, input, length, max_value);
float sum = vecsum(output, length);
int i = 0;
float div = 1 / sum;
vecmul(output, output, div, length);
return 0;
}
int main() {
uint32_t start, end;
float* input = (float*)data_ivp;
float* output = (float*)output_ivp;
int size = KB(1);
for(int i = 0; i < 4; i++){
HB_DSP_TIME_STAMP(start);
dsp_softmax(input, size, output);
HB_DSP_TIME_STAMP(end);
uint32_t diff = end - start;
printf("*******Test for softmax, data size: %d, DSP cycle count: %d, nanosecond:%f\n",
size, diff, diff * 1.5);
size *= 2;
}
return 0;
}
Therein, dsp_softmax is the Softmax operator implemented on the DSP.
In the above example, you need to try to ensure that all the computed data is in the TCM to improve the performance.
Note
The input and output are directly applied in TCM (DRAM). Due to the limited size of DRAM memory, only the performance of small data volume can be tested. If you need to test large data volume, please use the DMA for data handling.
The implementation of the operator may use some global or local variables. To further improve the performance of the operator, the LSPs need to be modified by placing the
.rodata,.data,.bssfields and STACK on DRAM. The modification to the LSP may result in memory shortage. In this case, you cannot modify the LSP directly, and you need to modify the location of the corresponding object file segment. See the Xtensa Linker Support Packages (LSPs) Reference Manual (lsp_rm.pdf) for details.
10.2.3.3.5. Horizon Toolchain Actually Tests DSP Performance¶
Horizon provides a DSP toolchain to facilitate the registration of implemented operators into the DSP scheduling system. For details, see DSP Runtime API Manual .
DSPmain function implements the following command:
#include <stdio.h>
#include <sys/time.h>
#include <xtensa/xos.h>
#include "cv/core.h"
#include "hb_dsp.h"
#include "hb_dsp_log.h"
#include "hb_dsp_tm.h"
#include "nn/core.h"
#include "src/softmax_ivp.h"
#define DSP_FREQ (648000000)
#define TICK_CYCLES (xos_get_clock_freq() / 100)
uint8_t HB_ALIGN64 dram0_pool[HB_DSP_DRAM0_POOL_SIZE] _HB_LOCAL_DRAM0_;
uint8_t HB_ALIGN64 dram1_pool[HB_DSP_DRAM1_POOL_SIZE] _HB_LOCAL_DRAM1_;
int main() {
{
int32_t ret;
printf("--------DSP WELCOME START---------\n");
// Set clock frequency before calling xos_start().
xos_set_clock_freq(DSP_FREQ);
// use timer0 as systemtimer; 10ms a tick;
xos_start_system_timer(0, TICK_CYCLES);
}
// set log level
hb_dsp_set_log_level(HB_DSP_LOG_ERROR);
// env init
hb_dsp_env_init();
// init tile manager, optional
hb_dsp_init_global_tm(
dram0_pool, HB_DSP_DRAM0_POOL_SIZE, dram1_pool, HB_DSP_DRAM1_POOL_SIZE);
// start dsp shedule
HB_DSP_REGISTER_NN_ALL;
HB_DSP_REGISTER_CV_ALL;
hb_dsp_register_fn(0x400, hb_dsp_softmax, 0);
hb_dsp_start();
// Should never get here
return -1;
}
You only need to care about the hb_dsp_register_fn part, the rest are template data and cannot be changed.
0x400 is the number of the Softmax operator on the DSP.
hb_dsp_softmax is the operator execution portal. The sample code is as follows (The OPT part of the macro definition is optimized for Pingpong to transfer memory to TCM):
#define OPT
#define PROF
int hb_dsp_softmax(void *input, void *output, void *tm) {
hbDSPSoftmaxParam *ptr = (hbDSPSoftmaxParam *)(input);
float *src = (float *)hb_dsp_mem_map(ptr->input, ptr->data_size);
PRT_IF_COND_RETURN(MAP_FAILED == src, HB_ERR_MMAP_FAILED)
float *dst = (float *)(output);
#ifdef OPT
xvTileManager *tm_ = (xvTileManager *)tm;
float *src_0 =
(float *)(xvAllocateBuffer(tm_, TILE_SIZE, XV_MEM_BANK_COLOR_0, 64));
float *dst_0 = src_0;
float *src_1 =
(float *)(xvAllocateBuffer(tm_, TILE_SIZE, XV_MEM_BANK_COLOR_1, 64));
float *dst_1 = src_1;
void *src_idma[] = {src_0, src_1};
void *dst_idma[] = {dst_0, dst_1};
int length = ptr->data_size >> 2;
#ifdef PROF
TIME_STAMP(cyclesStart);
#endif
// find max
float max_value = 0.f;
hb_dsp_ping_pong_frame(
dst, src, src_idma, dst_idma, length, tile_max, &max_value, 0, false);
// exp & sum
float sum_value = 0.f;
hb_dsp_ping_pong_frame(dst,
src,
src_idma,
dst_idma,
length,
tile_sum,
&sum_value,
max_value,
true);
// mul
hb_dsp_ping_pong_frame(
dst, dst, src_idma, dst_idma, length, tile_mul, 0, sum_value, true);
xvFreeBuffer(tm_, (void *)src_0);
xvFreeBuffer(tm_, (void *)src_1);
#ifdef PROF
TIME_STAMP(cyclesStop);
selfCycles = cyclesStop - cyclesStart;
printf("find softmax ping-pong tcm is %d cycles\n", selfCycles);
#endif
#else
#ifdef PROF
TIME_STAMP(cyclesStart);
#endif
int N = ptr->data_size >> 2;
int ret = dsp_softmax(src, N, dst);
if (ret != 0) {
printf("Run softmax op fail:%d\n", ret);
return ret;
}
#ifdef PROF
TIME_STAMP(cyclesStop);
selfCycles = cyclesStop - cyclesStart;
printf("find softmax ddr tcm is %d cycles\n", selfCycles);
#endif // PROF
#endif // OPT
hb_dsp_mem_unmap((uint32_t)src);
return 0;
}
The input and output virAddr stores the data in input_mem.virAddr passed in the hbDSPRpc function mentioned in ARM Softmax Operator Development , which is stored in the DDR. Since the direct use of input and output by the operator in the sample will result in a longer runtime, it is necessary to use the DMA function to carry the data to the TCM, and PINGPONG DMA is needed when the volume of the data is relatively large. TCM memory can be requested via tm.
10.2.3.3.6. PINGPONG DMA¶
In DMA data transfer, if there is only one buffer receiving data, then it is only a serial process like “DMA transfer -> process data -> DMA transfer -> process data”. If there are two buffers receiving data (one is called ping buffer and the other is called pong buffer), the pong buffer can be transferred by DMA while the ping buffer is being processed, ideally when the data of the pong buffer has been processed, the data of the pong buffer has been transferred by DMA . The ideal situation is that when the data of the ping buffer is processed, the data of the pong buffer has already been transferred via DMA.
Developers can read section 7 of the Xtensa System Software Reference Manual (sys_sw_rm.pdf) to learn about DMA and use the original interface to complete pingpong DMA.
For each calculation step of the Softmax example, the Pingpong operation can be used, so the hb_dsp_ping_pong_frame function is extracted, code is as follows:
/**
* DSP softmax ping-pong framework
* @param[out] dst: optional
* @param[in] src
* @param[in] length
* @param[in] func: framework tile compute func
* @param[out] func_out: func output param
* @param[in] func_in: func input param
* @param[in] with_out_idma: whether need to copy back output
* @return 0 if success, return defined error code otherwise
*/
int hb_dsp_ping_pong_frame(float *dst,
float *src,
void *src_idma[],
void *dst_idma[],
int length,
void (*func)(float *, float *, int, float *, float),
float *func_out,
float func_in,
bool with_out_idma = true) {
int size[] = {0, 0};
int vret_in[2];
int vret_out[2];
int i = 0;
int block_start = 0;
int output_start = 0;
int ping_pong = 0;
int block = XT_MIN(TILE_SIZE >> 2, length);
int block_size = block << 2;
size[0] = block;
float sum = 0.f;
IDMA_COPY(vret_in[0], src, src_idma[0], block_size)
if (vret_in[0] < 0) {
printf("copy task failed!\n");
}
block_start += block;
if (block_start < length) {
block = XT_MIN(block, length - block_start);
block_size = block << 2;
size[1] = block;
IDMA_COPY(vret_in[1], src + block_start, src_idma[1], block_size)
if (vret_in[1] < 0) {
printf("copy task failed!\n");
}
block_start += block;
}
while (i < length) {
i += size[ping_pong];
while (idma_desc_done(vret_in[ping_pong]) != 1) {
}
while (with_out_idma && idma_desc_done(vret_out[ping_pong]) != 1) {
}
func((float *)dst_idma[ping_pong],
(float *)src_idma[ping_pong],
size[ping_pong],
func_out,
func_in);
if (with_out_idma) {
IDMA_COPY(vret_out[ping_pong],
dst_idma[ping_pong],
dst + output_start,
size[ping_pong] << 2)
if (vret_out[ping_pong] < 0) {
printf("Fail to copy softmax output, status %d\n", vret_out[ping_pong]);
return -1;
}
output_start += size[ping_pong];
}
if (block_start < length) {
block = XT_MIN(block, length - block_start);
block_size = block << 2;
size[ping_pong] = block;
IDMA_COPY(vret_in[ping_pong],
src + block_start,
src_idma[ping_pong],
block_size)
if (vret_in[ping_pong] < 0) {
printf("copy task failed!\n");
}
block_start += block;
}
ping_pong ^= 0x1;
}
while (with_out_idma && idma_desc_done(vret_out[ping_pong ^ 0x01]) != 1) {
}
return 0;
}
10.2.3.4. Model running¶
You can refer to the Run NN Example section for related descriptions of the model running.